 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoCodeBench: A Human-Performance Benchmark for Self-Evolving LLM-Driven Coding Systems
Feb 10, 2026As large language models (LLMs) continue to advance in programming tasks, LLM-driven coding systems have evolved from one-shot code generation into complex systems capable of iterative improvement during inference. However, existing code benchmarks primarily emphasize static correctness and implicitly assume fixed model capability during inference. As a result, they do not capture inference-time self-evolution, such as whether accuracy and efficiency improve as an agent iteratively refines its solutions. They also provide limited accounting of resource costs and rarely calibrate model performance against that of human programmers. Moreover, many benchmarks are dominated by high-resource languages, leaving cross-language robustness and long-tail language stability underexplored. Therefore, we present EvoCodeBench, a benchmark for evaluating self-evolving LLM-driven coding systems across programming languages with direct comparison to human performance. EvoCodeBench tracks performance dynamics, measuring solution correctness alongside efficiency metrics such as solving time, memory consumption, and improvement algorithmic design over repeated problem-solving attempts. To ground evaluation in a human-centered reference frame, we directly compare model performance with that of human programmers on the same tasks, enabling relative performance assessment within the human ability distribution. Furthermore, EvoCodeBench supports multiple programming languages, enabling systematic cross-language and long-tail stability analyses under a unified protocol. Our results demonstrate that self-evolving systems exhibit measurable gains in efficiency over time, and that human-relative and multi-language analyses provide insights unavailable through accuracy alone. EvoCodeBench establishes a foundation for evaluating coding intelligence in evolving LLM-driven systems.
Advancing ESG Intelligence: An Expert-level Agent and Comprehensive Benchmark for Sustainable Finance
Jan 13, 2026Environmental, social, and governance (ESG) criteria are essential for evaluating corporate sustainability and ethical performance. However, professional ESG analysis is hindered by data fragmentation across unstructured sources, and existing large language models (LLMs) often struggle with the complex, multi-step workflows required for rigorous auditing. To address these limitations, we introduce ESGAgent, a hierarchical multi-agent system empowered by a specialized toolset, including retrieval augmentation, web search and domain-specific functions, to generate in-depth ESG analysis. Complementing this agentic system, we present a comprehensive three-level benchmark derived from 310 corporate sustainability reports, designed to evaluate capabilities ranging from atomic common-sense questions to the generation of integrated, in-depth analysis. Empirical evaluations demonstrate that ESGAgent outperforms state-of-the-art closed-source LLMs with an average accuracy of 84.15% on atomic question-answering tasks, and excels in professional report generation by integrating rich charts and verifiable references. These findings confirm the diagnostic value of our benchmark, establishing it as a vital testbed for assessing general and advanced agentic capabilities in high-stakes vertical domains.
AgentOrchestra: A Hierarchical Multi-Agent Framework for General-Purpose Task Solving
Jun 14, 2025



Recent advances in agent systems based on large language models (LLMs) have demonstrated strong capabilities in solving complex tasks. However, most current methods lack mechanisms for coordinating specialized agents and have limited ability to generalize to new or diverse domains. We introduce \projectname, a hierarchical multi-agent framework for general-purpose task solving that integrates high-level planning with modular agent collaboration. Inspired by the way a conductor orchestrates a symphony and guided by the principles of \textit{extensibility}, \textit{multimodality}, \textit{modularity}, and \textit{coordination}, \projectname features a central planning agent that decomposes complex objectives and delegates sub-tasks to a team of specialized agents. Each sub-agent is equipped with general programming and analytical tools, as well as abilities to tackle a wide range of real-world specific tasks, including data analysis, file operations, web navigation, and interactive reasoning in dynamic multimodal environments. \projectname supports flexible orchestration through explicit sub-goal formulation, inter-agent communication, and adaptive role allocation. We evaluate the framework on three widely used benchmark datasets covering various real-world tasks, searching web pages, reasoning over heterogeneous modalities, etc. Experimental results demonstrate that \projectname consistently outperforms flat-agent and monolithic baselines in task success rate and adaptability. These findings highlight the effectiveness of hierarchical organization and role specialization in building scalable and general-purpose LLM-based agent systems.
STORM: A Spatio-Temporal Factor Model Based on Dual Vector Quantized Variational Autoencoders for Financial Trading
Dec 12, 2024In financial trading, factor models are widely used to price assets and capture excess returns from mispricing. Recently, we have witnessed the rise of variational autoencoder-based latent factor models, which learn latent factors self-adaptively. While these models focus on modeling overall market conditions, they often fail to effectively capture the temporal patterns of individual stocks. Additionally, representing multiple factors as single values simplifies the model but limits its ability to capture complex relationships and dependencies. As a result, the learned factors are of low quality and lack diversity, reducing their effectiveness and robustness across different trading periods. To address these issues, we propose a Spatio-Temporal factOR Model based on dual vector quantized variational autoencoders, named STORM, which extracts features of stocks from temporal and spatial perspectives, then fuses and aligns these features at the fine-grained and semantic level, and represents the factors as multi-dimensional embeddings. The discrete codebooks cluster similar factor embeddings, ensuring orthogonality and diversity, which helps distinguish between different factors and enables factor selection in financial trading. To show the performance of the proposed factor model, we apply it to two downstream experiments: portfolio management on two stock datasets and individual trading tasks on six specific stocks. The extensive experiments demonstrate STORM's flexibility in adapting to downstream tasks and superior performance over baseline models.
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
Feb 29, 2024



