 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopicsRanksDC: Distance-based Topic Ranking applied on Two-Class Data
Paper and Code
May 17, 2021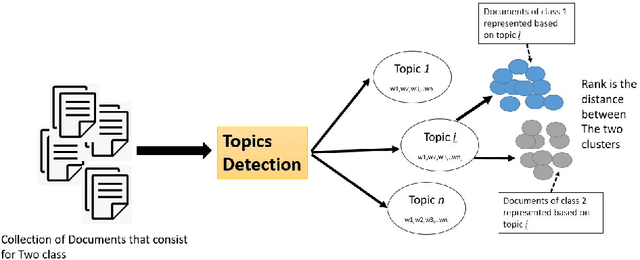
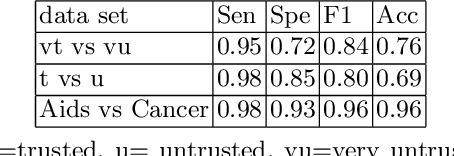
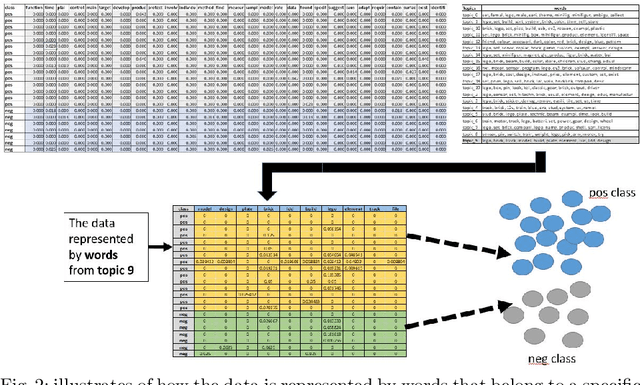

In this paper, we introduce a novel approach named TopicsRanksDC for topics ranking based on the distance between two clusters that are generated by each topic. We assume that our data consists of text documents that are associated with two-classes. Our approach ranks each topic contained in these text documents by its significance for separating the two-classes. Firstly, the algorithm detects topics using Latent Dirichlet Allocation (LDA). The words defining each topic are represented as two clusters, where each one is associated with one of the classes. We compute four distance metrics, Single Linkage, Complete Linkage, Average Linkage and distance between the centroid. We compare the results of LDA topics and random topics. The results show that the rank for LDA topics is much higher than random topics. The results of TopicsRanksDC tool are promising for future work to enable search engines to suggest related topics.