 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh Guided One-shot Face Reenactment using Graph Convolutional Networks
Paper and Code
Sep 18, 2020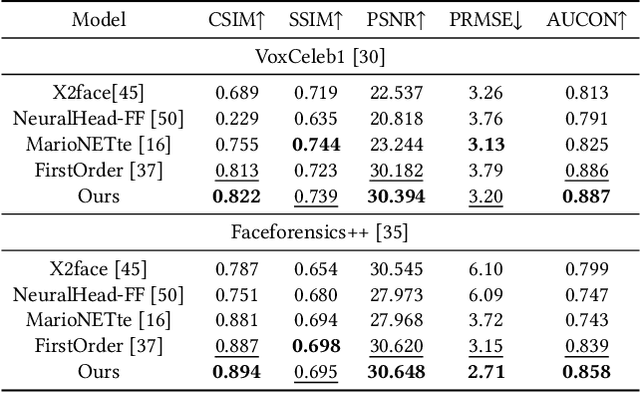
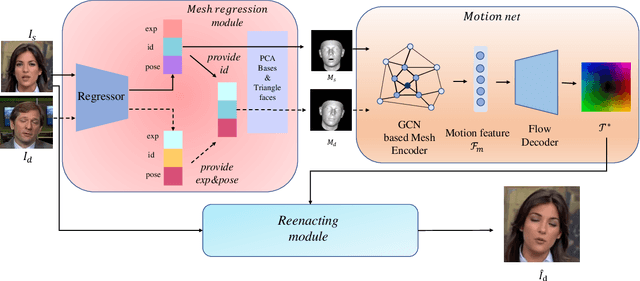
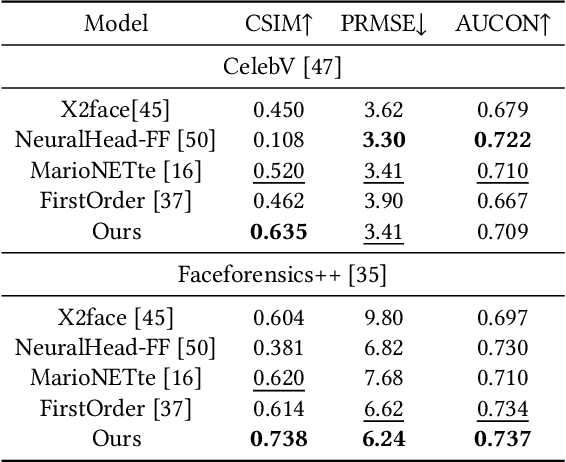
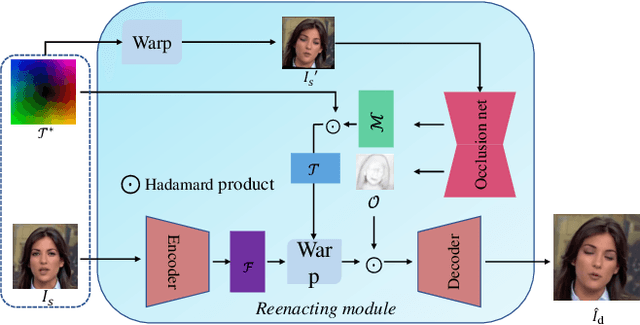
Face reenactment aims to animate a source face image to a different pose and expression provided by a driving image. Existing approaches are either designed for a specific identity, or suffer from the identity preservation problem in the one-shot or few-shot scenarios. In this paper, we introduce a method for one-shot face reenactment, which uses the reconstructed 3D meshes (i.e., the source mesh and driving mesh) as guidance to learn the optical flow needed for the reenacted face synthesis. Technically, we explicitly exclude the driving face's identity information in the reconstructed driving mesh. In this way, our network can focus on the motion estimation for the source face without the interference of driving face shape. We propose a motion net to learn the face motion, which is an asymmetric autoencoder. The encoder is a graph convolutional network (GCN) that learns a latent motion vector from the meshes, and the decoder serves to produce an optical flow image from the latent vector with CNNs. Compared to previous methods using sparse keypoints to guide the optical flow learning, our motion net learns the optical flow directly from 3D dense meshes, which provide the detailed shape and pose information for the optical flow, so it can achieve more accurate expression and pose on the reenacted face. Extensive experiments show that our method can generate high-quality results and outperforms state-of-the-art methods in both qualitative and quantitative comparisons.