Financial trading is a crucial component of the markets, informed by a multimodal information landscape encompassing news, prices, and Kline charts, and encompasses diverse tasks such as quantitative trading and high-frequency trading with various assets. While advanced AI techniques like deep learning and reinforcement learning are extensively utilized in finance, their application in financial trading tasks often faces challenges due to inadequate handling of multimodal data and limited generalizability across various tasks. To address these challenges, we present FinAgent, a multimodal foundational agent with tool augmentation for financial trading. FinAgent's market intelligence module processes a diverse range of data-numerical, textual, and visual-to accurately analyze the financial market. Its unique dual-level reflection module not only enables rapid adaptation to market dynamics but also incorporates a diversified memory retrieval system, enhancing the agent's ability to learn from historical data and improve decision-making processes. The agent's emphasis on reasoning for actions fosters trust in its financial decisions. Moreover, FinAgent integrates established trading strategies and expert insights, ensuring that its trading approaches are both data-driven and rooted in sound financial principles. With comprehensive experiments on 6 financial datasets, including stocks and Crypto, FinAgent significantly outperforms 9 state-of-the-art baselines in terms of 6 financial metrics with over 36% average improvement on profit. Specifically, a 92.27% return (a 84.39% relative improvement) is achieved on one dataset. Notably, FinAgent is the first advanced multimodal foundation agent designed for financial trading tasks.
Reinforcement Learning with Maskable Stock Representation for Portfolio Management in Customizable Stock Pools
Nov 21, 2023

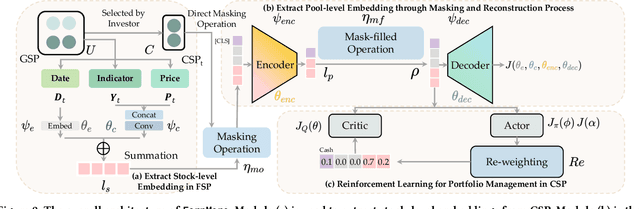
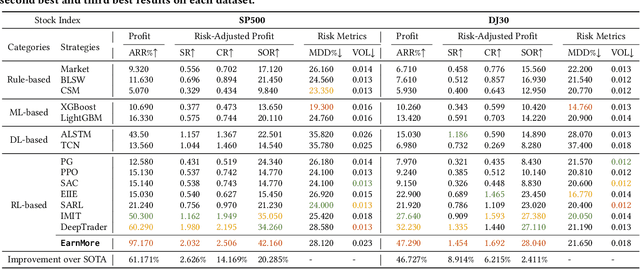
Portfolio management (PM) is a fundamental financial trading task, which explores the optimal periodical reallocation of capitals into different stocks to pursue long-term profits. Reinforcement learning (RL) has recently shown its potential to train profitable agents for PM through interacting with financial markets. However, existing work mostly focuses on fixed stock pools, which is inconsistent with investors' practical demand. Specifically, the target stock pool of different investors varies dramatically due to their discrepancy on market states and individual investors may temporally adjust stocks they desire to trade (e.g., adding one popular stocks), which lead to customizable stock pools (CSPs). Existing RL methods require to retrain RL agents even with a tiny change of the stock pool, which leads to high computational cost and unstable performance. To tackle this challenge, we propose EarnMore, a rEinforcement leARNing framework with Maskable stOck REpresentation to handle PM with CSPs through one-shot training in a global stock pool (GSP). Specifically, we first introduce a mechanism to mask out the representation of the stocks outside the target pool. Second, we learn meaningful stock representations through a self-supervised masking and reconstruction process. Third, a re-weighting mechanism is designed to make the portfolio concentrate on favorable stocks and neglect the stocks outside the target pool. Through extensive experiments on 8 subset stock pools of the US stock market, we demonstrate that EarnMore significantly outperforms 14 state-of-the-art baselines in terms of 6 popular financial metrics with over 40% improvement on profit.