 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Bayesian Optimization
Jan 24, 2024In industry, Bayesian optimization (BO) is widely applied in the human-AI collaborative parameter tuning of cyber-physical systems. However, BO's solutions may deviate from human experts' actual goal due to approximation errors and simplified objectives, requiring subsequent tuning. The black-box nature of BO limits the collaborative tuning process because the expert does not trust the BO recommendations. Current explainable AI (XAI) methods are not tailored for optimization and thus fall short of addressing this gap. To bridge this gap, we propose TNTRules (TUNE-NOTUNE Rules), a post-hoc, rule-based explainability method that produces high quality explanations through multiobjective optimization. Our evaluation of benchmark optimization problems and real-world hyperparameter optimization tasks demonstrates TNTRules' superiority over state-of-the-art XAI methods in generating high quality explanations. This work contributes to the intersection of BO and XAI, providing interpretable optimization techniques for real-world applications.
An Empirical Analysis of Fairness Notions under Differential Privacy
Feb 06, 2023



Recent works have shown that selecting an optimal model architecture suited to the differential privacy setting is necessary to achieve the best possible utility for a given privacy budget using differentially private stochastic gradient descent (DP-SGD)(Tramer and Boneh 2020; Cheng et al. 2022). In light of these findings, we empirically analyse how different fairness notions, belonging to distinct classes of statistical fairness criteria (independence, separation and sufficiency), are impacted when one selects a model architecture suitable for DP-SGD, optimized for utility. Using standard datasets from ML fairness literature, we show using a rigorous experimental protocol, that by selecting the optimal model architecture for DP-SGD, the differences across groups concerning the relevant fairness metrics (demographic parity, equalized odds and predictive parity) more often decrease or are negligibly impacted, compared to the non-private baseline, for which optimal model architecture has also been selected to maximize utility. These findings challenge the understanding that differential privacy will necessarily exacerbate unfairness in deep learning models trained on biased datasets.
Generalizing Adversarial Explanations with Grad-CAM
Apr 11, 2022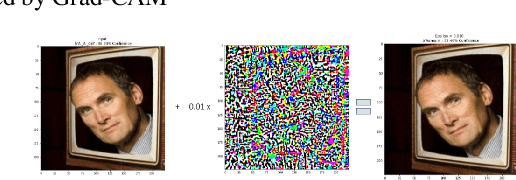
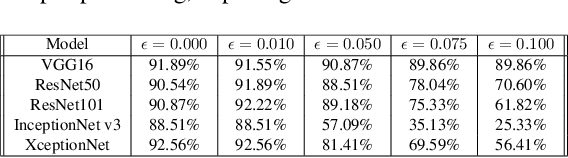

