 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxiGAN: Toxic Data Augmentation via LLM-Guided Directional Adversarial Generation
Jan 06, 2026Augmenting toxic language data in a controllable and class-specific manner is crucial for improving robustness in toxicity classification, yet remains challenging due to limited supervision and distributional skew. We propose ToxiGAN, a class-aware text augmentation framework that combines adversarial generation with semantic guidance from large language models (LLMs). To address common issues in GAN-based augmentation such as mode collapse and semantic drift, ToxiGAN introduces a two-step directional training strategy and leverages LLM-generated neutral texts as semantic ballast. Unlike prior work that treats LLMs as static generators, our approach dynamically selects neutral exemplars to provide balanced guidance. Toxic samples are explicitly optimized to diverge from these exemplars, reinforcing class-specific contrastive signals. Experiments on four hate speech benchmarks show that ToxiGAN achieves the strongest average performance in both macro-F1 and hate-F1, consistently outperforming traditional and LLM-based augmentation methods. Ablation and sensitivity analyses further confirm the benefits of semantic ballast and directional training in enhancing classifier robustness.
Designing and Evaluating Malinowski's Lens: An AI-Native Educational Game for Ethnographic Learning
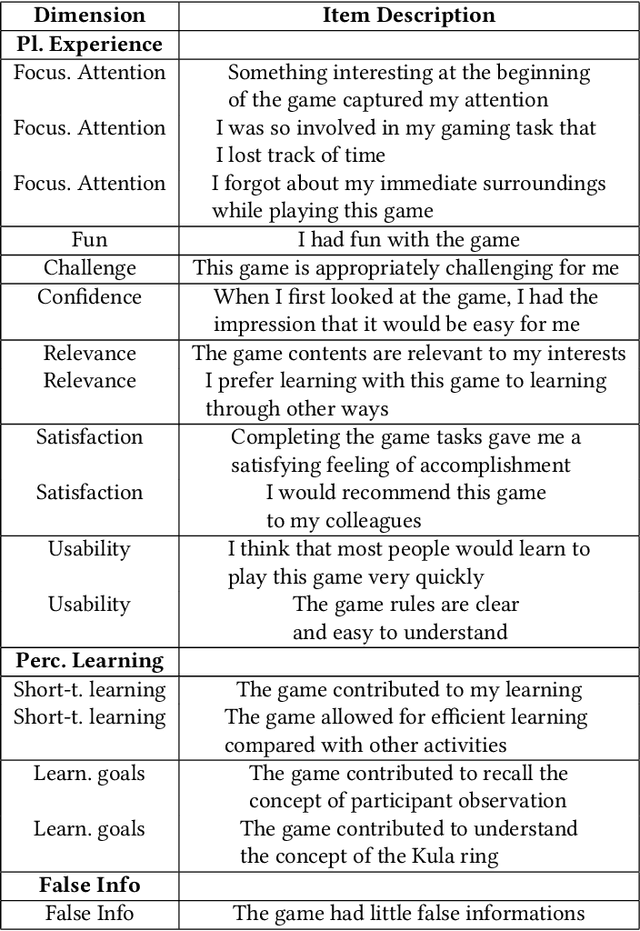
Nov 10, 2025This study introduces 'Malinowski's Lens', the first AI-native educational game for anthropology that transforms Bronislaw Malinowski's 'Argonauts of the Western Pacific' (1922) into an interactive learning experience. The system combines Retrieval-Augmented Generation with DALL-E 3 text-to-image generation, creating consistent VGA-style visuals as players embody Malinowski during his Trobriand Islands fieldwork (1915-1918). To address ethical concerns, indigenous peoples appear as silhouettes while Malinowski is detailed, prompting reflection on anthropological representation. Two validation studies confirmed effectiveness: Study 1 with 10 non-specialists showed strong learning outcomes (average quiz score 7.5/10) and excellent usability (SUS: 83/100). Study 2 with 4 expert anthropologists confirmed pedagogical value, with one senior researcher discovering "new aspects" of Malinowski's work through gameplay. The findings demonstrate that AI-driven educational games can effectively convey complex anthropological concepts while sparking disciplinary curiosity. This study advances AI-native educational game design and provides a replicable model for transforming academic texts into engaging interactive experiences.
