 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdinal Monte Carlo Tree Search
Jan 26, 2021


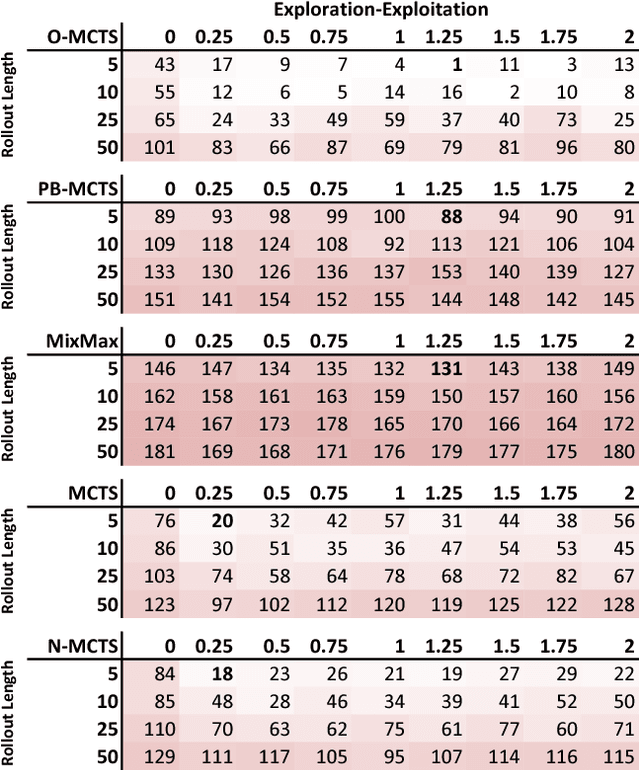
In many problem settings, most notably in game playing, an agent receives a possibly delayed reward for its actions. Often, those rewards are handcrafted and not naturally given. Even simple terminal-only rewards, like winning equals one and losing equals minus one, can not be seen as an unbiased statement, since these values are chosen arbitrarily, and the behavior of the learner may change with different encodings. It is hard to argue about good rewards and the performance of an agent often depends on the design of the reward signal. In particular, in domains where states by nature only have an ordinal ranking and where meaningful distance information between game state values is not available, a numerical reward signal is necessarily biased. In this paper we take a look at MCTS, a popular algorithm to solve MDPs, highlight a reoccurring problem concerning its use of rewards, and show that an ordinal treatment of the rewards overcomes this problem. Using the General Video Game Playing framework we show dominance of our newly proposed ordinal MCTS algorithm over other MCTS variants, based on a novel bandit algorithm that we also introduce and test versus UCB.
Ordinal Bucketing for Game Trees using Dynamic Quantile Approximation
May 31, 2019



In this paper, we present a simple and cheap ordinal bucketing algorithm that approximately generates $q$-quantiles from an incremental data stream. The bucketing is done dynamically in the sense that the amount of buckets $q$ increases with the number of seen samples. We show how this can be used in Ordinal Monte Carlo Tree Search (OMCTS) to yield better bounds on time and space complexity, especially in the presence of noisy rewards. Besides complexity analysis and quality tests of quantiles, we evaluate our method using OMCTS in the General Video Game Framework (GVGAI). Our results demonstrate its dominance over vanilla Monte Carlo Tree Search in the presence of noise, where OMCTS without bucketing has a very bad time and space complexity.
Deep Ordinal Reinforcement Learning
May 06, 2019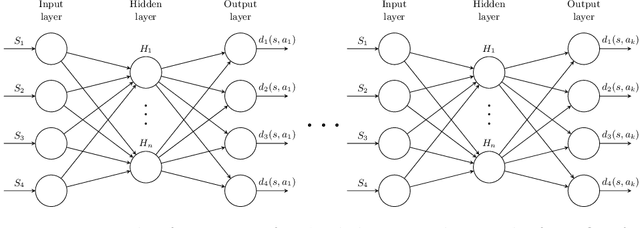



Reinforcement learning usually makes use of numerical rewards, which have nice properties but also come with drawbacks and difficulties. Using rewards on an ordinal scale (ordinal rewards) is an alternative to numerical rewards that has received more attention in recent years. In this paper, a general approach to adapting reinforcement learning problems to the use of ordinal rewards is presented and motivated. We show how to convert common reinforcement learning algorithms to an ordinal variation by the example of Q-learning and introduce Ordinal Deep Q-Networks, which adapt deep reinforcement learning to ordinal rewards. Additionally, we run evaluations on problems provided by the OpenAI Gym framework, showing that our ordinal variants exhibit a performance that is comparable to the numerical variations for a number of problems. We also give first evidence that our ordinal variant is able to produce better results for problems with less engineered and simpler-to-design reward signals.
Preference-Based Monte Carlo Tree Search
Jul 17, 2018
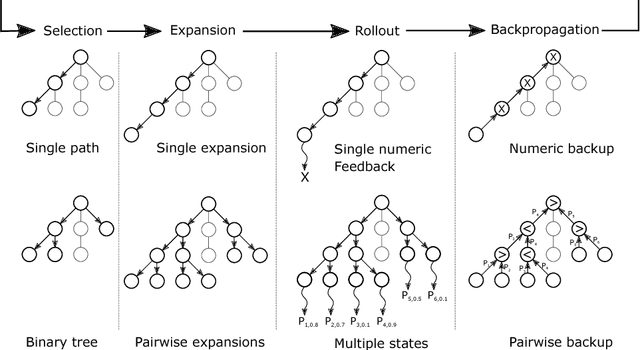

Monte Carlo tree search (MCTS) is a popular choice for solving sequential anytime problems. However, it depends on a numeric feedback signal, which can be difficult to define. Real-time MCTS is a variant which may only rarely encounter states with an explicit, extrinsic reward. To deal with such cases, the experimenter has to supply an additional numeric feedback signal in the form of a heuristic, which intrinsically guides the agent. Recent work has shown evidence that in different areas the underlying structure is ordinal and not numerical. Hence erroneous and biased heuristics are inevitable, especially in such domains. In this paper, we propose a MCTS variant which only depends on qualitative feedback, and therefore opens up new applications for MCTS. We also find indications that translating absolute into ordinal feedback may be beneficial. Using a puzzle domain, we show that our preference-based MCTS variant, wich only receives qualitative feedback, is able to reach a performance level comparable to a regular MCTS baseline, which obtains quantitative feedback.
* To be published