 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism
Jun 05, 2026Current Vision-Language Models struggle with hours-long videos because processing full-length visual sequences induces prohibitive token explosion and attention dilution. To overcome this, we introduce MemDreamer to decouple perception and reasoning, shifting long-video understanding into an agentic exploration process. As a plug-and-play framework, it incrementally streams videos to construct a Hierarchical Graph Memory, a top-down three-tier architecture for semantic abstraction, anchored by a foundational graph capturing spatiotemporal and causal relations. During inference, the reasoning model employs agentic tool-augmented retrieval, navigating hierarchies, searching nodes, and traversing logical edges via an Observation-Reason-Action loop. Experiments show MemDreamer achieves SOTA results across four mainstream benchmarks, narrowing the gap with human experts to only 3.7 points. It constrains the reasoning context window to merely 2% of full-context ingestion while delivering a 12.5 point absolute accuracy gain. Furthermore, statistical analysis uncovers a strong positive linear correlation between an VLM's performance on logic reasoning and long-video understanding benchmarks, establishing agentic capability scaling as a new paradigm for multimodal comprehension.
Large-Scale Multidimensional Knowledge Profiling of Scientific Literature
Jan 21, 2026The rapid expansion of research across machine learning, vision, and language has produced a volume of publications that is increasingly difficult to synthesize. Traditional bibliometric tools rely mainly on metadata and offer limited visibility into the semantic content of papers, making it hard to track how research themes evolve over time or how different areas influence one another. To obtain a clearer picture of recent developments, we compile a unified corpus of more than 100,000 papers from 22 major conferences between 2020 and 2025 and construct a multidimensional profiling pipeline to organize and analyze their textual content. By combining topic clustering, LLM-assisted parsing, and structured retrieval, we derive a comprehensive representation of research activity that supports the study of topic lifecycles, methodological transitions, dataset and model usage patterns, and institutional research directions. Our analysis highlights several notable shifts, including the growth of safety, multimodal reasoning, and agent-oriented studies, as well as the gradual stabilization of areas such as neural machine translation and graph-based methods. These findings provide an evidence-based view of how AI research is evolving and offer a resource for understanding broader trends and identifying emerging directions. Code and dataset: https://github.com/xzc-zju/Profiling_Scientific_Literature
Learning Implicit Body Representations from Double Diffusion Based Neural Radiance Fields
Jan 17, 2022
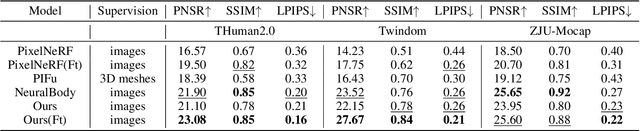
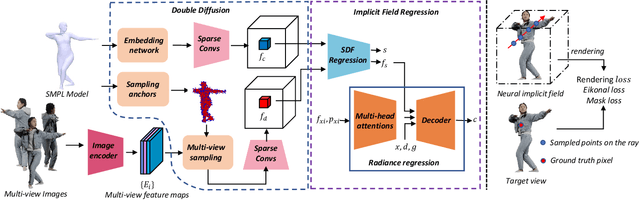
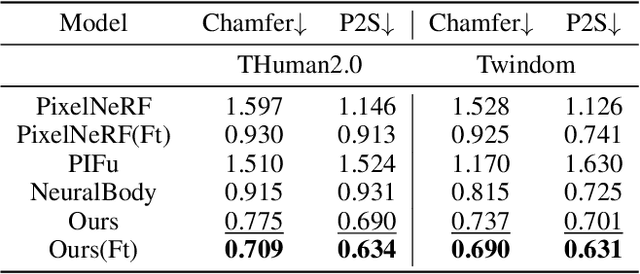
In this paper, we present a novel double diffusion based neural radiance field, dubbed DD-NeRF, to reconstruct human body geometry and render the human body appearance in novel views from a sparse set of images. We first propose a double diffusion mechanism to achieve expressive representations of input images by fully exploiting human body priors and image appearance details at two levels. At the coarse level, we first model the coarse human body poses and shapes via an unclothed 3D deformable vertex model as guidance. At the fine level, we present a multi-view sampling network to capture subtle geometric deformations and image detailed appearances, such as clothing and hair, from multiple input views. Considering the sparsity of the two level features, we diffuse them into feature volumes in the canonical space to construct neural radiance fields. Then, we present a signed distance function (SDF) regression network to construct body surfaces from the diffused features. Thanks to our double diffused representations, our method can even synthesize novel views of unseen subjects. Experiments on various datasets demonstrate that our approach outperforms the state-of-the-art in both geometric reconstruction and novel view synthesis.
