 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTINA: Think, Interaction, and Action Framework for Zero-Shot Vision Language Navigation
Mar 13, 2024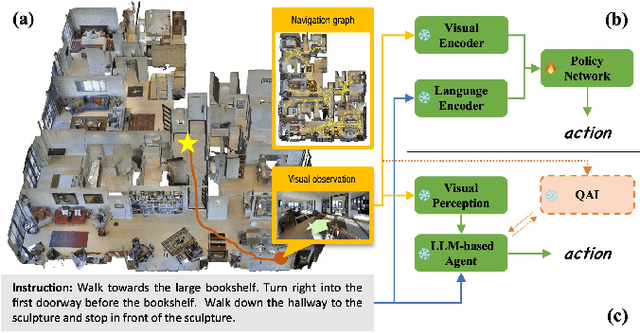
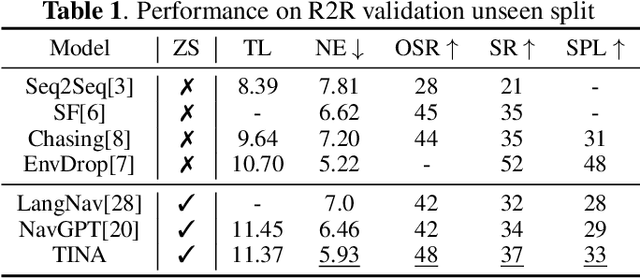
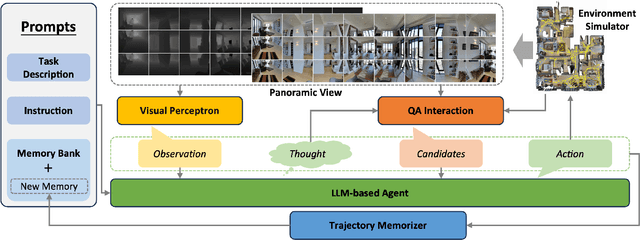
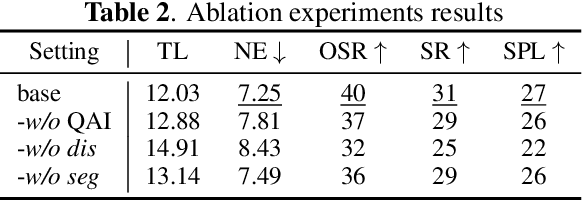
Zero-shot navigation is a critical challenge in Vision-Language Navigation (VLN) tasks, where the ability to adapt to unfamiliar instructions and to act in unknown environments is essential. Existing supervised learning-based models, trained using annotated data through reinforcement learning, exhibit limitations in generalization capabilities. Large Language Models (LLMs), with their extensive knowledge and emergent reasoning abilities, present a potential pathway for achieving zero-shot navigation. This paper presents a VLN agent based on LLMs, exploring approaches to the zero-shot navigation problem. To compensate for the shortcomings of LLMs in environmental perception, we propose the Thinking, Interacting, and Action (TINA) framework. TINA enables the agent to scrutinize perceptual information and autonomously query key clues within the environment through an introduced question-answering module, thereby aligning instructions with specific perceptual data. The navigation agent's perceptual abilities are enhanced through the TINA framework, while the explicit thought and query processes also improve the navigational procedure's explainability and transparency. We evaluate the performance of our method on the Room-to-Room dataset. The experiment results indicate that our approach improves the navigation performance of LLM-based agents. Our approach also outperformed some supervised learning-based methods, highlighting its efficacy in zero-shot navigation.
Thoughts on the Consistency between Ricci Flow and Neural Network Behavior
Nov 16, 2021
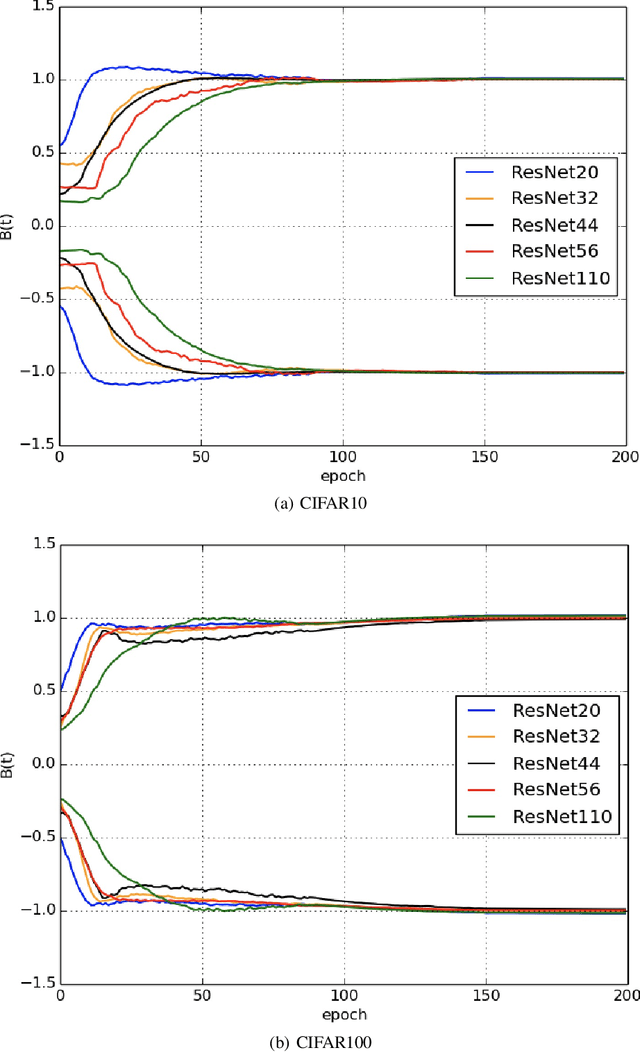
The Ricci flow is a partial differential equation for evolving the metric in a Riemannian manifold to make it more regular. However, in most cases, the Ricci flow tends to develop singularities and lead to divergence of the solution. In this paper, we propose the linearly nearly Euclidean metric to assist manifold micro-surgery, which means that we prove the dynamical stability and convergence of the metrics close to the linearly nearly Euclidean metric under the Ricci-DeTurck flow. In practice, from the information geometry and mirror descent points of view, we give the steepest descent gradient flow for neural networks on the linearly nearly Euclidean manifold. During the training process of the neural network, we observe that its metric will also regularly converge to the linearly nearly Euclidean metric, which is consistent with the convergent behavior of linearly nearly Euclidean manifolds under Ricci-DeTurck flow.
