 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvalQReason: A Framework for Step-Level Reasoning Evaluation in Large Language Models
Feb 02, 2026Large Language Models (LLMs) are increasingly deployed in critical applications requiring reliable reasoning, yet their internal reasoning processes remain difficult to evaluate systematically. Existing methods focus on final-answer correctness, providing limited insight into how reasoning unfolds across intermediate steps. We present EvalQReason, a framework that quantifies LLM reasoning quality through step-level probability distribution analysis without requiring human annotation. The framework introduces two complementary algorithms: Consecutive Step Divergence (CSD), which measures local coherence between adjacent reasoning steps, and Step-to-Final Convergence (SFC), which assesses global alignment with final answers. Each algorithm employs five statistical metrics to capture reasoning dynamics. Experiments across mathematical and medical datasets with open-source 7B-parameter models demonstrate that CSD-based features achieve strong predictive performance for correctness classification, with classical machine learning models reaching F1=0.78 and ROC-AUC=0.82, and sequential neural models substantially improving performance (F1=0.88, ROC-AUC=0.97). CSD consistently outperforms SFC, and sequential architectures outperform classical machine learning approaches. Critically, reasoning dynamics prove domain-specific: mathematical reasoning exhibits clear divergence-based discrimination patterns between correct and incorrect solutions, while medical reasoning shows minimal discriminative signals, revealing fundamental differences in how LLMs process different reasoning types. EvalQReason enables scalable, process-aware evaluation of reasoning reliability, establishing probability-based divergence analysis as a principled approach for trustworthy AI deployment.
GC-Fed: Gradient Centralized Federated Learning with Partial Client Participation
Mar 17, 2025Multi-source information fusion (MSIF) leverages diverse data streams to enhance decision-making, situational awareness, and system resilience. Federated Learning (FL) enables MSIF while preserving privacy but suffers from client drift under high data heterogeneity, leading to performance degradation. Traditional mitigation strategies rely on reference-based gradient adjustments, which can be unstable in partial participation settings. To address this, we propose Gradient Centralized Federated Learning (GC-Fed), a reference-free gradient correction method inspired by Gradient Centralization (GC). We introduce Local GC and Global GC, applying GC during local training and global aggregation, respectively. Our hybrid GC-Fed approach selectively applies GC at the feature extraction layer locally and at the classifier layer globally, improving training stability and model performance. Theoretical analysis and empirical results demonstrate that GC-Fed mitigates client drift and achieves state-of-the-art accuracy gains of up to 20% in heterogeneous settings.
PriCE: Privacy-Preserving and Cost-Effective Scheduling for Parallelizing the Large Medical Image Processing Workflow over Hybrid Clouds
May 24, 2024


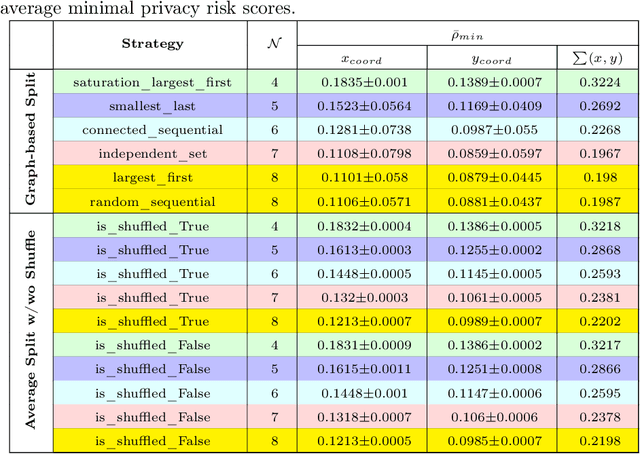
Running deep neural networks for large medical images is a resource-hungry and time-consuming task with centralized computing. Outsourcing such medical image processing tasks to hybrid clouds has benefits, such as a significant reduction of execution time and monetary cost. However, due to privacy concerns, it is still challenging to process sensitive medical images over clouds, which would hinder their deployment in many real-world applications. To overcome this, we first formulate the overall optimization objectives of the privacy-preserving distributed system model, i.e., minimizing the amount of information about the private data learned by the adversaries throughout the process, reducing the maximum execution time and cost under the user budget constraint. We propose a novel privacy-preserving and cost-effective method called PriCE to solve this multi-objective optimization problem. We performed extensive simulation experiments for artifact detection tasks on medical images using an ensemble of five deep convolutional neural network inferences as the workflow task. Experimental results show that PriCE successfully splits a wide range of input gigapixel medical images with graph-coloring-based strategies, yielding desired output utility and lowering the privacy risk, makespan, and monetary cost under user's budget.
