 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconsciously Forget: Mitigating Memorization; Without Knowing What is being Memorized
Dec 12, 2025Recent advances in generative models have demonstrated an exceptional ability to produce highly realistic images. However, previous studies show that generated images often resemble the training data, and this problem becomes more severe as the model size increases. Memorizing training data can lead to legal challenges, including copyright infringement, violations of portrait rights, and trademark violations. Existing approaches to mitigating memorization mainly focus on manipulating the denoising sampling process to steer image embeddings away from the memorized embedding space or employ unlearning methods that require training on datasets containing specific sets of memorized concepts. However, existing methods often incur substantial computational overhead during sampling, or focus narrowly on removing one or more groups of target concepts, imposing a significant limitation on their scalability. To understand and mitigate these problems, our work, UniForget, offers a new perspective on understanding the root cause of memorization. Our work demonstrates that specific parts of the model are responsible for copyrighted content generation. By applying model pruning, we can effectively suppress the probability of generating copyrighted content without targeting specific concepts while preserving the general generative capabilities of the model. Additionally, we show that our approach is both orthogonal and complementary to existing unlearning methods, thereby highlighting its potential to improve current unlearning and de-memorization techniques.
LogicAD: Explainable Anomaly Detection via VLM-based Text Feature Extraction
Jan 08, 2025

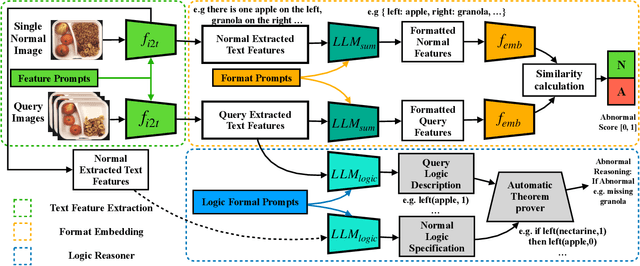
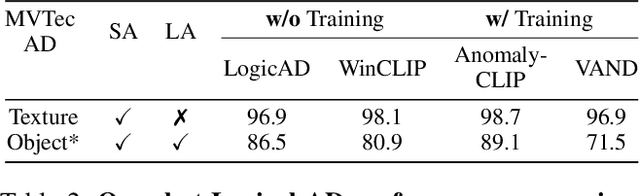
Logical image understanding involves interpreting and reasoning about the relationships and consistency within an image's visual content. This capability is essential in applications such as industrial inspection, where logical anomaly detection is critical for maintaining high-quality standards and minimizing costly recalls. Previous research in anomaly detection (AD) has relied on prior knowledge for designing algorithms, which often requires extensive manual annotations, significant computing power, and large amounts of data for training. Autoregressive, multimodal Vision Language Models (AVLMs) offer a promising alternative due to their exceptional performance in visual reasoning across various domains. Despite this, their application to logical AD remains unexplored. In this work, we investigate using AVLMs for logical AD and demonstrate that they are well-suited to the task. Combining AVLMs with format embedding and a logic reasoner, we achieve SOTA performance on public benchmarks, MVTec LOCO AD, with an AUROC of 86.0% and F1-max of 83.7%, along with explanations of anomalies. This significantly outperforms the existing SOTA method by a large margin.
Towards General Deep Leakage in Federated Learning
Oct 18, 2021

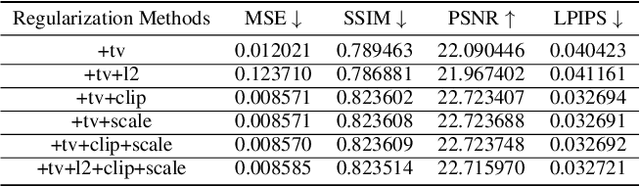
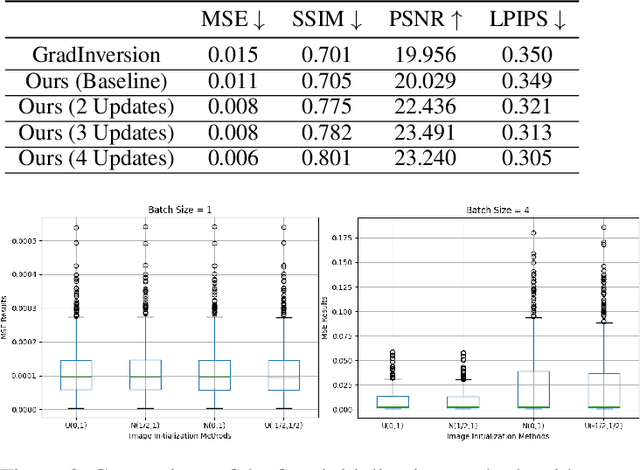
Unlike traditional central training, federated learning (FL) improves the performance of the global model by sharing and aggregating local models rather than local data to protect the users' privacy. Although this training approach appears secure, some research has demonstrated that an attacker can still recover private data based on the shared gradient information. This on-the-fly reconstruction attack deserves to be studied in depth because it can occur at any stage of training, whether at the beginning or at the end of model training; no relevant dataset is required and no additional models need to be trained. We break through some unrealistic assumptions and limitations to apply this reconstruction attack in a broader range of scenarios. We propose methods that can reconstruct the training data from shared gradients or weights, corresponding to the FedSGD and FedAvg usage scenarios, respectively. We propose a zero-shot approach to restore labels even if there are duplicate labels in the batch. We study the relationship between the label and image restoration. We find that image restoration fails even if there is only one incorrectly inferred label in the batch; we also find that when batch images have the same label, the corresponding image is restored as a fusion of that class of images. Our approaches are evaluated on classic image benchmarks, including CIFAR-10 and ImageNet. The batch size, image quality, and the adaptability of the label distribution of our approach exceed those of GradInversion, the state-of-the-art.