 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
Social Bias in Popular Question-Answering Benchmarks
May 21, 2025Question-answering (QA) and reading comprehension (RC) benchmarks are essential for assessing the capabilities of large language models (LLMs) in retrieving and reproducing knowledge. However, we demonstrate that popular QA and RC benchmarks are biased and do not cover questions about different demographics or regions in a representative way, potentially due to a lack of diversity of those involved in their creation. We perform a qualitative content analysis of 30 benchmark papers and a quantitative analysis of 20 respective benchmark datasets to learn (1) who is involved in the benchmark creation, (2) how social bias is addressed or prevented, and (3) whether the demographics of the creators and annotators correspond to particular biases in the content. Most analyzed benchmark papers provided insufficient information regarding the stakeholders involved in benchmark creation, particularly the annotators. Notably, just one of the benchmark papers explicitly reported measures taken to address social representation issues. Moreover, the data analysis revealed gender, religion, and geographic biases across a wide range of encyclopedic, commonsense, and scholarly benchmarks. More transparent and bias-aware QA and RC benchmark creation practices are needed to facilitate better scrutiny and incentivize the development of fairer LLMs.
Post-Training Language Models for Continual Relation Extraction
Apr 07, 2025
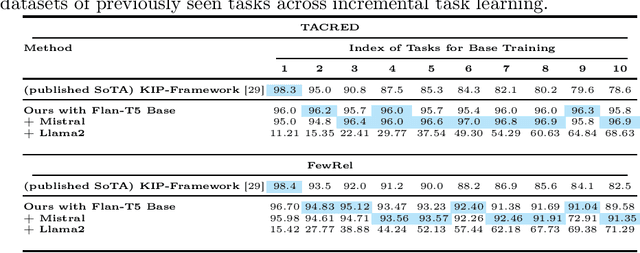

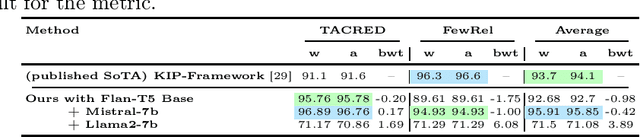
Real-world data, such as news articles, social media posts, and chatbot conversations, is inherently dynamic and non-stationary, presenting significant challenges for constructing real-time structured representations through knowledge graphs (KGs). Relation Extraction (RE), a fundamental component of KG creation, often struggles to adapt to evolving data when traditional models rely on static, outdated datasets. Continual Relation Extraction (CRE) methods tackle this issue by incrementally learning new relations while preserving previously acquired knowledge. This study investigates the application of pre-trained language models (PLMs), specifically large language models (LLMs), to CRE, with a focus on leveraging memory replay to address catastrophic forgetting. We evaluate decoder-only models (eg, Mistral-7B and Llama2-7B) and encoder-decoder models (eg, Flan-T5 Base) on the TACRED and FewRel datasets. Task-incremental fine-tuning of LLMs demonstrates superior performance over earlier approaches using encoder-only models like BERT on TACRED, excelling in seen-task accuracy and overall performance (measured by whole and average accuracy), particularly with the Mistral and Flan-T5 models. Results on FewRel are similarly promising, achieving second place in whole and average accuracy metrics. This work underscores critical factors in knowledge transfer, language model architecture, and KG completeness, advancing CRE with LLMs and memory replay for dynamic, real-time relation extraction.
NFDI4DSO: Towards a BFO Compliant Ontology for Data Science
Aug 16, 2024


