 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Language Models for Continual Relation Extraction
Paper and Code
Apr 07, 2025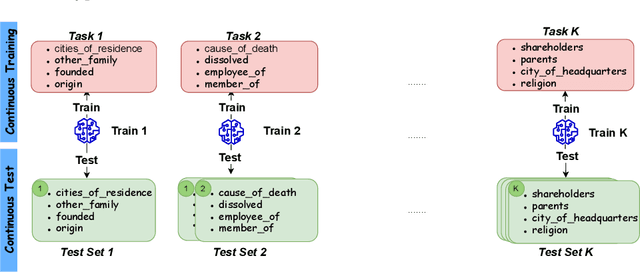
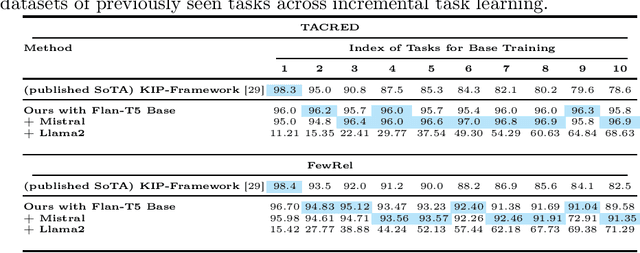

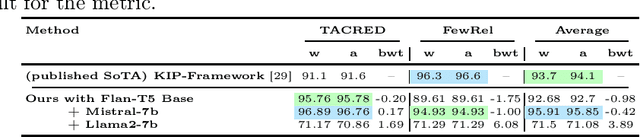
Real-world data, such as news articles, social media posts, and chatbot conversations, is inherently dynamic and non-stationary, presenting significant challenges for constructing real-time structured representations through knowledge graphs (KGs). Relation Extraction (RE), a fundamental component of KG creation, often struggles to adapt to evolving data when traditional models rely on static, outdated datasets. Continual Relation Extraction (CRE) methods tackle this issue by incrementally learning new relations while preserving previously acquired knowledge. This study investigates the application of pre-trained language models (PLMs), specifically large language models (LLMs), to CRE, with a focus on leveraging memory replay to address catastrophic forgetting. We evaluate decoder-only models (eg, Mistral-7B and Llama2-7B) and encoder-decoder models (eg, Flan-T5 Base) on the TACRED and FewRel datasets. Task-incremental fine-tuning of LLMs demonstrates superior performance over earlier approaches using encoder-only models like BERT on TACRED, excelling in seen-task accuracy and overall performance (measured by whole and average accuracy), particularly with the Mistral and Flan-T5 models. Results on FewRel are similarly promising, achieving second place in whole and average accuracy metrics. This work underscores critical factors in knowledge transfer, language model architecture, and KG completeness, advancing CRE with LLMs and memory replay for dynamic, real-time relation extraction.