 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-TL: Low-Resource Temporal Knowledge Representation of Planning Instructions Using Chain-of-Thought Reasoning
Oct 21, 2024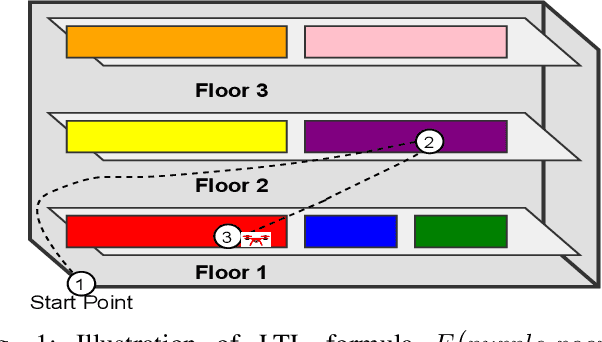
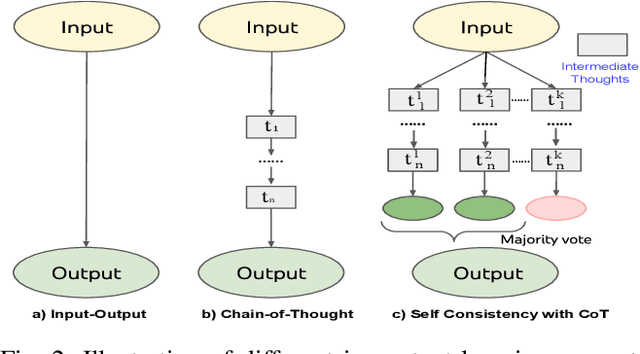
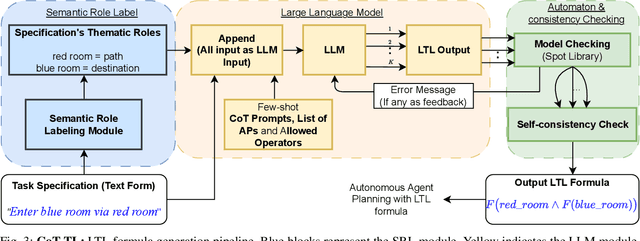
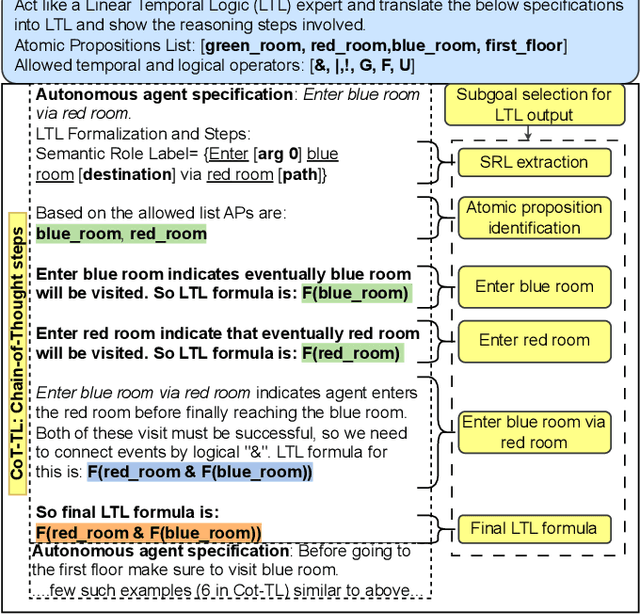
Autonomous agents often face the challenge of interpreting uncertain natural language instructions for planning tasks. Representing these instructions as Linear Temporal Logic (LTL) enables planners to synthesize actionable plans. We introduce CoT-TL, a data-efficient in-context learning framework for translating natural language specifications into LTL representations. CoT-TL addresses the limitations of large language models, which typically rely on extensive fine-tuning data, by extending chain-of-thought reasoning and semantic roles to align with the requirements of formal logic creation. This approach enhances the transparency and rationale behind LTL generation, fostering user trust. CoT-TL achieves state-of-the-art accuracy across three diverse datasets in low-data scenarios, outperforming existing methods without fine-tuning or intermediate translations. To improve reliability and minimize hallucinations, we incorporate model checking to validate the syntax of the generated LTL output. We further demonstrate CoT-TL's effectiveness through ablation studies and evaluations on unseen LTL structures and formulas in a new dataset. Finally, we validate CoT-TL's practicality by integrating it into a QuadCopter for multi-step drone planning based on natural language instructions.
TR2MTL: LLM based framework for Metric Temporal Logic Formalization of Traffic Rules
Jun 09, 2024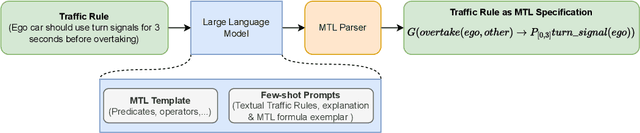


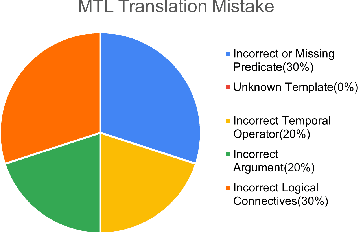
Traffic rules formalization is crucial for verifying the compliance and safety of autonomous vehicles (AVs). However, manual translation of natural language traffic rules as formal specification requires domain knowledge and logic expertise, which limits its adaptation. This paper introduces TR2MTL, a framework that employs large language models (LLMs) to automatically translate traffic rules (TR) into metric temporal logic (MTL). It is envisioned as a human-in-loop system for AV rule formalization. It utilizes a chain-of-thought in-context learning approach to guide the LLM in step-by-step translation and generating valid and grammatically correct MTL formulas. It can be extended to various forms of temporal logic and rules. We evaluated the framework on a challenging dataset of traffic rules we created from various sources and compared it against LLMs using different in-context learning methods. Results show that TR2MTL is domain-agnostic, achieving high accuracy and generalization capability even with a small dataset. Moreover, the method effectively predicts formulas with varying degrees of logical and semantic structure in unstructured traffic rules.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022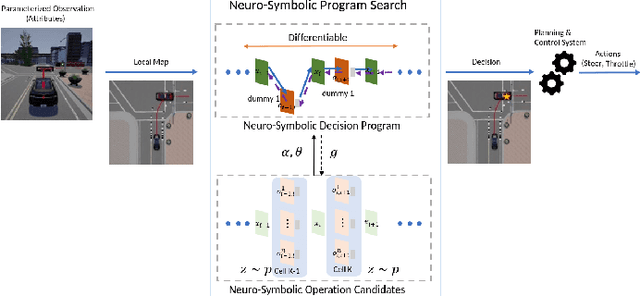
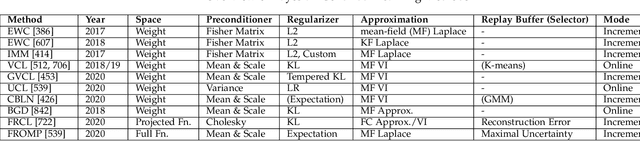
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.