 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Generalization Techniques on the Interplay Among Privacy, Utility, and Fairness in Image Classification
Dec 16, 2024
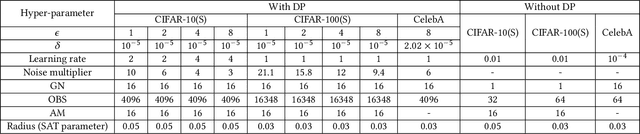


This study investigates the trade-offs between fairness, privacy, and utility in image classification using machine learning (ML). Recent research suggests that generalization techniques can improve the balance between privacy and utility. One focus of this work is sharpness-aware training (SAT) and its integration with differential privacy (DP-SAT) to further improve this balance. Additionally, we examine fairness in both private and non-private learning models trained on datasets with synthetic and real-world biases. We also measure the privacy risks involved in these scenarios by performing membership inference attacks (MIAs) and explore the consequences of eliminating high-privacy risk samples, termed outliers. Moreover, we introduce a new metric, named \emph{harmonic score}, which combines accuracy, privacy, and fairness into a single measure. Through empirical analysis using generalization techniques, we achieve an accuracy of 81.11\% under $(8, 10^{-5})$-DP on CIFAR-10, surpassing the 79.5\% reported by De et al. (2022). Moreover, our experiments show that memorization of training samples can begin before the overfitting point, and generalization techniques do not guarantee the prevention of this memorization. Our analysis of synthetic biases shows that generalization techniques can amplify model bias in both private and non-private models. Additionally, our results indicate that increased bias in training data leads to reduced accuracy, greater vulnerability to privacy attacks, and higher model bias. We validate these findings with the CelebA dataset, demonstrating that similar trends persist with real-world attribute imbalances. Finally, our experiments show that removing outlier data decreases accuracy and further amplifies model bias.
A Cautionary Tale: On the Role of Reference Data in Empirical Privacy Defenses
Oct 18, 2023



Within the realm of privacy-preserving machine learning, empirical privacy defenses have been proposed as a solution to achieve satisfactory levels of training data privacy without a significant drop in model utility. Most existing defenses against membership inference attacks assume access to reference data, defined as an additional dataset coming from the same (or a similar) underlying distribution as training data. Despite the common use of reference data, previous works are notably reticent about defining and evaluating reference data privacy. As gains in model utility and/or training data privacy may come at the expense of reference data privacy, it is essential that all three aspects are duly considered. In this paper, we first examine the availability of reference data and its privacy treatment in previous works and demonstrate its necessity for fairly comparing defenses. Second, we propose a baseline defense that enables the utility-privacy tradeoff with respect to both training and reference data to be easily understood. Our method is formulated as an empirical risk minimization with a constraint on the generalization error, which, in practice, can be evaluated as a weighted empirical risk minimization (WERM) over the training and reference datasets. Although we conceived of WERM as a simple baseline, our experiments show that, surprisingly, it outperforms the most well-studied and current state-of-the-art empirical privacy defenses using reference data for nearly all relative privacy levels of reference and training data. Our investigation also reveals that these existing methods are unable to effectively trade off reference data privacy for model utility and/or training data privacy. Overall, our work highlights the need for a proper evaluation of the triad model utility / training data privacy / reference data privacy when comparing privacy defenses.
An Empirical Analysis of Fairness Notions under Differential Privacy
Feb 06, 2023



Recent works have shown that selecting an optimal model architecture suited to the differential privacy setting is necessary to achieve the best possible utility for a given privacy budget using differentially private stochastic gradient descent (DP-SGD)(Tramer and Boneh 2020; Cheng et al. 2022). In light of these findings, we empirically analyse how different fairness notions, belonging to distinct classes of statistical fairness criteria (independence, separation and sufficiency), are impacted when one selects a model architecture suitable for DP-SGD, optimized for utility. Using standard datasets from ML fairness literature, we show using a rigorous experimental protocol, that by selecting the optimal model architecture for DP-SGD, the differences across groups concerning the relevant fairness metrics (demographic parity, equalized odds and predictive parity) more often decrease or are negligibly impacted, compared to the non-private baseline, for which optimal model architecture has also been selected to maximize utility. These findings challenge the understanding that differential privacy will necessarily exacerbate unfairness in deep learning models trained on biased datasets.