 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Based Monte Carlo Tree Search
Paper and Code
Jul 17, 2018
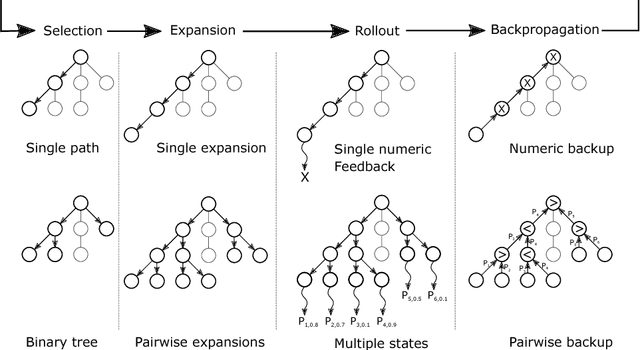

Monte Carlo tree search (MCTS) is a popular choice for solving sequential anytime problems. However, it depends on a numeric feedback signal, which can be difficult to define. Real-time MCTS is a variant which may only rarely encounter states with an explicit, extrinsic reward. To deal with such cases, the experimenter has to supply an additional numeric feedback signal in the form of a heuristic, which intrinsically guides the agent. Recent work has shown evidence that in different areas the underlying structure is ordinal and not numerical. Hence erroneous and biased heuristics are inevitable, especially in such domains. In this paper, we propose a MCTS variant which only depends on qualitative feedback, and therefore opens up new applications for MCTS. We also find indications that translating absolute into ordinal feedback may be beneficial. Using a puzzle domain, we show that our preference-based MCTS variant, wich only receives qualitative feedback, is able to reach a performance level comparable to a regular MCTS baseline, which obtains quantitative feedback.