One-shot Face Reenactment Using Appearance Adaptive Normalization
Feb 20, 2021
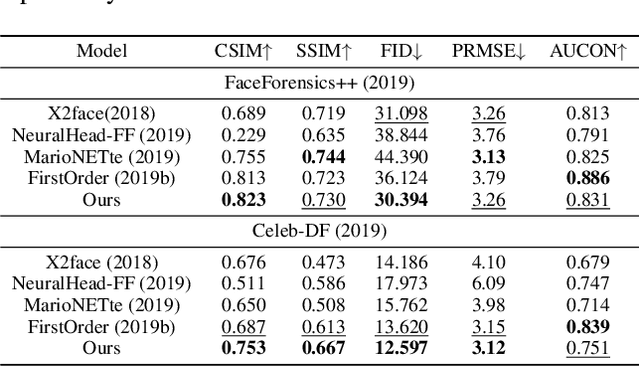
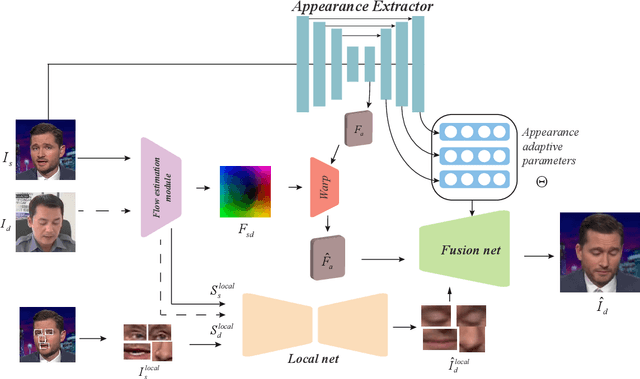
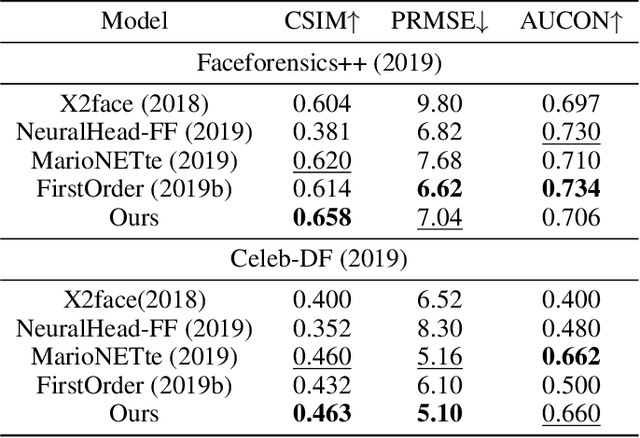
The paper proposes a novel generative adversarial network for one-shot face reenactment, which can animate a single face image to a different pose-and-expression (provided by a driving image) while keeping its original appearance. The core of our network is a novel mechanism called appearance adaptive normalization, which can effectively integrate the appearance information from the input image into our face generator by modulating the feature maps of the generator using the learned adaptive parameters. Furthermore, we specially design a local net to reenact the local facial components (i.e., eyes, nose and mouth) first, which is a much easier task for the network to learn and can in turn provide explicit anchors to guide our face generator to learn the global appearance and pose-and-expression. Extensive quantitative and qualitative experiments demonstrate the significant efficacy of our model compared with prior one-shot methods.