The NFDI4DataScience (NFDI4DS) project aims to enhance the accessibility and interoperability of research data within Data Science (DS) and Artificial Intelligence (AI) by connecting digital artifacts and ensuring they adhere to FAIR (Findable, Accessible, Interoperable, and Reusable) principles. To this end, this poster introduces the NFDI4DS Ontology, which describes resources in DS and AI and models the structure of the NFDI4DS consortium. Built upon the NFDICore ontology and mapped to the Basic Formal Ontology (BFO), this ontology serves as the foundation for the NFDI4DS knowledge graph currently under development.
A Comprehensive Study on Dataset Distillation: Performance, Privacy, Robustness and Fairness
May 05, 2023
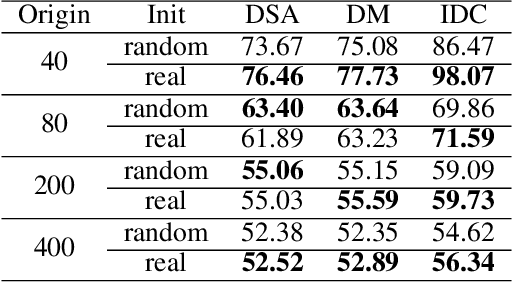
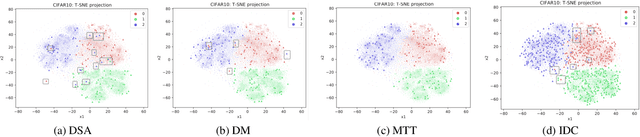
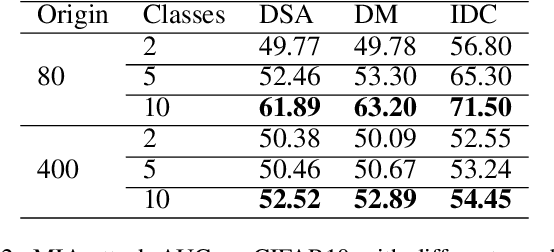
The aim of dataset distillation is to encode the rich features of an original dataset into a tiny dataset. It is a promising approach to accelerate neural network training and related studies. Different approaches have been proposed to improve the informativeness and generalization performance of distilled images. However, no work has comprehensively analyzed this technique from a security perspective and there is a lack of systematic understanding of potential risks. In this work, we conduct extensive experiments to evaluate current state-of-the-art dataset distillation methods. We successfully use membership inference attacks to show that privacy risks still remain. Our work also demonstrates that dataset distillation can cause varying degrees of impact on model robustness and amplify model unfairness across classes when making predictions. This work offers a large-scale benchmarking framework for dataset distillation evaluation.
A Survey on Dataset Distillation: Approaches, Applications and Future Directions
May 03, 2023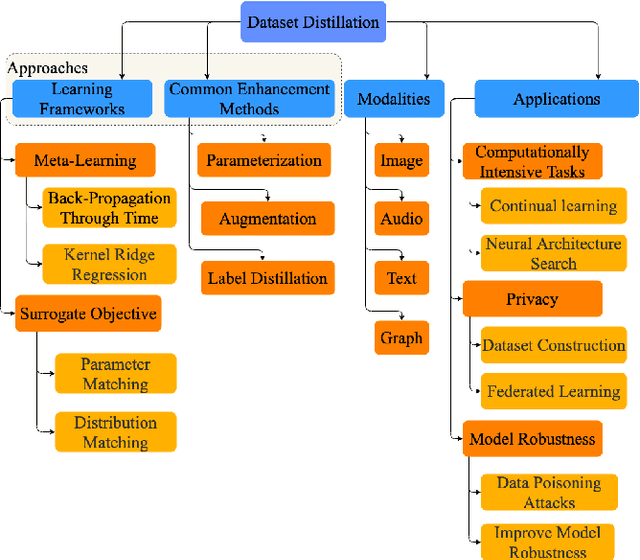
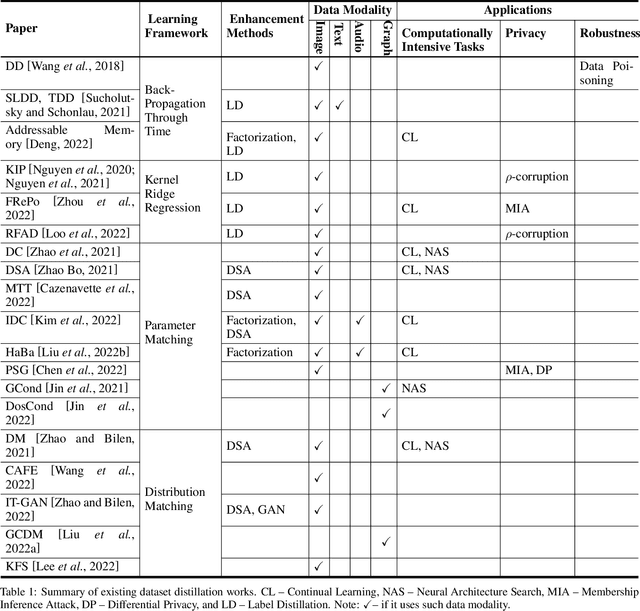
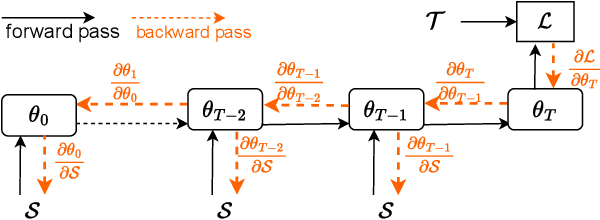

Dataset distillation is attracting more attention in machine learning as training sets continue to grow and the cost of training state-of-the-art models becomes increasingly high. By synthesizing datasets with high information density, dataset distillation offers a range of potential applications, including support for continual learning, neural architecture search, and privacy protection. Despite recent advances, we lack a holistic understanding of the approaches and applications. Our survey aims to bridge this gap by first proposing a taxonomy of dataset distillation, characterizing existing approaches, and then systematically reviewing the data modalities, and related applications. In addition, we summarize the challenges and discuss future directions for this field of research.