 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining the Development of Active Learning Methods in Real-World Object Detection
Aug 27, 2025Active learning (AL) for real-world object detection faces computational and reliability challenges that limit practical deployment. Developing new AL methods requires training multiple detectors across iterations to compare against existing approaches. This creates high costs for autonomous driving datasets where the training of one detector requires up to 282 GPU hours. Additionally, AL method rankings vary substantially across validation sets, compromising reliability in safety-critical transportation systems. We introduce object-based set similarity ($\mathrm{OSS}$), a metric that addresses these challenges. $\mathrm{OSS}$ (1) quantifies AL method effectiveness without requiring detector training by measuring similarity between training sets and target domains using object-level features. This enables the elimination of ineffective AL methods before training. Furthermore, $\mathrm{OSS}$ (2) enables the selection of representative validation sets for robust evaluation. We validate our similarity-based approach on three autonomous driving datasets (KITTI, BDD100K, CODA) using uncertainty-based AL methods as a case study with two detector architectures (EfficientDet, YOLOv3). This work is the first to unify AL training and evaluation strategies in object detection based on object similarity. $\mathrm{OSS}$ is detector-agnostic, requires only labeled object crops, and integrates with existing AL pipelines. This provides a practical framework for deploying AL in real-world applications where computational efficiency and evaluation reliability are critical. Code is available at https://mos-ks.github.io/publications/.
Generative AI for Autonomous Driving: A Review
May 21, 2025Generative AI (GenAI) is rapidly advancing the field of Autonomous Driving (AD), extending beyond traditional applications in text, image, and video generation. We explore how generative models can enhance automotive tasks, such as static map creation, dynamic scenario generation, trajectory forecasting, and vehicle motion planning. By examining multiple generative approaches ranging from Variational Autoencoder (VAEs) over Generative Adversarial Networks (GANs) and Invertible Neural Networks (INNs) to Generative Transformers (GTs) and Diffusion Models (DMs), we highlight and compare their capabilities and limitations for AD-specific applications. Additionally, we discuss hybrid methods integrating conventional techniques with generative approaches, and emphasize their improved adaptability and robustness. We also identify relevant datasets and outline open research questions to guide future developments in GenAI. Finally, we discuss three core challenges: safety, interpretability, and realtime capabilities, and present recommendations for image generation, dynamic scenario generation, and planning.
Uncertainty-Aware Trajectory Prediction via Rule-Regularized Heteroscedastic Deep Classification
Apr 17, 2025



Deep learning-based trajectory prediction models have demonstrated promising capabilities in capturing complex interactions. However, their out-of-distribution generalization remains a significant challenge, particularly due to unbalanced data and a lack of enough data and diversity to ensure robustness and calibration. To address this, we propose SHIFT (Spectral Heteroscedastic Informed Forecasting for Trajectories), a novel framework that uniquely combines well-calibrated uncertainty modeling with informative priors derived through automated rule extraction. SHIFT reformulates trajectory prediction as a classification task and employs heteroscedastic spectral-normalized Gaussian processes to effectively disentangle epistemic and aleatoric uncertainties. We learn informative priors from training labels, which are automatically generated from natural language driving rules, such as stop rules and drivability constraints, using a retrieval-augmented generation framework powered by a large language model. Extensive evaluations over the nuScenes dataset, including challenging low-data and cross-location scenarios, demonstrate that SHIFT outperforms state-of-the-art methods, achieving substantial gains in uncertainty calibration and displacement metrics. In particular, our model excels in complex scenarios, such as intersections, where uncertainty is inherently higher. Project page: https://kumarmanas.github.io/SHIFT/.
* 17 Pages, 9 figures. Accepted to Robotics: Science and Systems(RSS), 2025
Cost-Sensitive Uncertainty-Based Failure Recognition for Object Detection
Apr 26, 2024



Object detectors in real-world applications often fail to detect objects due to varying factors such as weather conditions and noisy input. Therefore, a process that mitigates false detections is crucial for both safety and accuracy. While uncertainty-based thresholding shows promise, previous works demonstrate an imperfect correlation between uncertainty and detection errors. This hinders ideal thresholding, prompting us to further investigate the correlation and associated cost with different types of uncertainty. We therefore propose a cost-sensitive framework for object detection tailored to user-defined budgets on the two types of errors, missing and false detections. We derive minimum thresholding requirements to prevent performance degradation and define metrics to assess the applicability of uncertainty for failure recognition. Furthermore, we automate and optimize the thresholding process to maximize the failure recognition rate w.r.t. the specified budget. Evaluation on three autonomous driving datasets demonstrates that our approach significantly enhances safety, particularly in challenging scenarios. Leveraging localization aleatoric uncertainty and softmax-based entropy only, our method boosts the failure recognition rate by 36-60\% compared to conventional approaches. Code is available at https://mos-ks.github.io/publications.
Informed Spectral Normalized Gaussian Processes for Trajectory Prediction
Mar 18, 2024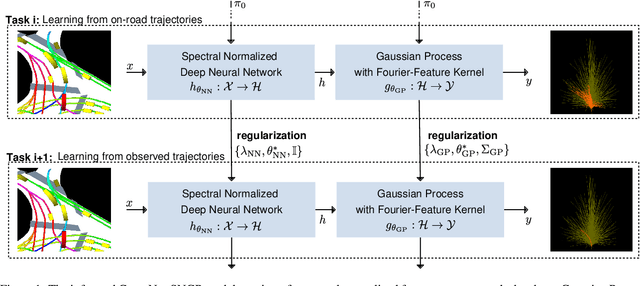

