 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Flow Models: Anchoring Concept-Based Reasoning with Hierarchical Bottlenecks
Jun 17, 2026Concept Bottleneck Models (CBMs) enhance interpretability by projecting learned features into a human-understandable concept space. Recent approaches leverage vision-language models to generate concept embeddings, reducing the need for manual concept annotations. However, these models suffer from a critical limitation: as the number of concepts approaches the embedding dimension, information leakage increases, enabling the model to exploit spurious or semantically irrelevant correlations and undermining interpretability. In this work, we propose Concept Flow Models (CFMs), which replace the flat bottleneck with a hierarchical, concept-driven decision tree. Each internal node in the hierarchy focuses on a localized subset of discriminative concepts, progressively narrowing the prediction scope. Our framework constructs decision hierarchies from visual embeddings, distributes semantic concepts at each hierarchy level, and trains differentiable concept weights through probabilistic tree traversal. Extensive experiments on diverse benchmarks demonstrate that CFMs match the predictive performance of flat CBMs, while substantially mitigating information leakage by reducing effective concept usage. Furthermore, CFMs yield stepwise decision flows that enable transparent and auditable model reasoning with hierarchical class structures.
ToxiGAN: Toxic Data Augmentation via LLM-Guided Directional Adversarial Generation
Jan 06, 2026Augmenting toxic language data in a controllable and class-specific manner is crucial for improving robustness in toxicity classification, yet remains challenging due to limited supervision and distributional skew. We propose ToxiGAN, a class-aware text augmentation framework that combines adversarial generation with semantic guidance from large language models (LLMs). To address common issues in GAN-based augmentation such as mode collapse and semantic drift, ToxiGAN introduces a two-step directional training strategy and leverages LLM-generated neutral texts as semantic ballast. Unlike prior work that treats LLMs as static generators, our approach dynamically selects neutral exemplars to provide balanced guidance. Toxic samples are explicitly optimized to diverge from these exemplars, reinforcing class-specific contrastive signals. Experiments on four hate speech benchmarks show that ToxiGAN achieves the strongest average performance in both macro-F1 and hate-F1, consistently outperforming traditional and LLM-based augmentation methods. Ablation and sensitivity analyses further confirm the benefits of semantic ballast and directional training in enhancing classifier robustness.
Neural Network-Powered Finger-Drawn Biometric Authentication
Nov 14, 2025This paper investigates neural network-based biometric authentication using finger-drawn digits on touchscreen devices. We evaluated CNN and autoencoder architectures for user authentication through simple digit patterns (0-9) traced with finger input. Twenty participants contributed 2,000 finger-drawn digits each on personal touchscreen devices. We compared two CNN architectures: a modified Inception-V1 network and a lightweight shallow CNN for mobile environments. Additionally, we examined Convolutional and Fully Connected autoencoders for anomaly detection. Both CNN architectures achieved ~89% authentication accuracy, with the shallow CNN requiring fewer parameters. Autoencoder approaches achieved ~75% accuracy. The results demonstrate that finger-drawn symbol authentication provides a viable, secure, and user-friendly biometric solution for touchscreen devices. This approach can be integrated with existing pattern-based authentication methods to create multi-layered security systems for mobile applications.
Designing and Evaluating Malinowski's Lens: An AI-Native Educational Game for Ethnographic Learning
Nov 10, 2025This study introduces 'Malinowski's Lens', the first AI-native educational game for anthropology that transforms Bronislaw Malinowski's 'Argonauts of the Western Pacific' (1922) into an interactive learning experience. The system combines Retrieval-Augmented Generation with DALL-E 3 text-to-image generation, creating consistent VGA-style visuals as players embody Malinowski during his Trobriand Islands fieldwork (1915-1918). To address ethical concerns, indigenous peoples appear as silhouettes while Malinowski is detailed, prompting reflection on anthropological representation. Two validation studies confirmed effectiveness: Study 1 with 10 non-specialists showed strong learning outcomes (average quiz score 7.5/10) and excellent usability (SUS: 83/100). Study 2 with 4 expert anthropologists confirmed pedagogical value, with one senior researcher discovering "new aspects" of Malinowski's work through gameplay. The findings demonstrate that AI-driven educational games can effectively convey complex anthropological concepts while sparking disciplinary curiosity. This study advances AI-native educational game design and provides a replicable model for transforming academic texts into engaging interactive experiences.