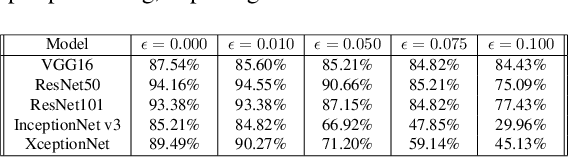
Gradient-weighted Class Activation Mapping (Grad- CAM), is an example-based explanation method that provides a gradient activation heat map as an explanation for Convolution Neural Network (CNN) models. The drawback of this method is that it cannot be used to generalize CNN behaviour. In this paper, we present a novel method that extends Grad-CAM from example-based explanations to a method for explaining global model behaviour. This is achieved by introducing two new metrics, (i) Mean Observed Dissimilarity (MOD) and (ii) Variation in Dissimilarity (VID), for model generalization. These metrics are computed by comparing a Normalized Inverted Structural Similarity Index (NISSIM) metric of the Grad-CAM generated heatmap for samples from the original test set and samples from the adversarial test set. For our experiment, we study adversarial attacks on deep models such as VGG16, ResNet50, and ResNet101, and wide models such as InceptionNetv3 and XceptionNet using Fast Gradient Sign Method (FGSM). We then compute the metrics MOD and VID for the automatic face recognition (AFR) use case with the VGGFace2 dataset. We observe a consistent shift in the region highlighted in the Grad-CAM heatmap, reflecting its participation to the decision making, across all models under adversarial attacks. The proposed method can be used to understand adversarial attacks and explain the behaviour of black box CNN models for image analysis.
SpectralNET: Exploring Spatial-Spectral WaveletCNN for Hyperspectral Image Classification
Apr 01, 2021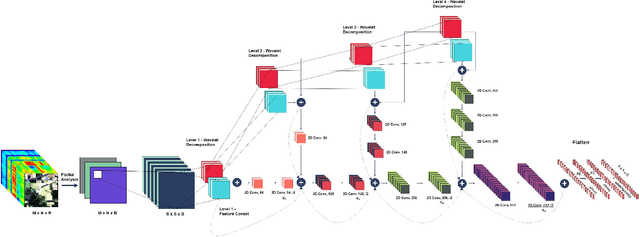
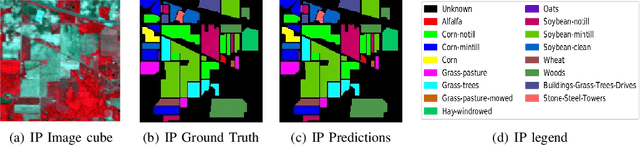
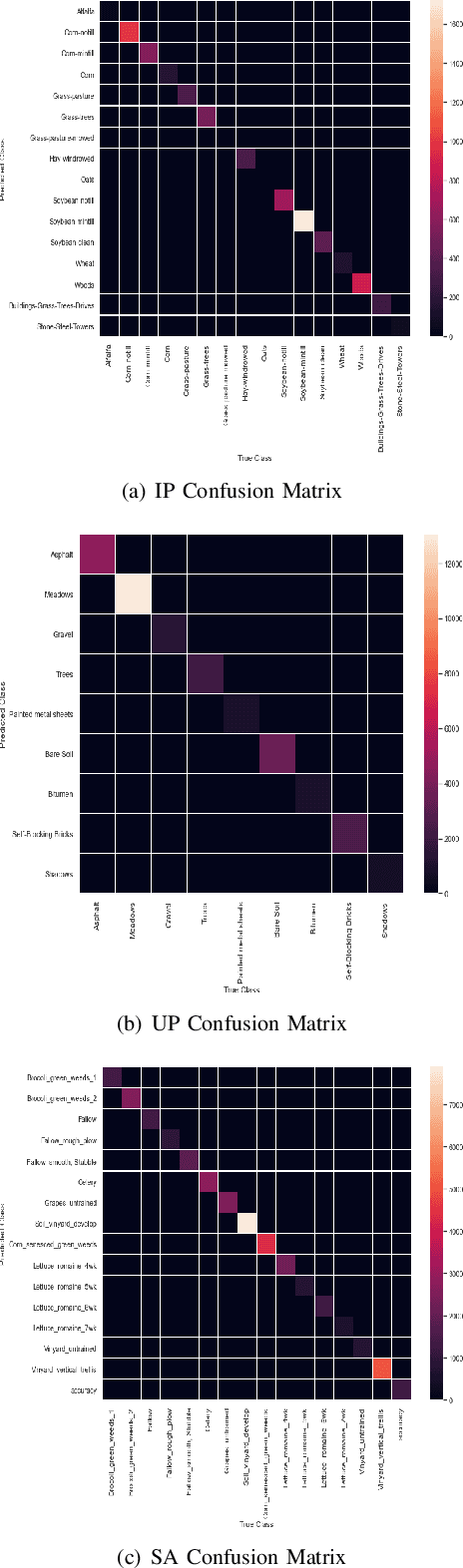

Hyperspectral Image (HSI) classification using Convolutional Neural Networks (CNN) is widely found in the current literature. Approaches vary from using SVMs to 2D CNNs, 3D CNNs, 3D-2D CNNs. Besides 3D-2D CNNs and FuSENet, the other approaches do not consider both the spectral and spatial features together for HSI classification task, thereby resulting in poor performances. 3D CNNs are computationally heavy and are not widely used, while 2D CNNs do not consider multi-resolution processing of images, and only limits itself to the spatial features. Even though 3D-2D CNNs try to model the spectral and spatial features their performance seems limited when applied over multiple dataset. In this article, we propose SpectralNET, a wavelet CNN, which is a variation of 2D CNN for multi-resolution HSI classification. A wavelet CNN uses layers of wavelet transform to bring out spectral features. Computing a wavelet transform is lighter than computing 3D CNN. The spectral features extracted are then connected to the 2D CNN which bring out the spatial features, thereby creating a spatial-spectral feature vector for classification. Overall a better model is achieved that can classify multi-resolution HSI data with high accuracy. Experiments performed with SpectralNET on benchmark dataset, i.e. Indian Pines, University of Pavia, and Salinas Scenes confirm the superiority of proposed SpectralNET with respect to the state-of-the-art methods. The code is publicly available in https://github.com/tanmay-ty/SpectralNET.