Analogous to Evolutionary Algorithm: Designing a Unified Sequence Model
May 31, 2021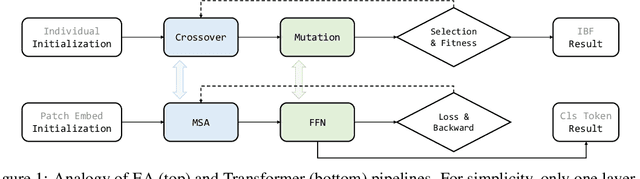
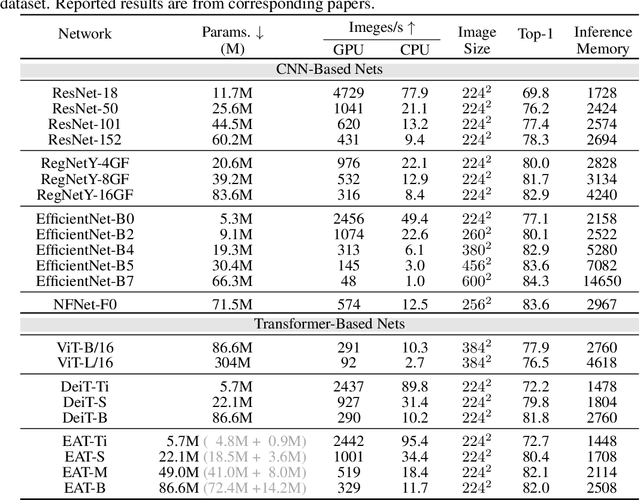

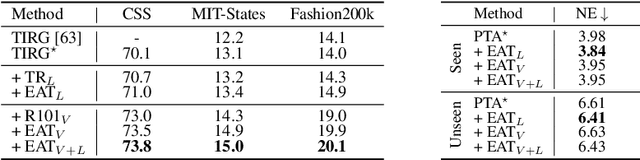
Inspired by biological evolution, we explain the rationality of Vision Transformer by analogy with the proven practical Evolutionary Algorithm (EA) and derive that both of them have consistent mathematical representation. Analogous to the dynamic local population in EA, we improve the existing transformer structure and propose a more efficient EAT model, and design task-related heads to deal with different tasks more flexibly. Moreover, we introduce the spatial-filling curve into the current vision transformer to sequence image data into a uniform sequential format. Thus we can design a unified EAT framework to address multi-modal tasks, separating the network architecture from the data format adaptation. Our approach achieves state-of-the-art results on the ImageNet classification task compared with recent vision transformer works while having smaller parameters and greater throughput. We further conduct multi-model tasks to demonstrate the superiority of the unified EAT, e.g., Text-Based Image Retrieval, and our approach improves the rank-1 by +3.7 points over the baseline on the CSS dataset.
HILONet: Hierarchical Imitation Learning from Non-Aligned Observations
Nov 05, 2020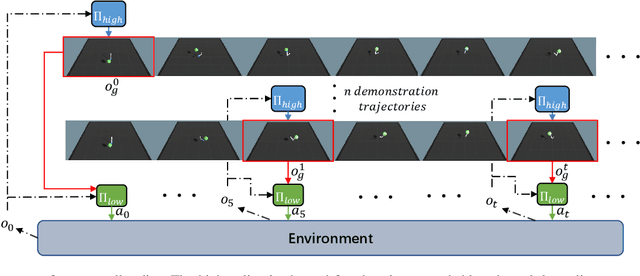

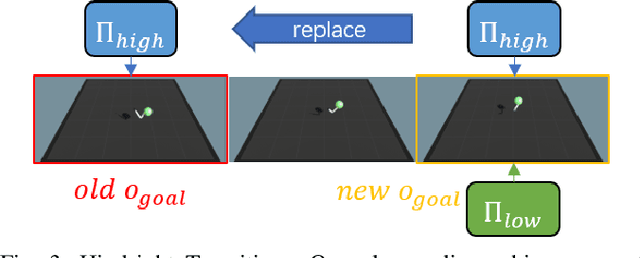
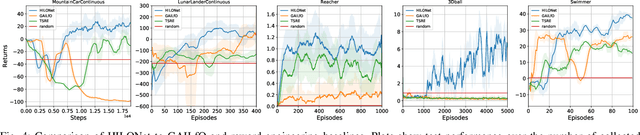
It is challenging learning from demonstrated observation-only trajectories in a non-time-aligned environment because most imitation learning methods aim to imitate experts by following the demonstration step-by-step. However, aligned demonstrations are seldom obtainable in real-world scenarios. In this work, we propose a new imitation learning approach called Hierarchical Imitation Learning from Observation(HILONet), which adopts a hierarchical structure to choose feasible sub-goals from demonstrated observations dynamically. Our method can solve all kinds of tasks by achieving these sub-goals, whether it has a single goal position or not. We also present three different ways to increase sample efficiency in the hierarchical structure. We conduct extensive experiments using several environments. The results show the improvement in both performance and learning efficiency.