 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault2Flow: An AlphaEvolve-Optimized Human-in-the-Loop Multi-Agent System for Fault-to-Workflow Automation
Nov 17, 2025Power grid fault diagnosis is a critical process hindered by its reliance on manual, error-prone methods. Technicians must manually extract reasoning logic from dense regulations and attempt to combine it with tacit expert knowledge, which is inefficient, error-prone, and lacks maintainability as ragulations are updated and experience evolves. While Large Language Models (LLMs) have shown promise in parsing unstructured text, no existing framework integrates these two disparate knowledge sources into a single, verified, and executable workflow. To bridge this gap, we propose Fault2Flow, an LLM-based multi-agent system. Fault2Flow systematically: (1) extracts and structures regulatory logic into PASTA-formatted fault trees; (2) integrates expert knowledge via a human-in-the-loop interface for verification; (3) optimizes the reasoning logic using a novel AlphaEvolve module; and (4) synthesizes the final, verified logic into an n8n-executable workflow. Experimental validation on transformer fault diagnosis datasets confirms 100\% topological consistency and high semantic fidelity. Fault2Flow establishes a reproducible path from fault analysis to operational automation, substantially reducing expert workload.
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
Feb 29, 2024



Financial trading is a crucial component of the markets, informed by a multimodal information landscape encompassing news, prices, and Kline charts, and encompasses diverse tasks such as quantitative trading and high-frequency trading with various assets. While advanced AI techniques like deep learning and reinforcement learning are extensively utilized in finance, their application in financial trading tasks often faces challenges due to inadequate handling of multimodal data and limited generalizability across various tasks. To address these challenges, we present FinAgent, a multimodal foundational agent with tool augmentation for financial trading. FinAgent's market intelligence module processes a diverse range of data-numerical, textual, and visual-to accurately analyze the financial market. Its unique dual-level reflection module not only enables rapid adaptation to market dynamics but also incorporates a diversified memory retrieval system, enhancing the agent's ability to learn from historical data and improve decision-making processes. The agent's emphasis on reasoning for actions fosters trust in its financial decisions. Moreover, FinAgent integrates established trading strategies and expert insights, ensuring that its trading approaches are both data-driven and rooted in sound financial principles. With comprehensive experiments on 6 financial datasets, including stocks and Crypto, FinAgent significantly outperforms 9 state-of-the-art baselines in terms of 6 financial metrics with over 36% average improvement on profit. Specifically, a 92.27% return (a 84.39% relative improvement) is achieved on one dataset. Notably, FinAgent is the first advanced multimodal foundation agent designed for financial trading tasks.
MAPConNet: Self-supervised 3D Pose Transfer with Mesh and Point Contrastive Learning
Apr 26, 20233D pose transfer is a challenging generation task that aims to transfer the pose of a source geometry onto a target geometry with the target identity preserved. Many prior methods require keypoint annotations to find correspondence between the source and target. Current pose transfer methods allow end-to-end correspondence learning but require the desired final output as ground truth for supervision. Unsupervised methods have been proposed for graph convolutional models but they require ground truth correspondence between the source and target inputs. We present a novel self-supervised framework for 3D pose transfer which can be trained in unsupervised, semi-supervised, or fully supervised settings without any correspondence labels. We introduce two contrastive learning constraints in the latent space: a mesh-level loss for disentangling global patterns including pose and identity, and a point-level loss for discriminating local semantics. We demonstrate quantitatively and qualitatively that our method achieves state-of-the-art results in supervised 3D pose transfer, with comparable results in unsupervised and semi-supervised settings. Our method is also generalisable to unseen human and animal data with complex topologies.