Improving Hate Speech Classification with Cross-Taxonomy Dataset Integration
Mar 07, 2025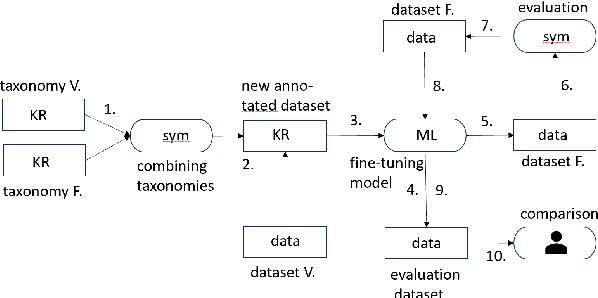
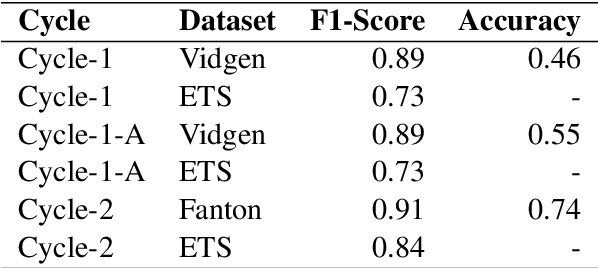

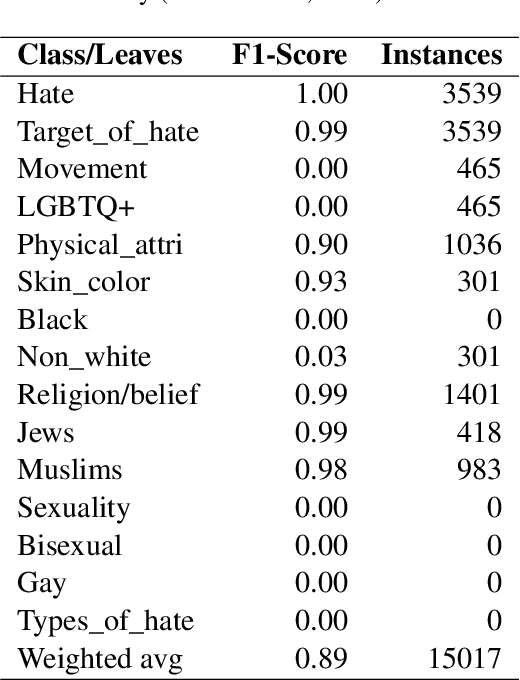
Algorithmic hate speech detection faces significant challenges due to the diverse definitions and datasets used in research and practice. Social media platforms, legal frameworks, and institutions each apply distinct yet overlapping definitions, complicating classification efforts. This study addresses these challenges by demonstrating that existing datasets and taxonomies can be integrated into a unified model, enhancing prediction performance and reducing reliance on multiple specialized classifiers. The work introduces a universal taxonomy and a hate speech classifier capable of detecting a wide range of definitions within a single framework. Our approach is validated by combining two widely used but differently annotated datasets, showing improved classification performance on an independent test set. This work highlights the potential of dataset and taxonomy integration in advancing hate speech detection, increasing efficiency, and ensuring broader applicability across contexts.
Malinowski in the Age of AI: Can large language models create a text game based on an anthropological classic?
Oct 27, 2024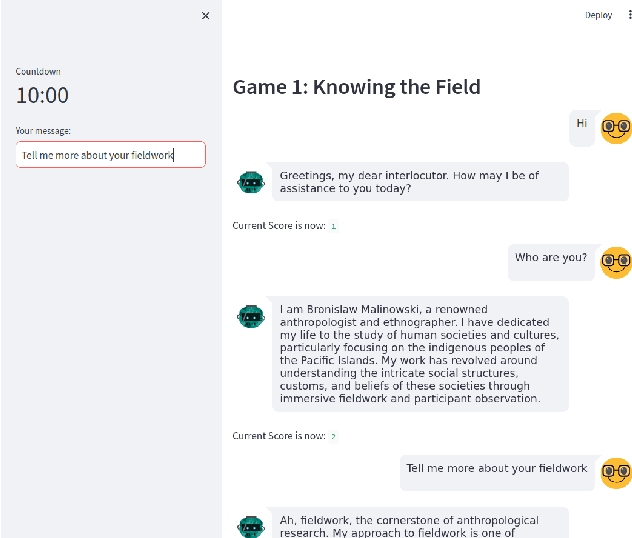

Recent advancements in Large Language Models (LLMs) like ChatGPT and GPT-4 have shown remarkable abilities in a wide range of tasks such as summarizing texts and assisting in coding. Scientific research has demonstrated that these models can also play text-adventure games. This study aims to explore whether LLMs can autonomously create text-based games based on anthropological classics, evaluating also their effectiveness in communicating knowledge. To achieve this, the study engaged anthropologists in discussions to gather their expectations and design inputs for an anthropologically themed game. Through iterative processes following the established HCI principle of 'design thinking', the prompts and the conceptual framework for crafting these games were refined. Leveraging GPT3.5, the study created three prototypes of games centered around the seminal anthropological work of the social anthropologist's Bronislaw Malinowski's "Argonauts of the Western Pacific" (1922). Subsequently, evaluations were conducted by inviting senior anthropologists to playtest these games, and based on their inputs, the game designs were refined. The tests revealed promising outcomes but also highlighted key challenges: the models encountered difficulties in providing in-depth thematic understandings, showed suspectibility to misinformation, tended towards monotonic responses after an extended period of play, and struggled to offer detailed biographical information. Despite these limitations, the study's findings open up new research avenues at the crossroads of artificial intelligence, machine learning, LLMs, ethnography, anthropology and human-computer interaction.
