 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Language Models for Continual Relation Extraction
Apr 07, 2025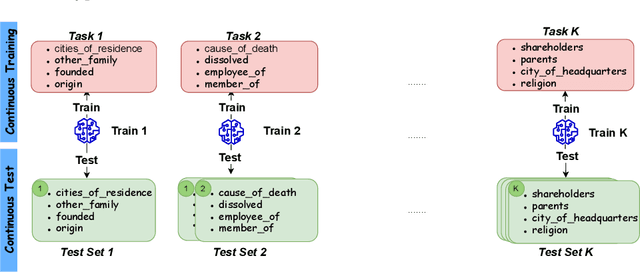
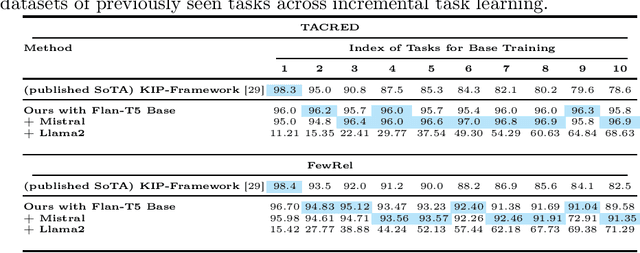

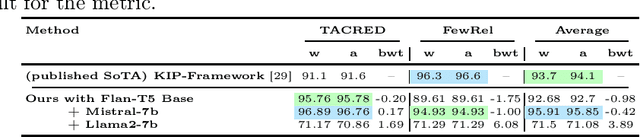
Real-world data, such as news articles, social media posts, and chatbot conversations, is inherently dynamic and non-stationary, presenting significant challenges for constructing real-time structured representations through knowledge graphs (KGs). Relation Extraction (RE), a fundamental component of KG creation, often struggles to adapt to evolving data when traditional models rely on static, outdated datasets. Continual Relation Extraction (CRE) methods tackle this issue by incrementally learning new relations while preserving previously acquired knowledge. This study investigates the application of pre-trained language models (PLMs), specifically large language models (LLMs), to CRE, with a focus on leveraging memory replay to address catastrophic forgetting. We evaluate decoder-only models (eg, Mistral-7B and Llama2-7B) and encoder-decoder models (eg, Flan-T5 Base) on the TACRED and FewRel datasets. Task-incremental fine-tuning of LLMs demonstrates superior performance over earlier approaches using encoder-only models like BERT on TACRED, excelling in seen-task accuracy and overall performance (measured by whole and average accuracy), particularly with the Mistral and Flan-T5 models. Results on FewRel are similarly promising, achieving second place in whole and average accuracy metrics. This work underscores critical factors in knowledge transfer, language model architecture, and KG completeness, advancing CRE with LLMs and memory replay for dynamic, real-time relation extraction.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Relation Extraction with Fine-Tuned Large Language Models in Retrieval Augmented Generation Frameworks
Jun 24, 2024
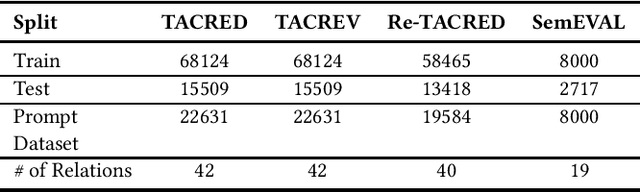

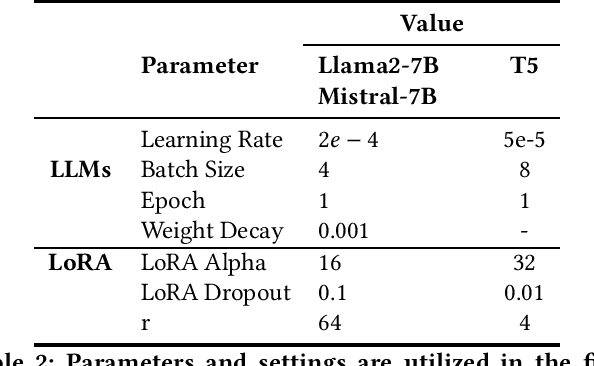
Information Extraction (IE) is crucial for converting unstructured data into structured formats like Knowledge Graphs (KGs). A key task within IE is Relation Extraction (RE), which identifies relationships between entities in text. Various RE methods exist, including supervised, unsupervised, weakly supervised, and rule-based approaches. Recent studies leveraging pre-trained language models (PLMs) have shown significant success in this area. In the current era dominated by Large Language Models (LLMs), fine-tuning these models can overcome limitations associated with zero-shot LLM prompting-based RE methods, especially regarding domain adaptation challenges and identifying implicit relations between entities in sentences. These implicit relations, which cannot be easily extracted from a sentence's dependency tree, require logical inference for accurate identification. This work explores the performance of fine-tuned LLMs and their integration into the Retrieval Augmented-based (RAG) RE approach to address the challenges