 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Extraction with Fine-Tuned Large Language Models in Retrieval Augmented Generation Frameworks
Paper and Code

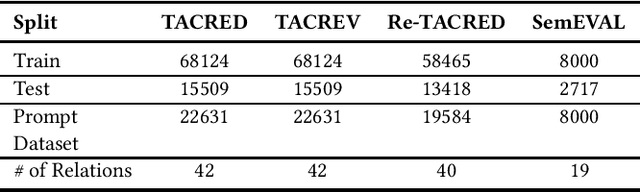

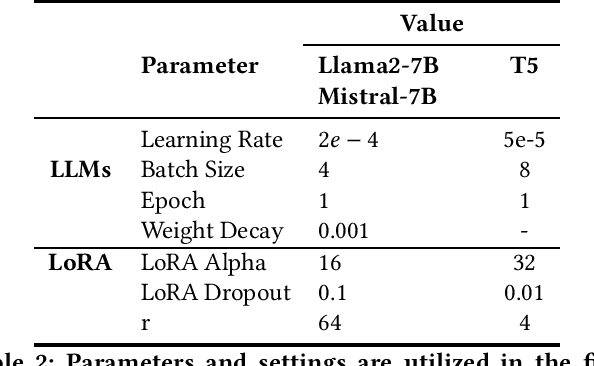
Information Extraction (IE) is crucial for converting unstructured data into structured formats like Knowledge Graphs (KGs). A key task within IE is Relation Extraction (RE), which identifies relationships between entities in text. Various RE methods exist, including supervised, unsupervised, weakly supervised, and rule-based approaches. Recent studies leveraging pre-trained language models (PLMs) have shown significant success in this area. In the current era dominated by Large Language Models (LLMs), fine-tuning these models can overcome limitations associated with zero-shot LLM prompting-based RE methods, especially regarding domain adaptation challenges and identifying implicit relations between entities in sentences. These implicit relations, which cannot be easily extracted from a sentence's dependency tree, require logical inference for accurate identification. This work explores the performance of fine-tuned LLMs and their integration into the Retrieval Augmented-based (RAG) RE approach to address the challenges of identifying implicit relations at the sentence level, particularly when LLMs act as generators within the RAG framework. Empirical evaluations on the TACRED, TACRED-Revisited (TACREV), Re-TACRED, and SemEVAL datasets show significant performance improvements with fine-tuned LLMs, including Llama2-7B, Mistral-7B, and T5 (Large). Notably, our approach achieves substantial gains on SemEVAL, where implicit relations are common, surpassing previous results on this dataset. Additionally, our method outperforms previous works on TACRED, TACREV, and Re-TACRED, demonstrating exceptional performance across diverse evaluation scenarios.