Hateful Messages: A Conversational Data Set of Hate Speech produced by Adolescents on Discord
Sep 04, 2023With the rise of social media, a rise of hateful content can be observed. Even though the understanding and definitions of hate speech varies, platforms, communities, and legislature all acknowledge the problem. Therefore, adolescents are a new and active group of social media users. The majority of adolescents experience or witness online hate speech. Research in the field of automated hate speech classification has been on the rise and focuses on aspects such as bias, generalizability, and performance. To increase generalizability and performance, it is important to understand biases within the data. This research addresses the bias of youth language within hate speech classification and contributes by providing a modern and anonymized hate speech youth language data set consisting of 88.395 annotated chat messages. The data set consists of publicly available online messages from the chat platform Discord. ~6,42% of the messages were classified by a self-developed annotation schema as hate speech. For 35.553 messages, the user profiles provided age annotations setting the average author age to under 20 years old.
User Experience Design for Automatic Credibility Assessment of News Content About COVID-19
Apr 29, 2022
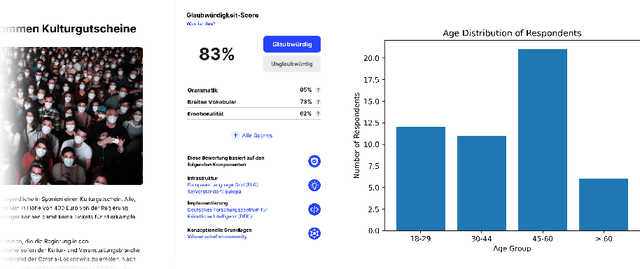
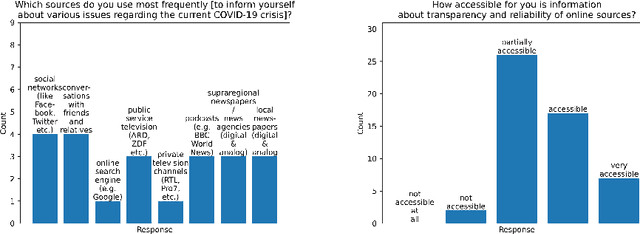
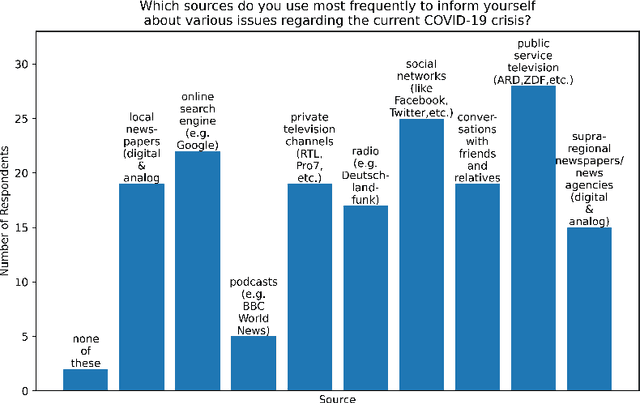
The increasingly rapid spread of information about COVID-19 on the web calls for automatic measures of quality assurance. In that context, we check the credibility of news content using selected linguistic features. We present two empirical studies to evaluate the usability of graphical interfaces that offer such credibility assessment. In a moderated qualitative interview with six participants, we identify rating scale, sub-criteria and algorithm authorship as important predictors of the usability. A subsequent quantitative online survey with 50 participants reveals a conflict between transparency and conciseness in the interface design, as well as a perceived hierarchy of metadata: the authorship of a news text is more important than the authorship of the credibility algorithm used to assess the content quality. Finally, we make suggestions for future research, such as proactively documenting credibility-related metadata for Natural Language Processing and Language Technology services and establishing an explicit hierarchical taxonomy of usability predictors for automatic credibility assessment.