of identifying implicit relations at the sentence level, particularly when LLMs act as generators within the RAG framework. Empirical evaluations on the TACRED, TACRED-Revisited (TACREV), Re-TACRED, and SemEVAL datasets show significant performance improvements with fine-tuned LLMs, including Llama2-7B, Mistral-7B, and T5 (Large). Notably, our approach achieves substantial gains on SemEVAL, where implicit relations are common, surpassing previous results on this dataset. Additionally, our method outperforms previous works on TACRED, TACREV, and Re-TACRED, demonstrating exceptional performance across diverse evaluation scenarios.
Retrieval-Augmented Generation-based Relation Extraction
Apr 20, 2024



Information Extraction (IE) is a transformative process that converts unstructured text data into a structured format by employing entity and relation extraction (RE) methodologies. The identification of the relation between a pair of entities plays a crucial role within this framework. Despite the existence of various techniques for relation extraction, their efficacy heavily relies on access to labeled data and substantial computational resources. In addressing these challenges, Large Language Models (LLMs) emerge as promising solutions; however, they might return hallucinating responses due to their own training data. To overcome these limitations, Retrieved-Augmented Generation-based Relation Extraction (RAG4RE) in this work is proposed, offering a pathway to enhance the performance of relation extraction tasks. This work evaluated the effectiveness of our RAG4RE approach utilizing different LLMs. Through the utilization of established benchmarks, such as TACRED, TACREV, Re-TACRED, and SemEval RE datasets, our aim is to comprehensively evaluate the efficacy of our RAG4RE approach. In particularly, we leverage prominent LLMs including Flan T5, Llama2, and Mistral in our investigation. The results of our study demonstrate that our RAG4RE approach surpasses performance of traditional RE approaches based solely on LLMs, particularly evident in the TACRED dataset and its variations. Furthermore, our approach exhibits remarkable performance compared to previous RE methodologies across both TACRED and TACREV datasets, underscoring its efficacy and potential for advancing RE tasks in natural language processing.
A Continual Relation Extraction Approach for Knowledge Graph Completeness
Apr 20, 2024Representing unstructured data in a structured form is most significant for information system management to analyze and interpret it. To do this, the unstructured data might be converted into Knowledge Graphs, by leveraging an information extraction pipeline whose main tasks are named entity recognition and relation extraction. This thesis aims to develop a novel continual relation extraction method to identify relations (interconnections) between entities in a data stream coming from the real world. Domain-specific data of this thesis is corona news from German and Austrian newspapers.