Leveraging Diffusion Models for Parameterized Quantum Circuit Generation
May 27, 2025Quantum computing holds immense potential, yet its practical success depends on multiple factors, including advances in quantum circuit design. In this paper, we introduce a generative approach based on denoising diffusion models (DMs) to synthesize parameterized quantum circuits (PQCs). Extending the recent diffusion model pipeline of F\"urrutter et al. [1], our model effectively conditions the synthesis process, enabling the simultaneous generation of circuit architectures and their continuous gate parameters. We demonstrate our approach in synthesizing PQCs optimized for generating high-fidelity Greenberger-Horne-Zeilinger (GHZ) states and achieving high accuracy in quantum machine learning (QML) classification tasks. Our results indicate a strong generalization across varying gate sets and scaling qubit counts, highlighting the versatility and computational efficiency of diffusion-based methods. This work illustrates the potential of generative models as a powerful tool for accelerating and optimizing the design of PQCs, supporting the development of more practical and scalable quantum applications.
Uncertainty-Aware Trajectory Prediction via Rule-Regularized Heteroscedastic Deep Classification
Apr 17, 2025



Deep learning-based trajectory prediction models have demonstrated promising capabilities in capturing complex interactions. However, their out-of-distribution generalization remains a significant challenge, particularly due to unbalanced data and a lack of enough data and diversity to ensure robustness and calibration. To address this, we propose SHIFT (Spectral Heteroscedastic Informed Forecasting for Trajectories), a novel framework that uniquely combines well-calibrated uncertainty modeling with informative priors derived through automated rule extraction. SHIFT reformulates trajectory prediction as a classification task and employs heteroscedastic spectral-normalized Gaussian processes to effectively disentangle epistemic and aleatoric uncertainties. We learn informative priors from training labels, which are automatically generated from natural language driving rules, such as stop rules and drivability constraints, using a retrieval-augmented generation framework powered by a large language model. Extensive evaluations over the nuScenes dataset, including challenging low-data and cross-location scenarios, demonstrate that SHIFT outperforms state-of-the-art methods, achieving substantial gains in uncertainty calibration and displacement metrics. In particular, our model excels in complex scenarios, such as intersections, where uncertainty is inherently higher. Project page: https://kumarmanas.github.io/SHIFT/.
* 17 Pages, 9 figures. Accepted to Robotics: Science and Systems(RSS), 2025
Post-Training Language Models for Continual Relation Extraction
Apr 07, 2025
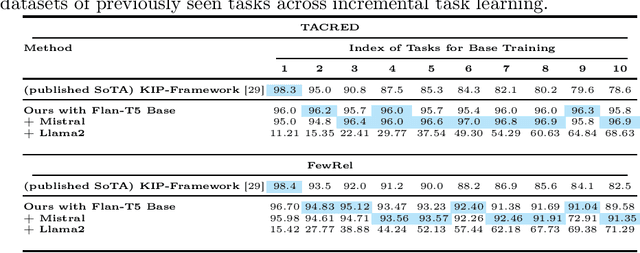

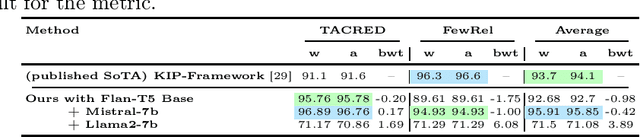
Real-world data, such as news articles, social media posts, and chatbot conversations, is inherently dynamic and non-stationary, presenting significant challenges for constructing real-time structured representations through knowledge graphs (KGs). Relation Extraction (RE), a fundamental component of KG creation, often struggles to adapt to evolving data when traditional models rely on static, outdated datasets. Continual Relation Extraction (CRE) methods tackle this issue by incrementally learning new relations while preserving previously acquired knowledge. This study investigates the application of pre-trained language models (PLMs), specifically large language models (LLMs), to CRE, with a focus on leveraging memory replay to address catastrophic forgetting. We evaluate decoder-only models (eg, Mistral-7B and Llama2-7B) and encoder-decoder models (eg, Flan-T5 Base) on the TACRED and FewRel datasets. Task-incremental fine-tuning of LLMs demonstrates superior performance over earlier approaches using encoder-only models like BERT on TACRED, excelling in seen-task accuracy and overall performance (measured by whole and average accuracy), particularly with the Mistral and Flan-T5 models. Results on FewRel are similarly promising, achieving second place in whole and average accuracy metrics. This work underscores critical factors in knowledge transfer, language model architecture, and KG completeness, advancing CRE with LLMs and memory replay for dynamic, real-time relation extraction.