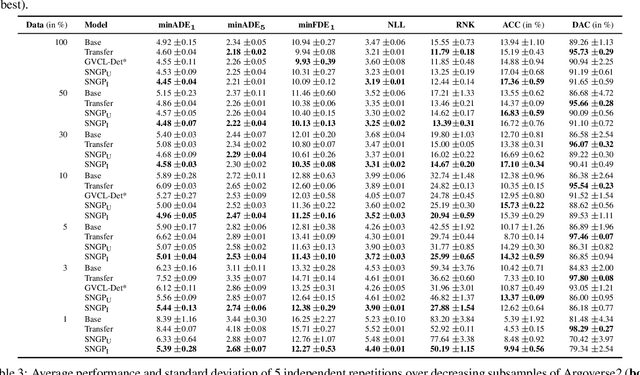

Prior parameter distributions provide an elegant way to represent prior expert and world knowledge for informed learning. Previous work has shown that using such informative priors to regularize probabilistic deep learning (DL) models increases their performance and data-efficiency. However, commonly used sampling-based approximations for probabilistic DL models can be computationally expensive, requiring multiple inference passes and longer training times. Promising alternatives are compute-efficient last layer kernel approximations like spectral normalized Gaussian processes (SNGPs). We propose a novel regularization-based continual learning method for SNGPs, which enables the use of informative priors that represent prior knowledge learned from previous tasks. Our proposal builds upon well-established methods and requires no rehearsal memory or parameter expansion. We apply our informed SNGP model to the trajectory prediction problem in autonomous driving by integrating prior drivability knowledge. On two public datasets, we investigate its performance under diminishing training data and across locations, and thereby demonstrate an increase in data-efficiency and robustness to location-transfers over non-informed and informed baselines.
Explainable Bayesian Optimization
Jan 24, 2024In industry, Bayesian optimization (BO) is widely applied in the human-AI collaborative parameter tuning of cyber-physical systems. However, BO's solutions may deviate from human experts' actual goal due to approximation errors and simplified objectives, requiring subsequent tuning. The black-box nature of BO limits the collaborative tuning process because the expert does not trust the BO recommendations. Current explainable AI (XAI) methods are not tailored for optimization and thus fall short of addressing this gap. To bridge this gap, we propose TNTRules (TUNE-NOTUNE Rules), a post-hoc, rule-based explainability method that produces high quality explanations through multiobjective optimization. Our evaluation of benchmark optimization problems and real-world hyperparameter optimization tasks demonstrates TNTRules' superiority over state-of-the-art XAI methods in generating high quality explanations. This work contributes to the intersection of BO and XAI, providing interpretable optimization techniques for real-world applications.
Overcoming the Limitations of Localization Uncertainty: Efficient & Exact Non-Linear Post-Processing and Calibration
Jun 15, 2023Robustly and accurately localizing objects in real-world environments can be challenging due to noisy data, hardware limitations, and the inherent randomness of physical systems. To account for these factors, existing works estimate the aleatoric uncertainty of object detectors by modeling their localization output as a Gaussian distribution $\mathcal{N}(\mu,\,\sigma^{2})\,$, and training with loss attenuation. We identify three aspects that are unaddressed in the state of the art, but warrant further exploration: (1) the efficient and mathematically sound propagation of $\mathcal{N}(\mu,\,\sigma^{2})\,$ through non-linear post-processing, (2) the calibration of the predicted uncertainty, and (3) its interpretation. We overcome these limitations by: (1) implementing loss attenuation in EfficientDet, and proposing two deterministic methods for the exact and fast propagation of the output distribution, (2) demonstrating on the KITTI and BDD100K datasets that the predicted uncertainty is miscalibrated, and adapting two calibration methods to the localization task, and (3) investigating the correlation between aleatoric uncertainty and task-relevant error sources. Our contributions are: (1) up to five times faster propagation while increasing localization performance by up to 1\%, (2) up to fifteen times smaller expected calibration error, and (3) the predicted uncertainty is found to correlate with occlusion, object distance, detection accuracy, and image quality.
Informed Priors for Knowledge Integration in Trajectory Prediction
Nov 01, 2022Informed machine learning methods allow the integration of prior knowledge into learning systems. This can increase accuracy and robustness or reduce data needs. However, existing methods often assume hard constraining knowledge, that does not require to trade-off prior knowledge with observations, but can be used to directly reduce the problem space. Other approaches use specific, architectural changes as representation of prior knowledge, limiting applicability. We propose an informed machine learning method, based on continual learning. This allows the integration of arbitrary, prior knowledge, potentially from multiple sources, and does not require specific architectures. Furthermore, our approach enables probabilistic and multi-modal predictions, that can improve predictive accuracy and robustness. We exemplify our approach by applying it to a state-of-the-art trajectory predictor for autonomous driving. This domain is especially dependent on informed learning approaches, as it is subject to an overwhelming large variety of possible environments and very rare events, while requiring robust and accurate predictions. We evaluate our model on a commonly used benchmark dataset, only using data already available in a conventional setup. We show that our method outperforms both non-informed and informed learning methods, that are often used in the literature. Furthermore, we are able to compete with a conventional baseline, even using half as many observation examples.
Efficient Utility Function Learning for Multi-Objective Parameter Optimization with Prior Knowledge
Aug 22, 2022

