 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateful Messages: A Conversational Data Set of Hate Speech produced by Adolescents on Discord
Sep 04, 2023With the rise of social media, a rise of hateful content can be observed. Even though the understanding and definitions of hate speech varies, platforms, communities, and legislature all acknowledge the problem. Therefore, adolescents are a new and active group of social media users. The majority of adolescents experience or witness online hate speech. Research in the field of automated hate speech classification has been on the rise and focuses on aspects such as bias, generalizability, and performance. To increase generalizability and performance, it is important to understand biases within the data. This research addresses the bias of youth language within hate speech classification and contributes by providing a modern and anonymized hate speech youth language data set consisting of 88.395 annotated chat messages. The data set consists of publicly available online messages from the chat platform Discord. ~6,42% of the messages were classified by a self-developed annotation schema as hate speech. For 35.553 messages, the user profiles provided age annotations setting the average author age to under 20 years old.
TopicsRanksDC: Distance-based Topic Ranking applied on Two-Class Data
May 17, 2021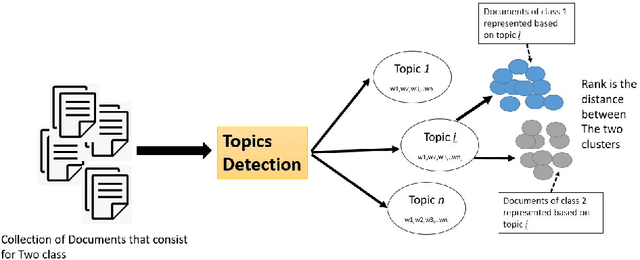
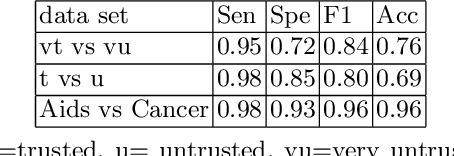
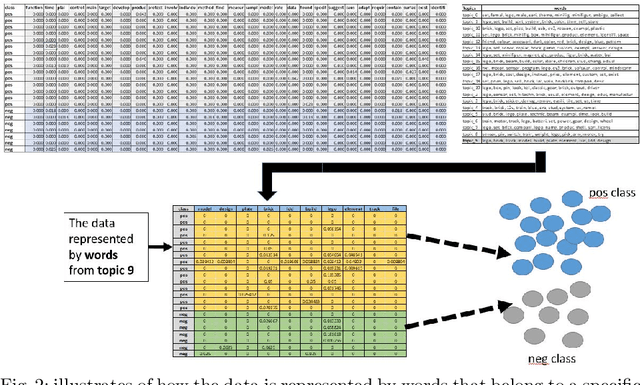

In this paper, we introduce a novel approach named TopicsRanksDC for topics ranking based on the distance between two clusters that are generated by each topic. We assume that our data consists of text documents that are associated with two-classes. Our approach ranks each topic contained in these text documents by its significance for separating the two-classes. Firstly, the algorithm detects topics using Latent Dirichlet Allocation (LDA). The words defining each topic are represented as two clusters, where each one is associated with one of the classes. We compute four distance metrics, Single Linkage, Complete Linkage, Average Linkage and distance between the centroid. We compare the results of LDA topics and random topics. The results show that the rank for LDA topics is much higher than random topics. The results of TopicsRanksDC tool are promising for future work to enable search engines to suggest related topics.
* 10 pages, 5 figures
AI supported Topic Modeling using KNIME-Workflows
Apr 15, 2021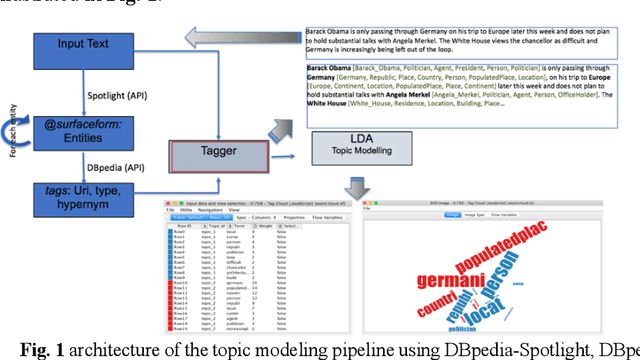
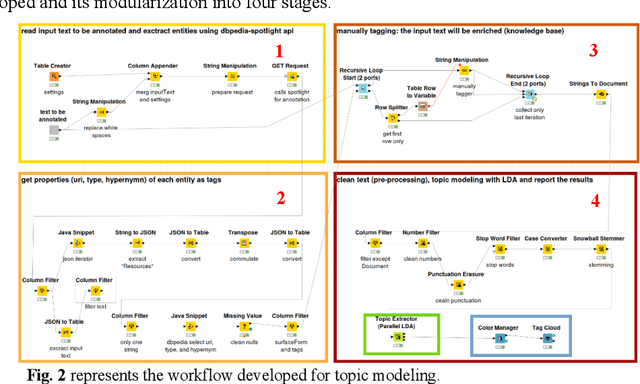