Improving Hate Speech Classification with Cross-Taxonomy Dataset Integration
Mar 07, 2025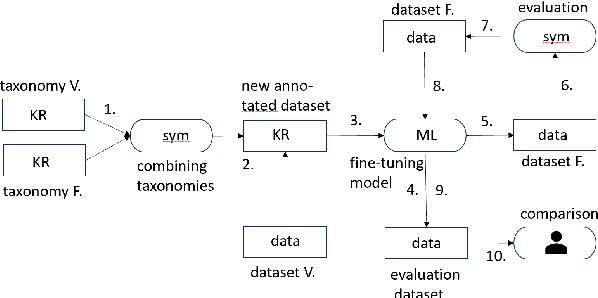
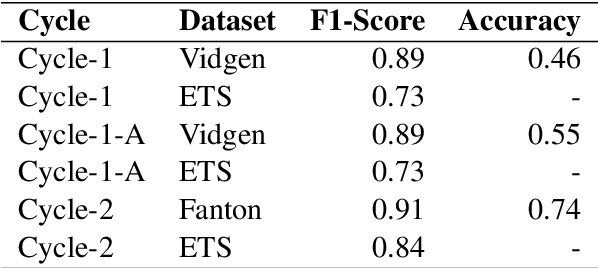

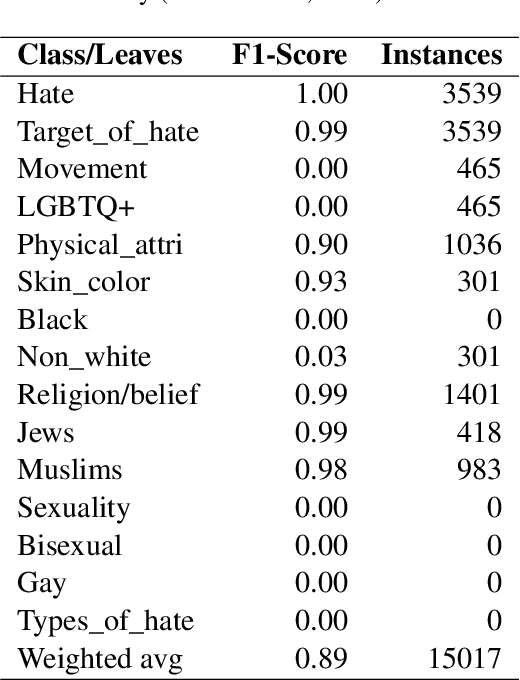
Algorithmic hate speech detection faces significant challenges due to the diverse definitions and datasets used in research and practice. Social media platforms, legal frameworks, and institutions each apply distinct yet overlapping definitions, complicating classification efforts. This study addresses these challenges by demonstrating that existing datasets and taxonomies can be integrated into a unified model, enhancing prediction performance and reducing reliance on multiple specialized classifiers. The work introduces a universal taxonomy and a hate speech classifier capable of detecting a wide range of definitions within a single framework. Our approach is validated by combining two widely used but differently annotated datasets, showing improved classification performance on an independent test set. This work highlights the potential of dataset and taxonomy integration in advancing hate speech detection, increasing efficiency, and ensuring broader applicability across contexts.