FedShift: Tackling Dual Heterogeneity Problem of Federated Learning via Weight Shift Aggregation
Feb 02, 2024Federated Learning (FL) offers a compelling method for training machine learning models with a focus on preserving data privacy. The presence of system heterogeneity and statistical heterogeneity, recognized challenges in FL, arises from the diversity of client hardware, network, and dataset distribution. This diversity can critically affect the training pace and the performance of models. While many studies address either system or statistical heterogeneity by introducing communication-efficient or stable convergence algorithms, addressing these challenges in isolation often leads to compromises due to unaddressed heterogeneity. In response, this paper introduces FedShift, a novel algorithm designed to enhance both the training speed and the models' accuracy in a dual heterogeneity scenario. Our solution can improve client engagement through quantization and mitigate the adverse effects on performance typically associated with quantization by employing a shifting technique. This technique has proven to enhance accuracy by an average of 3.9% in diverse heterogeneity environments.
Precision in Building Extraction: Comparing Shallow and Deep Models using LiDAR Data
Sep 21, 2023



Building segmentation is essential in infrastructure development, population management, and geological observations. This article targets shallow models due to their interpretable nature to assess the presence of LiDAR data for supervised segmentation. The benchmark data used in this article are published in NORA MapAI competition for deep learning model. Shallow models are compared with deep learning models based on Intersection over Union (IoU) and Boundary Intersection over Union (BIoU). In the proposed work, boundary masks from the original mask are generated to improve the BIoU score, which relates to building shapes' borderline. The influence of LiDAR data is tested by training the model with only aerial images in task 1 and a combination of aerial and LiDAR data in task 2 and then compared. shallow models outperform deep learning models in IoU by 8% using aerial images (task 1) only and 2% in combined aerial images and LiDAR data (task 2). In contrast, deep learning models show better performance on BIoU scores. Boundary masks improve BIoU scores by 4% in both tasks. Light Gradient-Boosting Machine (LightGBM) performs better than RF and Extreme Gradient Boosting (XGBoost).
A Comprehensive Study on Dataset Distillation: Performance, Privacy, Robustness and Fairness
May 05, 2023
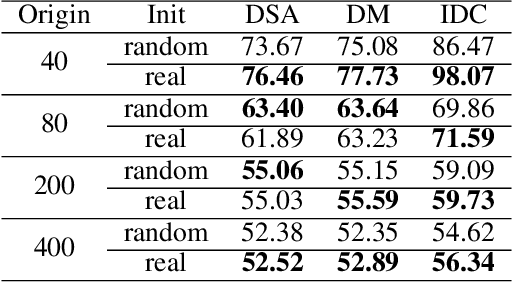
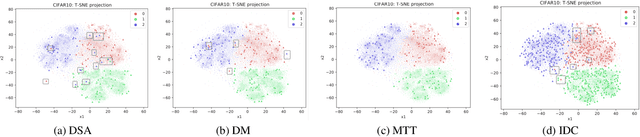
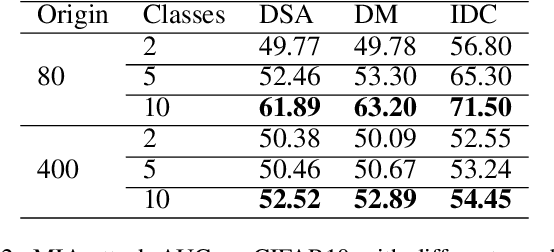
The aim of dataset distillation is to encode the rich features of an original dataset into a tiny dataset. It is a promising approach to accelerate neural network training and related studies. Different approaches have been proposed to improve the informativeness and generalization performance of distilled images. However, no work has comprehensively analyzed this technique from a security perspective and there is a lack of systematic understanding of potential risks. In this work, we conduct extensive experiments to evaluate current state-of-the-art dataset distillation methods. We successfully use membership inference attacks to show that privacy risks still remain. Our work also demonstrates that dataset distillation can cause varying degrees of impact on model robustness and amplify model unfairness across classes when making predictions. This work offers a large-scale benchmarking framework for dataset distillation evaluation.