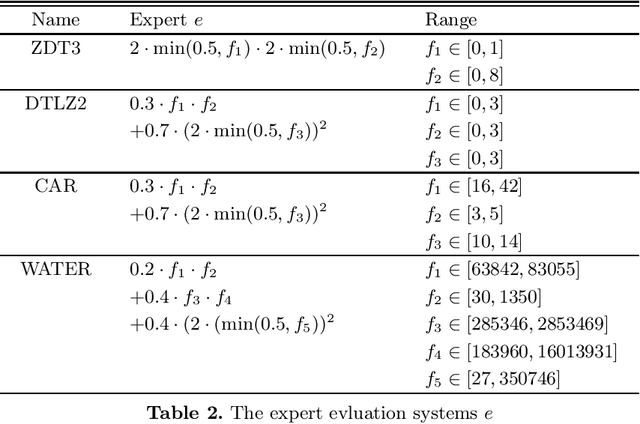

The current state-of-the-art in multi-objective optimization assumes either a given utility function, learns a utility function interactively or tries to determine the complete Pareto front, requiring a post elicitation of the preferred result. However, result elicitation in real world problems is often based on implicit and explicit expert knowledge, making it difficult to define a utility function, whereas interactive learning or post elicitation requires repeated and expensive expert involvement. To mitigate this, we learn a utility function offline, using expert knowledge by means of preference learning. In contrast to other works, we do not only use (pairwise) result preferences, but also coarse information about the utility function space. This enables us to improve the utility function estimate, especially when using very few results. Additionally, we model the occurring uncertainties in the utility function learning task and propagate them through the whole optimization chain. Our method to learn a utility function eliminates the need of repeated expert involvement while still leading to high-quality results. We show the sample efficiency and quality gains of the proposed method in 4 domains, especially in cases where the surrogate utility function is not able to exactly capture the true expert utility function. We also show that to obtain good results, it is important to consider the induced uncertainties and analyze the effect of biased samples, which is a common problem in real world domains.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022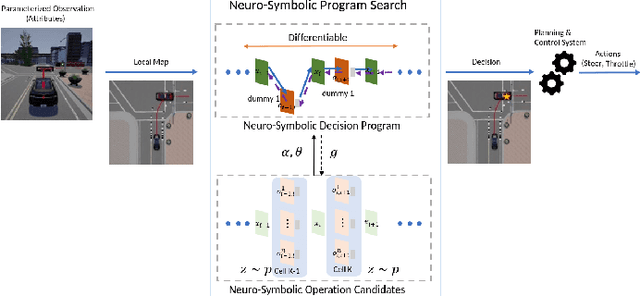
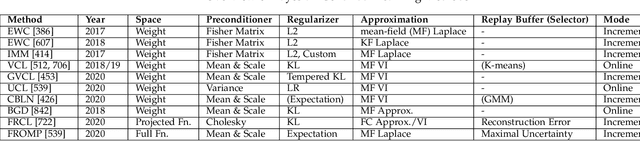
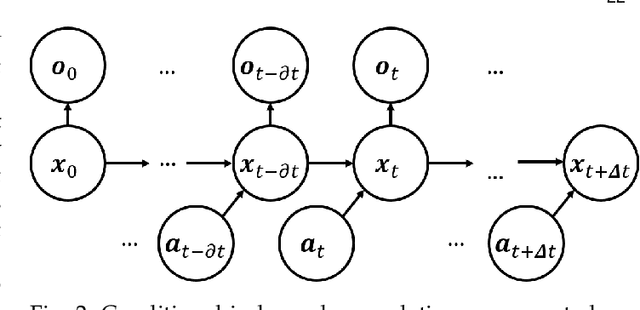
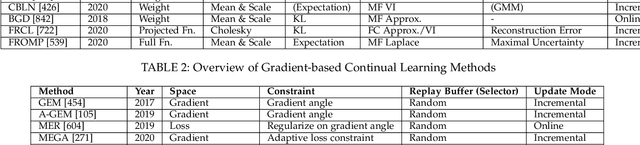
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.