GETAE: Graph information Enhanced deep neural NeTwork ensemble ArchitecturE for fake news detection
Dec 02, 2024



In today's digital age, fake news has become a major problem that has serious consequences, ranging from social unrest to political upheaval. To address this issue, new methods for detecting and mitigating fake news are required. In this work, we propose to incorporate contextual and network-aware features into the detection process. This involves analyzing not only the content of a news article but also the context in which it was shared and the network of users who shared it, i.e., the information diffusion. Thus, we propose GETAE, \underline{G}raph Information \underline{E}nhanced Deep Neural Ne\underline{t}work Ensemble \underline{A}rchitectur\underline{E} for Fake News Detection, a novel ensemble architecture that uses textual content together with the social interactions to improve fake news detection. GETAE contains two Branches: the Text Branch and the Propagation Branch. The Text Branch uses Word and Transformer Embeddings and a Deep Neural Network based on feed-forward and bidirectional Recurrent Neural Networks (\textsc{[Bi]RNN}) for learning novel contextual features and creating a novel Text Content Embedding. The Propagation Branch considers the information propagation within the graph network and proposes a Deep Learning architecture that employs Node Embeddings to create novel Propagation Embedding. GETAE Ensemble combines the two novel embeddings, i.e., Text Content Embedding and Propagation Embedding, to create a novel \textit{Propagation-Enhanced Content Embedding} which is afterward used for classification. The experimental results obtained on two real-world publicly available datasets, i.e., Twitter15 and Twitter16, prove that using this approach improves fake news detection and outperforms state-of-the-art models.