SeCGAN: Parallel Conditional Generative Adversarial Networks for Face Editing via Semantic Consistency
Nov 24, 2021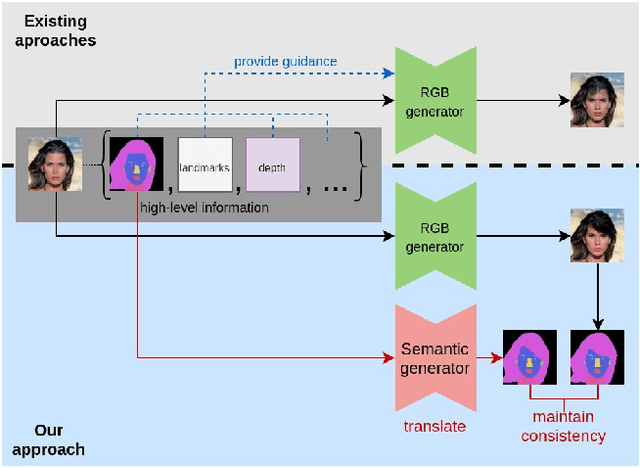
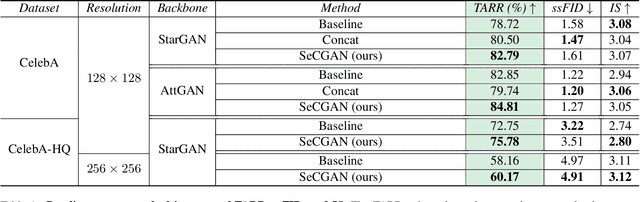
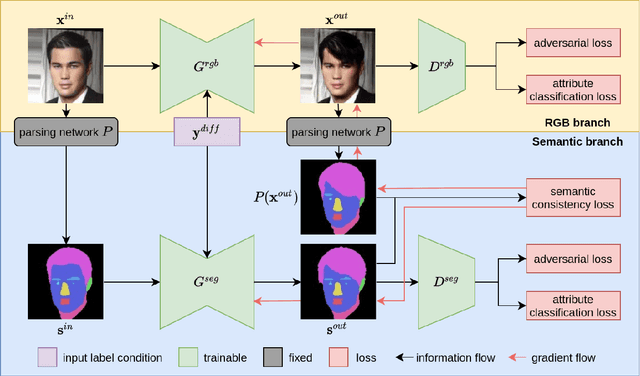
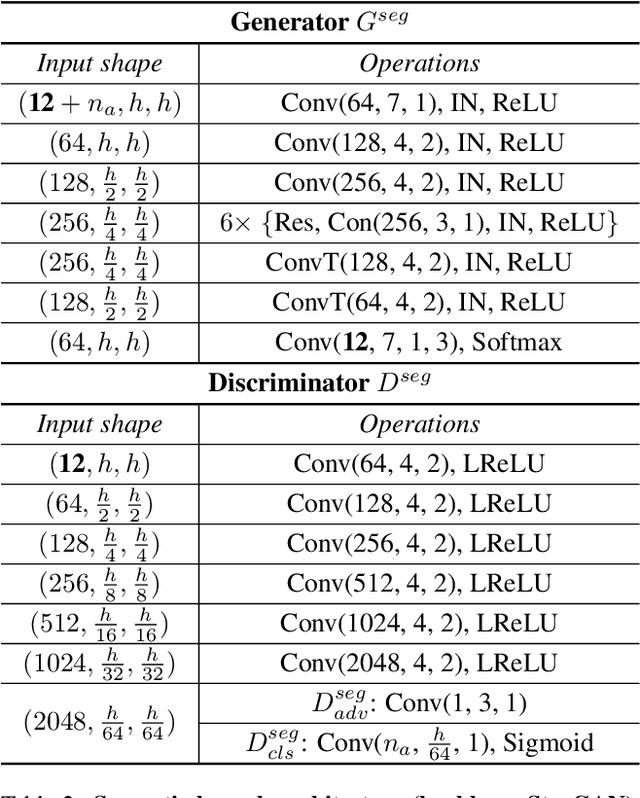
Semantically guided conditional Generative Adversarial Networks (cGANs) have become a popular approach for face editing in recent years. However, most existing methods introduce semantic masks as direct conditional inputs to the generator and often require the target masks to perform the corresponding translation in the RGB space. We propose SeCGAN, a novel label-guided cGAN for editing face images utilising semantic information without the need to specify target semantic masks. During training, SeCGAN has two branches of generators and discriminators operating in parallel, with one trained to translate RGB images and the other for semantic masks. To bridge the two branches in a mutually beneficial manner, we introduce a semantic consistency loss which constrains both branches to have consistent semantic outputs. Whilst both branches are required during training, the RGB branch is our primary network and the semantic branch is not needed for inference. Our results on CelebA and CelebA-HQ demonstrate that our approach is able to generate facial images with more accurate attributes, outperforming competitive baselines in terms of Target Attribute Recognition Rate whilst maintaining quality metrics such as self-supervised Fr\'{e}chet Inception Distance and Inception Score.
