 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconsciously Forget: Mitigating Memorization; Without Knowing What is being Memorized
Dec 12, 2025Recent advances in generative models have demonstrated an exceptional ability to produce highly realistic images. However, previous studies show that generated images often resemble the training data, and this problem becomes more severe as the model size increases. Memorizing training data can lead to legal challenges, including copyright infringement, violations of portrait rights, and trademark violations. Existing approaches to mitigating memorization mainly focus on manipulating the denoising sampling process to steer image embeddings away from the memorized embedding space or employ unlearning methods that require training on datasets containing specific sets of memorized concepts. However, existing methods often incur substantial computational overhead during sampling, or focus narrowly on removing one or more groups of target concepts, imposing a significant limitation on their scalability. To understand and mitigate these problems, our work, UniForget, offers a new perspective on understanding the root cause of memorization. Our work demonstrates that specific parts of the model are responsible for copyrighted content generation. By applying model pruning, we can effectively suppress the probability of generating copyrighted content without targeting specific concepts while preserving the general generative capabilities of the model. Additionally, we show that our approach is both orthogonal and complementary to existing unlearning methods, thereby highlighting its potential to improve current unlearning and de-memorization techniques.
LogicAD: Explainable Anomaly Detection via VLM-based Text Feature Extraction
Jan 08, 2025

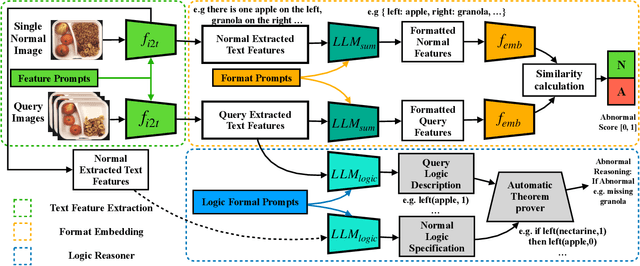
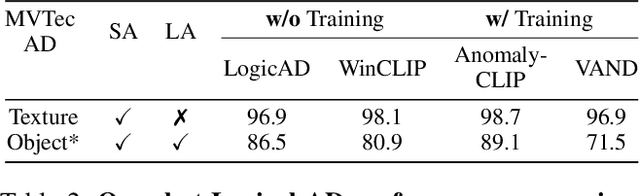
Logical image understanding involves interpreting and reasoning about the relationships and consistency within an image's visual content. This capability is essential in applications such as industrial inspection, where logical anomaly detection is critical for maintaining high-quality standards and minimizing costly recalls. Previous research in anomaly detection (AD) has relied on prior knowledge for designing algorithms, which often requires extensive manual annotations, significant computing power, and large amounts of data for training. Autoregressive, multimodal Vision Language Models (AVLMs) offer a promising alternative due to their exceptional performance in visual reasoning across various domains. Despite this, their application to logical AD remains unexplored. In this work, we investigate using AVLMs for logical AD and demonstrate that they are well-suited to the task. Combining AVLMs with format embedding and a logic reasoner, we achieve SOTA performance on public benchmarks, MVTec LOCO AD, with an AUROC of 86.0% and F1-max of 83.7%, along with explanations of anomalies. This significantly outperforms the existing SOTA method by a large margin.
Effortless Efficiency: Low-Cost Pruning of Diffusion Models
Dec 03, 2024Diffusion models have achieved impressive advancements in various vision tasks. However, these gains often rely on increasing model size, which escalates computational complexity and memory demands, complicating deployment, raising inference costs, and causing environmental impact. While some studies have explored pruning techniques to improve the memory efficiency of diffusion models, most existing methods require extensive retraining to retain the model performance. Retraining a modern large diffusion model is extremely costly and resource-intensive, which limits the practicality of these methods. In this work, we achieve low-cost diffusion pruning without retraining by proposing a model-agnostic structural pruning framework for diffusion models that learns a differentiable mask to sparsify the model. To ensure effective pruning that preserves the quality of the final denoised latent, we design a novel end-to-end pruning objective that spans the entire diffusion process. As end-to-end pruning is memory-intensive, we further propose time step gradient checkpointing, a technique that significantly reduces memory usage during optimization, enabling end-to-end pruning within a limited memory budget. Results on state-of-the-art U-Net diffusion models SDXL and diffusion transformers (FLUX) demonstrate that our method can effectively prune up to 20% parameters with minimal perceptible performance degradation, and notably, without the need for model retraining. We also showcase that our method can still prune on top of time step distilled diffusion models.