Malinowski in the Age of AI: Can large language models create a text game based on an anthropological classic?
Oct 27, 2024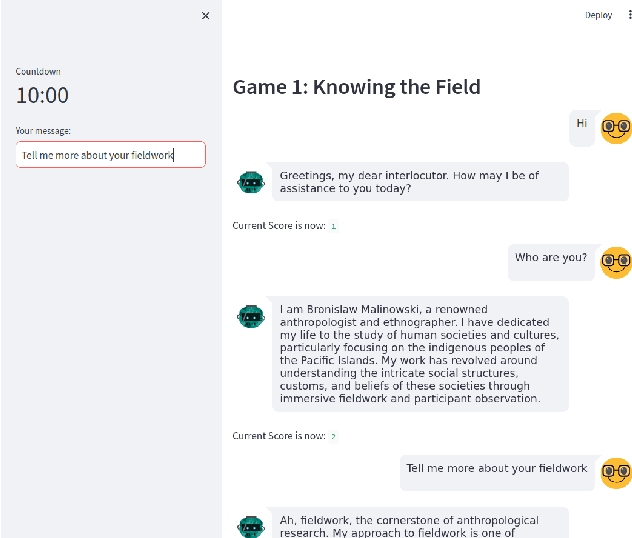

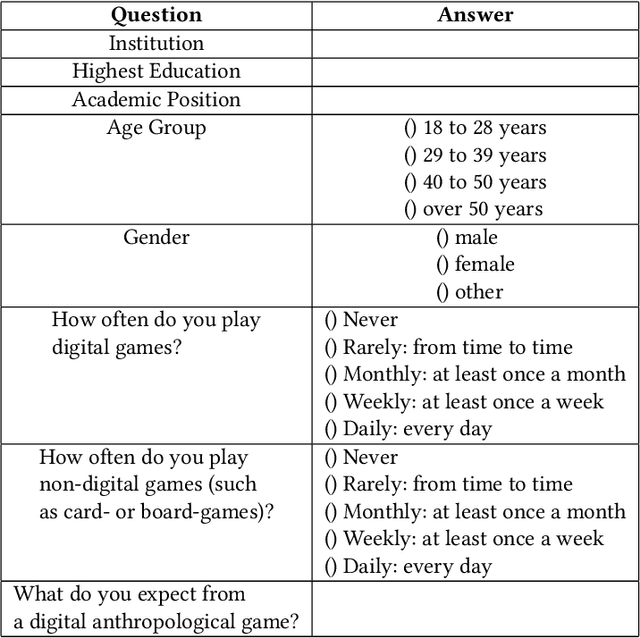
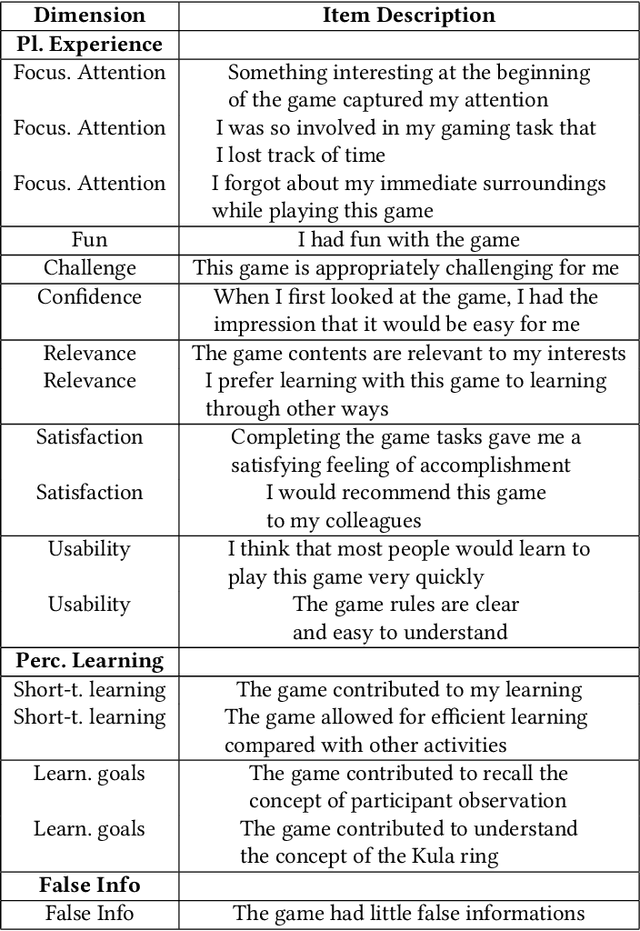
Recent advancements in Large Language Models (LLMs) like ChatGPT and GPT-4 have shown remarkable abilities in a wide range of tasks such as summarizing texts and assisting in coding. Scientific research has demonstrated that these models can also play text-adventure games. This study aims to explore whether LLMs can autonomously create text-based games based on anthropological classics, evaluating also their effectiveness in communicating knowledge. To achieve this, the study engaged anthropologists in discussions to gather their expectations and design inputs for an anthropologically themed game. Through iterative processes following the established HCI principle of 'design thinking', the prompts and the conceptual framework for crafting these games were refined. Leveraging GPT3.5, the study created three prototypes of games centered around the seminal anthropological work of the social anthropologist's Bronislaw Malinowski's "Argonauts of the Western Pacific" (1922). Subsequently, evaluations were conducted by inviting senior anthropologists to playtest these games, and based on their inputs, the game designs were refined. The tests revealed promising outcomes but also highlighted key challenges: the models encountered difficulties in providing in-depth thematic understandings, showed suspectibility to misinformation, tended towards monotonic responses after an extended period of play, and struggled to offer detailed biographical information. Despite these limitations, the study's findings open up new research avenues at the crossroads of artificial intelligence, machine learning, LLMs, ethnography, anthropology and human-computer interaction.