A BCS-GDE Algorithm for Multi-objective Optimization of Combined Cooling, Heating and Power Model
Aug 17, 2021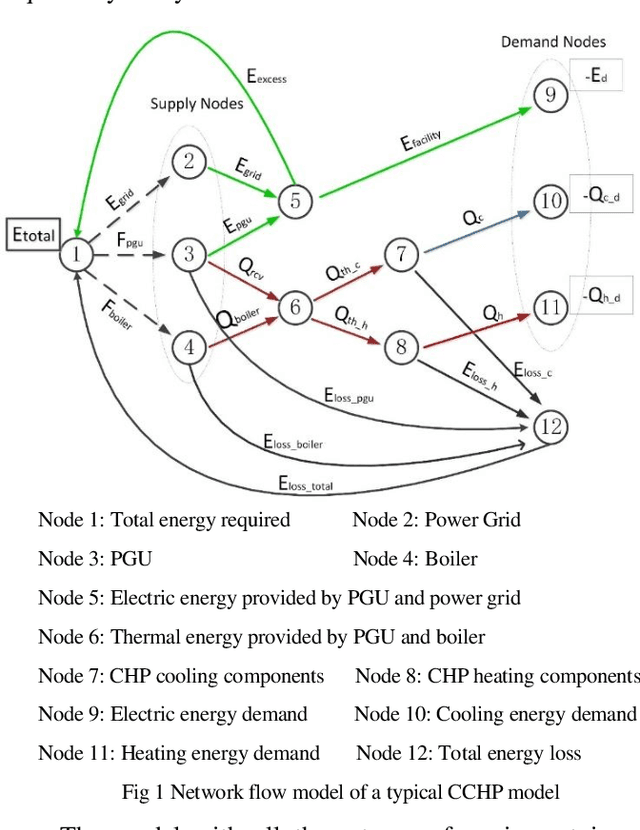
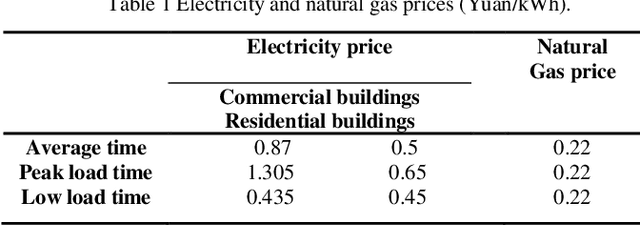
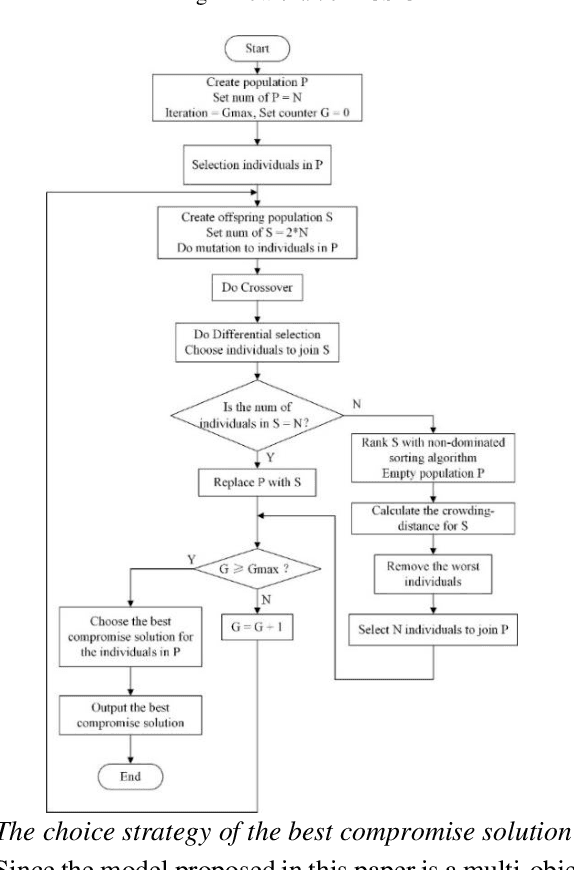
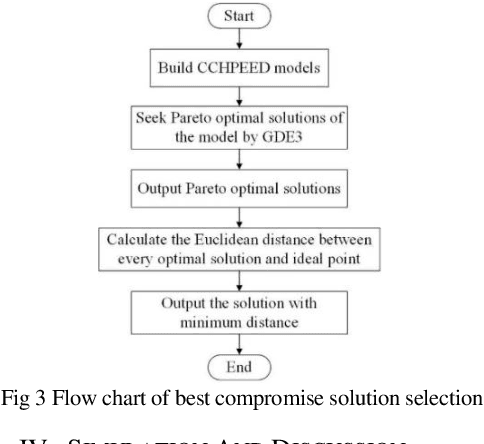
District energy systems can not only reduce energy consumption but also set energy supply dispatching schemes according to demand. In this paper, the combined cooling heating and power economic emission dispatch (CCHPEED) model is established with the objective of economic cost, primary energy consumption, and pollutant emissions, as well as three decision-making strategies, are proposed to meet the demand for energy supply. Besides, a generalized differential evolution with the best compromise solution processing mechanism (BCS-GDE) is proposed to solve the model, also, the best compromise solution processing mechanism is put forward in the algorithm. In the simulation, the resource dispatching is performed according to the different energy demands of hotels, offices, and residential buildings on the whole day. The simulation results show that the model established in this paper can reduce the economic cost, energy consumption, and pollutant emission, in which the maximum reduction rate of economic cost is 72%, the maximum reduction rate of primary energy consumption is 73%, and the maximum reduction rate of pollutant emission is 88%. Concurrently, BCS-GDE also has better convergence and diversity than the classic algorithms.