Mesh Guided One-shot Face Reenactment using Graph Convolutional Networks
Sep 18, 2020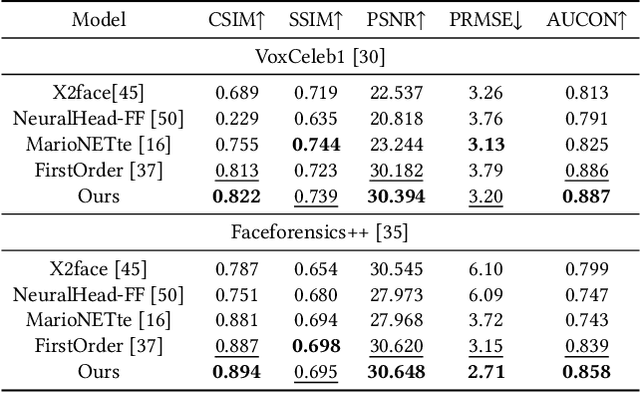
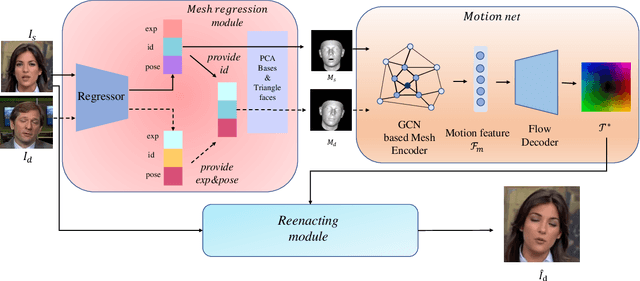
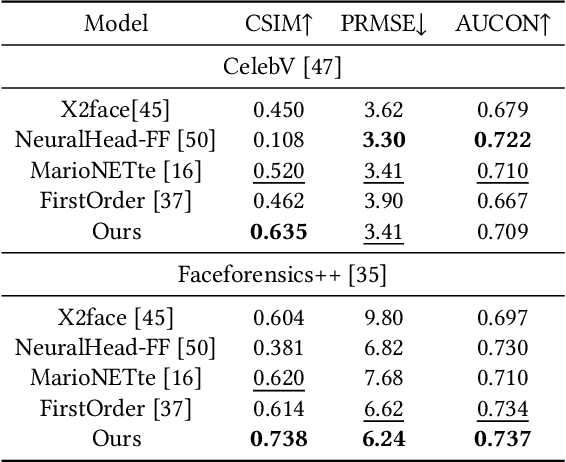
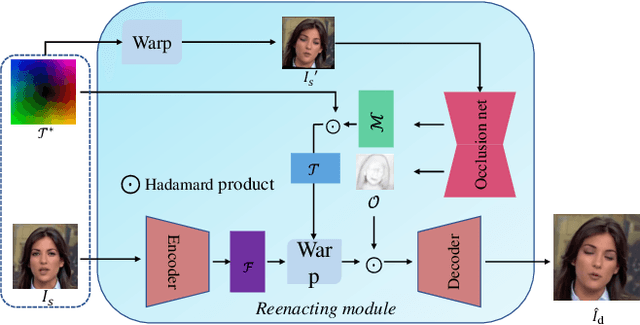
Face reenactment aims to animate a source face image to a different pose and expression provided by a driving image. Existing approaches are either designed for a specific identity, or suffer from the identity preservation problem in the one-shot or few-shot scenarios. In this paper, we introduce a method for one-shot face reenactment, which uses the reconstructed 3D meshes (i.e., the source mesh and driving mesh) as guidance to learn the optical flow needed for the reenacted face synthesis. Technically, we explicitly exclude the driving face's identity information in the reconstructed driving mesh. In this way, our network can focus on the motion estimation for the source face without the interference of driving face shape. We propose a motion net to learn the face motion, which is an asymmetric autoencoder. The encoder is a graph convolutional network (GCN) that learns a latent motion vector from the meshes, and the decoder serves to produce an optical flow image from the latent vector with CNNs. Compared to previous methods using sparse keypoints to guide the optical flow learning, our motion net learns the optical flow directly from 3D dense meshes, which provide the detailed shape and pose information for the optical flow, so it can achieve more accurate expression and pose on the reenacted face. Extensive experiments show that our method can generate high-quality results and outperforms state-of-the-art methods in both qualitative and quantitative comparisons.