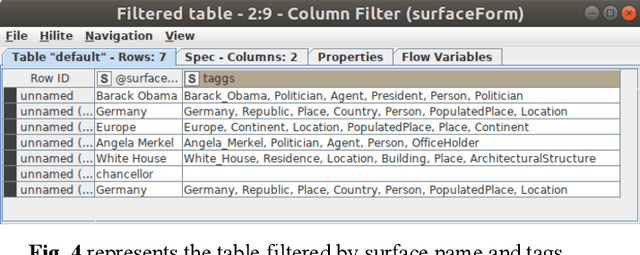
Topic modeling algorithms traditionally model topics as list of weighted terms. These topic models can be used effectively to classify texts or to support text mining tasks such as text summarization or fact extraction. The general procedure relies on statistical analysis of term frequencies. The focus of this work is on the implementation of the knowledge-based topic modelling services in a KNIME workflow. A brief description and evaluation of the DBPedia-based enrichment approach and the comparative evaluation of enriched topic models will be outlined based on our previous work. DBpedia-Spotlight is used to identify entities in the input text and information from DBpedia is used to extend these entities. We provide a workflow developed in KNIME implementing this approach and perform a result comparison of topic modeling supported by knowledge base information to traditional LDA. This topic modeling approach allows semantic interpretation both by algorithms and by humans.
ROC: An Ontology for Country Responses towards COVID-19
Apr 15, 2021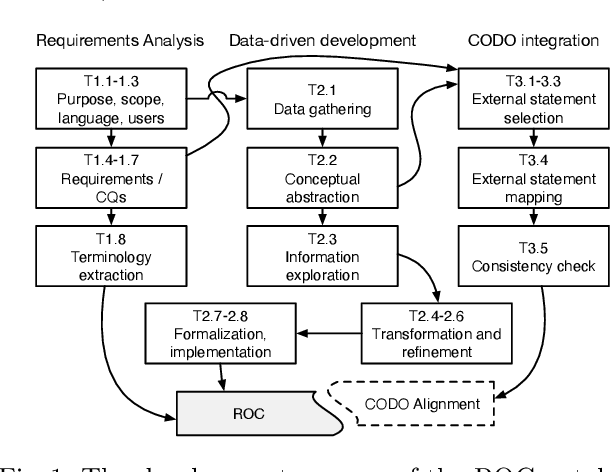
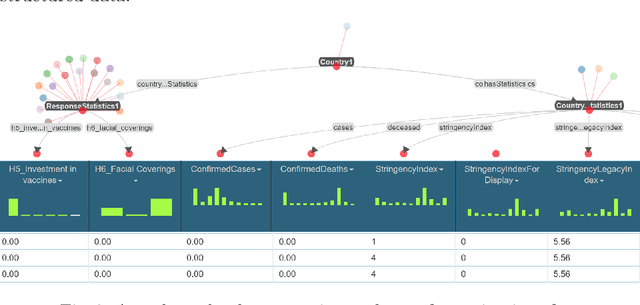

The ROC ontology for country responses to COVID-19 provides a model for collecting, linking and sharing data on the COVID-19 pandemic. It follows semantic standardization (W3C standards RDF, OWL, SPARQL) for the representation of concepts and creation of vocabularies. ROC focuses on country measures and enables the integration of data from heterogeneous data sources. The proposed ontology is intended to facilitate statistical analysis to study and evaluate the effectiveness and side effects of government responses to COVID-19 in different countries. The ontology contains data collected by OxCGRT from publicly available information. This data has been compiled from information provided by ECDC for most countries, as well as from various repositories used to collect data on COVID-19.
* 10 pages, 3 figures