MatchGAN: A Self-Supervised Semi-Supervised Conditional Generative Adversarial Network
Jun 11, 2020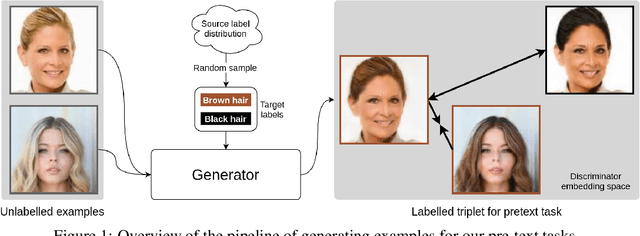
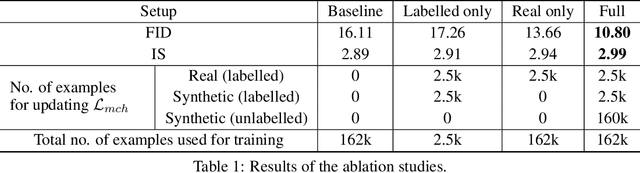
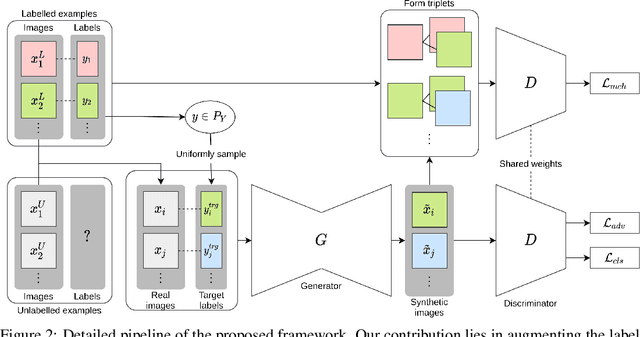
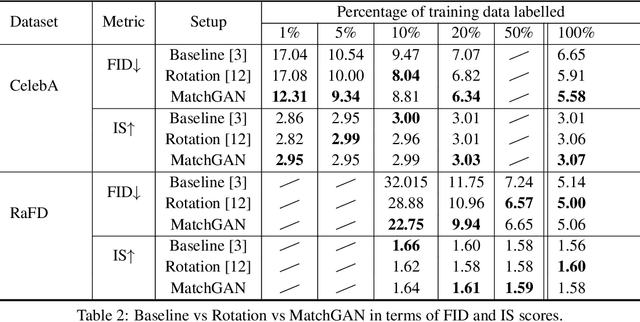
We propose a novel self-supervised semi-supervised learning approach for conditional Generative Adversarial Networks (GANs). Unlike previous self-supervised learning approaches which define pretext tasks by performing augmentations on the image space such as applying geometric transformations or predicting relationships between image patches, our approach leverages the label space. We train our network to learn the distribution of the source domain using the few labelled examples available by uniformly sampling source labels and assigning them as target labels for unlabelled examples from the same distribution. The translated images on the side of the generator are then grouped into positive and negative pairs by comparing their corresponding target labels, which are then used to optimise an auxiliary triplet objective on the discriminator's side. We tested our method on two challenging benchmarks, CelebA and RaFD, and evaluated the results using standard metrics including Frechet Inception Distance, Inception Score, and Attribute Classification Rate. Extensive empirical evaluation demonstrates the effectiveness of our proposed method over competitive baselines and existing arts. In particular, our method is able to surpass the baseline with only 20% of the labelled examples used to train the baseline.
Enhanced Expressive Power and Fast Training of Neural Networks by Random Projections
Nov 22, 2018

Random projections are able to perform dimension reduction efficiently for datasets with nonlinear low-dimensional structures. One well-known example is that random matrices embed sparse vectors into a low-dimensional subspace nearly isometrically, known as the restricted isometric property in compressed sensing. In this paper, we explore some applications of random projections in deep neural networks. We provide the expressive power of fully connected neural networks when the input data are sparse vectors or form a low-dimensional smooth manifold. We prove that the number of neurons required for approximating a Lipschitz function with a prescribed precision depends on the sparsity or the dimension of the manifold and weakly on the dimension of the input vector. The key in our proof is that random projections embed stably the set of sparse vectors or a low-dimensional smooth manifold into a low-dimensional subspace. Based on this fact, we also propose some new neural network models, where at each layer the input is first projected onto a low-dimensional subspace by a random projection and then the standard linear connection and non-linear activation are applied. In this way, the number of parameters in neural networks is significantly reduced, and therefore the training of neural networks can be accelerated without too much performance loss.