A Survey on Dataset Distillation: Approaches, Applications and Future Directions
May 03, 2023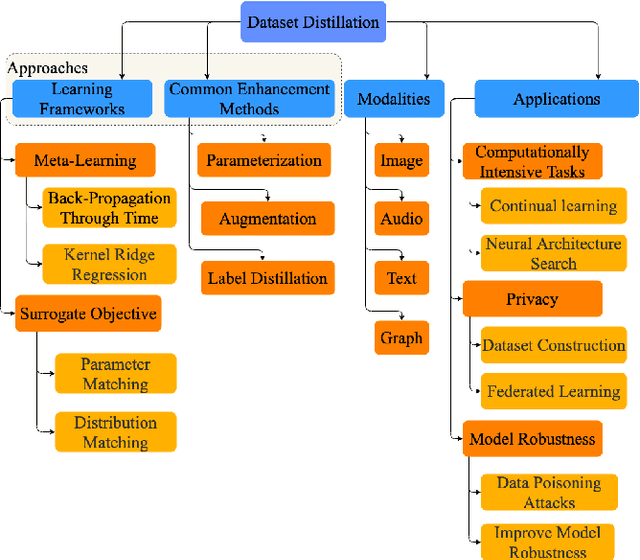
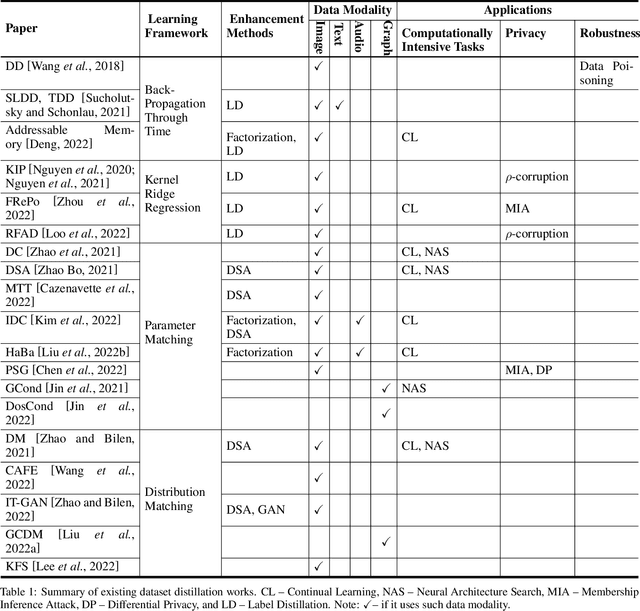

Dataset distillation is attracting more attention in machine learning as training sets continue to grow and the cost of training state-of-the-art models becomes increasingly high. By synthesizing datasets with high information density, dataset distillation offers a range of potential applications, including support for continual learning, neural architecture search, and privacy protection. Despite recent advances, we lack a holistic understanding of the approaches and applications. Our survey aims to bridge this gap by first proposing a taxonomy of dataset distillation, characterizing existing approaches, and then systematically reviewing the data modalities, and related applications. In addition, we summarize the challenges and discuss future directions for this field of research.