* Published at TPDL 2022
Fine-Grained Named Entities for Corona News
Apr 20, 2024Information resources such as newspapers have produced unstructured text data in various languages related to the corona outbreak since December 2019. Analyzing these unstructured texts is time-consuming without representing them in a structured format; therefore, representing them in a structured format is crucial. An information extraction pipeline with essential tasks -- named entity tagging and relation extraction -- to accomplish this goal might be applied to these texts. This study proposes a data annotation pipeline to generate training data from corona news articles, including generic and domain-specific entities. Named entity recognition models are trained on this annotated corpus and then evaluated on test sentences manually annotated by domain experts evaluating the performance of a trained model. The code base and demonstration are available at https://github.com/sefeoglu/coronanews-ner.git.
* Published at SWAT4HCLS 2023: The 14th International Conference on Semantic Web Applications and Tools for Health Care and Life Sciences
GraphMatcher: A Graph Representation Learning Approach for Ontology Matching
Apr 20, 2024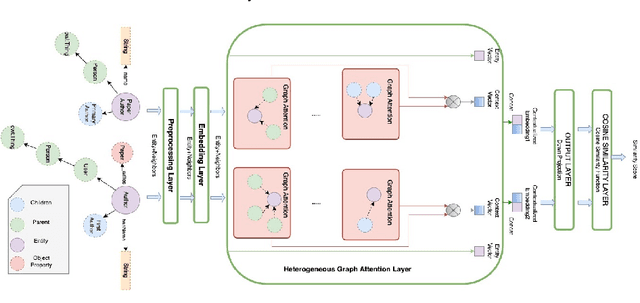
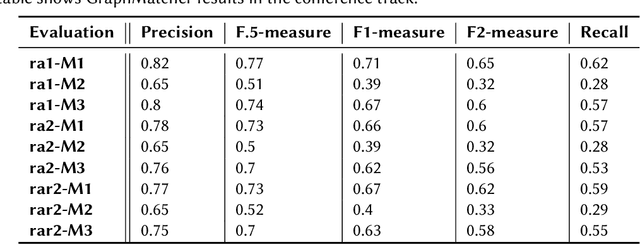
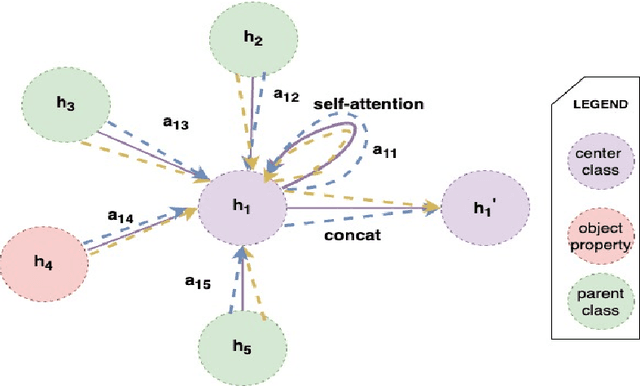
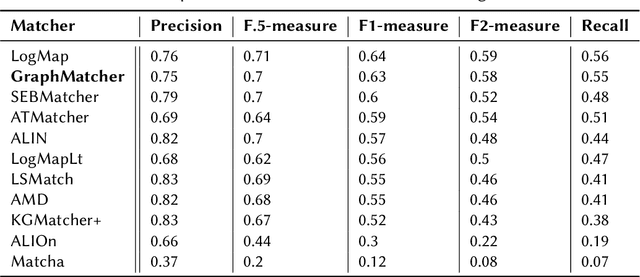
Ontology matching is defined as finding a relationship or correspondence between two or more entities in two or more ontologies. To solve the interoperability problem of the domain ontologies, semantically similar entities in these ontologies must be found and aligned before merging them. GraphMatcher, developed in this study, is an ontology matching system using a graph attention approach to compute higher-level representation of a class together with its surrounding terms. The GraphMatcher has obtained remarkable results in in the Ontology Alignment Evaluation Initiative (OAEI) 2022 conference track. Its codes are available at ~\url{https://github.com/sefeoglu/gat_ontology_matching}.
* The 17th International Workshop on Ontology Matching, The 21st International Semantic Web Conference (ISWC) 2022, 23 October 2022, Hangzhou, China