Towards General Deep Leakage in Federated Learning
Oct 18, 2021

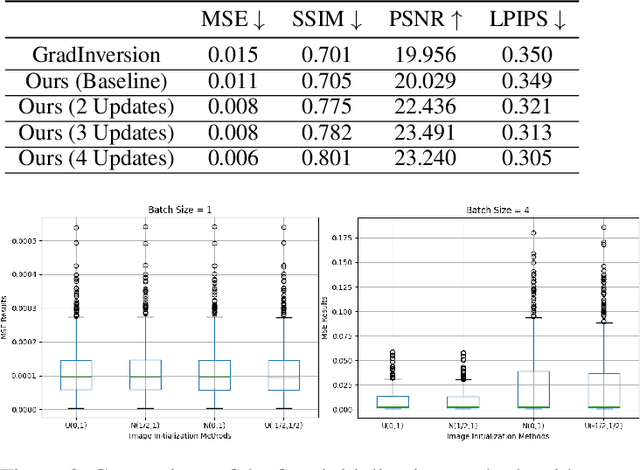
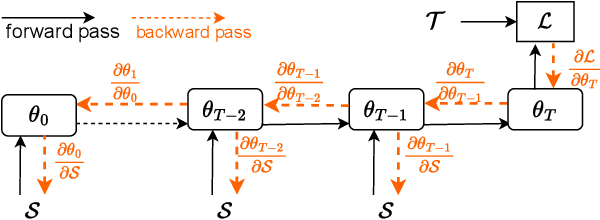
Unlike traditional central training, federated learning (FL) improves the performance of the global model by sharing and aggregating local models rather than local data to protect the users' privacy. Although this training approach appears secure, some research has demonstrated that an attacker can still recover private data based on the shared gradient information. This on-the-fly reconstruction attack deserves to be studied in depth because it can occur at any stage of training, whether at the beginning or at the end of model training; no relevant dataset is required and no additional models need to be trained. We break through some unrealistic assumptions and limitations to apply this reconstruction attack in a broader range of scenarios. We propose methods that can reconstruct the training data from shared gradients or weights, corresponding to the FedSGD and FedAvg usage scenarios, respectively. We propose a zero-shot approach to restore labels even if there are duplicate labels in the batch. We study the relationship between the label and image restoration. We find that image restoration fails even if there is only one incorrectly inferred label in the batch; we also find that when batch images have the same label, the corresponding image is restored as a fusion of that class of images. Our approaches are evaluated on classic image benchmarks, including CIFAR-10 and ImageNet. The batch size, image quality, and the adaptability of the label distribution of our approach exceed those of GradInversion, the state-of-the-art.
DID-eFed: Facilitating Federated Learning as a Service with Decentralized Identities
May 19, 2021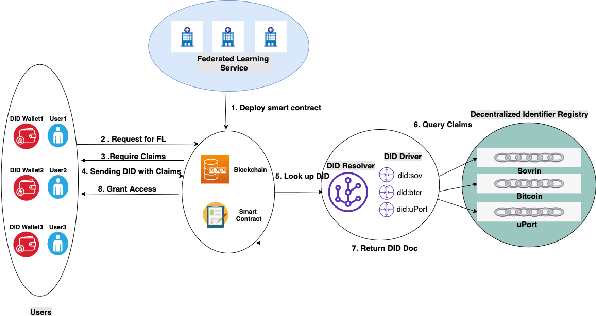
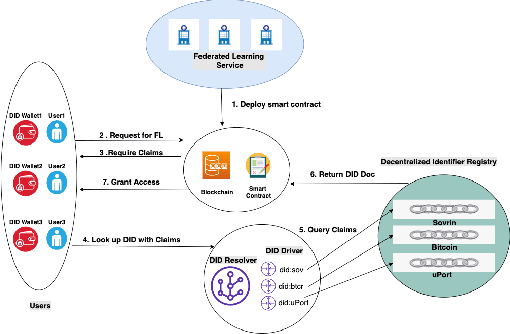
We have entered the era of big data, and it is considered to be the "fuel" for the flourishing of artificial intelligence applications. The enactment of the EU General Data Protection Regulation (GDPR) raises concerns about individuals' privacy in big data. Federated learning (FL) emerges as a functional solution that can help build high-performance models shared among multiple parties while still complying with user privacy and data confidentiality requirements. Although FL has been intensively studied and used in real applications, there is still limited research related to its prospects and applications as a FLaaS (Federated Learning as a Service) to interested 3rd parties. In this paper, we present a FLaaS system: DID-eFed, where FL is facilitated by decentralized identities (DID) and a smart contract. DID enables a more flexible and credible decentralized access management in our system, while the smart contract offers a frictionless and less error-prone process. We describe particularly the scenario where our DID-eFed enables the FLaaS among hospitals and research institutions.