 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Variance and Scale-Invariant Updates in Adaptive Gradient Descent for Unified Vector and Matrix Optimization
Feb 06, 2026Adaptive methods like Adam have become the $\textit{de facto}$ standard for large-scale vector and Euclidean optimization due to their coordinate-wise adaptation with a second-order nature. More recently, matrix-based spectral optimizers like Muon (Jordan et al., 2024b) show the power of treating weight matrices as matrices rather than long vectors. Linking these is hard because many natural generalizations are not feasible to implement, and we also cannot simply move the Adam adaptation to the matrix spectrum. To address this, we reformulate the AdaGrad update and decompose it into a variance adaptation term and a scale-invariant term. This decoupling produces $\textbf{DeVA}$ ($\textbf{De}$coupled $\textbf{V}$ariance $\textbf{A}$daptation), a framework that bridges between vector-based variance adaptation and matrix spectral optimization, enabling a seamless transition from Adam to adaptive spectral descent. Extensive experiments across language modeling and image classification demonstrate that DeVA consistently outperforms state-of-the-art methods such as Muon and SOAP (Vyas et al., 2024), reducing token usage by around 6.6\%. Theoretically, we show that the variance adaptation term effectively improves the blockwise smoothness, facilitating faster convergence. Our implementation is available at https://github.com/Tsedao/Decoupled-Variance-Adaptation
Latent Logic Tree Extraction for Event Sequence Explanation from LLMs
Jun 04, 2024



Modern high-stakes systems, such as healthcare or robotics, often generate vast streaming event sequences. Our goal is to design an efficient, plug-and-play tool to elicit logic tree-based explanations from Large Language Models (LLMs) to provide customized insights into each observed event sequence. Built on the temporal point process model for events, our method employs the likelihood function as a score to evaluate generated logic trees. We propose an amortized Expectation-Maximization (EM) learning framework and treat the logic tree as latent variables. In the E-step, we evaluate the posterior distribution over the latent logic trees using an LLM prior and the likelihood of the observed event sequences. LLM provides a high-quality prior for the latent logic trees, however, since the posterior is built over a discrete combinatorial space, we cannot get the closed-form solution. We propose to generate logic tree samples from the posterior using a learnable GFlowNet, which is a diversity-seeking generator for structured discrete variables. The M-step employs the generated logic rules to approximate marginalization over the posterior, facilitating the learning of model parameters and refining the tunable LLM prior parameters. In the online setting, our locally built, lightweight model will iteratively extract the most relevant rules from LLMs for each sequence using only a few iterations. Empirical demonstrations showcase the promising performance and adaptability of our framework.
Reinforcement Learning with Maskable Stock Representation for Portfolio Management in Customizable Stock Pools
Nov 21, 2023

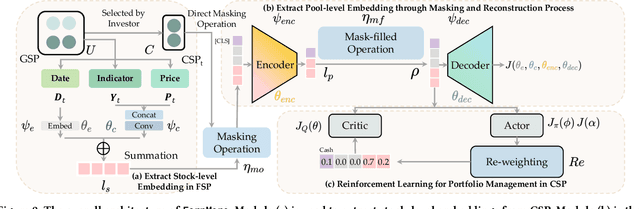
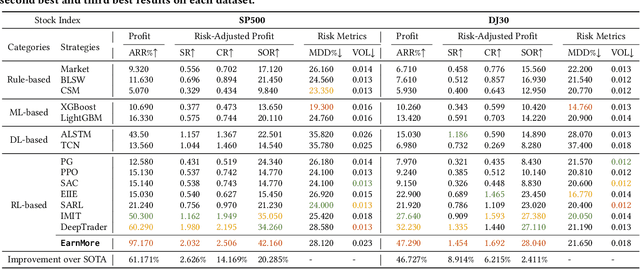
Portfolio management (PM) is a fundamental financial trading task, which explores the optimal periodical reallocation of capitals into different stocks to pursue long-term profits. Reinforcement learning (RL) has recently shown its potential to train profitable agents for PM through interacting with financial markets. However, existing work mostly focuses on fixed stock pools, which is inconsistent with investors' practical demand. Specifically, the target stock pool of different investors varies dramatically due to their discrepancy on market states and individual investors may temporally adjust stocks they desire to trade (e.g., adding one popular stocks), which lead to customizable stock pools (CSPs). Existing RL methods require to retrain RL agents even with a tiny change of the stock pool, which leads to high computational cost and unstable performance. To tackle this challenge, we propose EarnMore, a rEinforcement leARNing framework with Maskable stOck REpresentation to handle PM with CSPs through one-shot training in a global stock pool (GSP). Specifically, we first introduce a mechanism to mask out the representation of the stocks outside the target pool. Second, we learn meaningful stock representations through a self-supervised masking and reconstruction process. Third, a re-weighting mechanism is designed to make the portfolio concentrate on favorable stocks and neglect the stocks outside the target pool. Through extensive experiments on 8 subset stock pools of the US stock market, we demonstrate that EarnMore significantly outperforms 14 state-of-the-art baselines in terms of 6 popular financial metrics with over 40% improvement on profit.
Amortized Network Intervention to Steer the Excitatory Point Processes
Oct 06, 2023
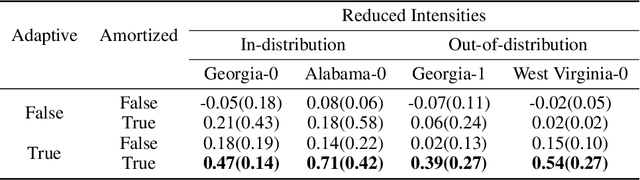

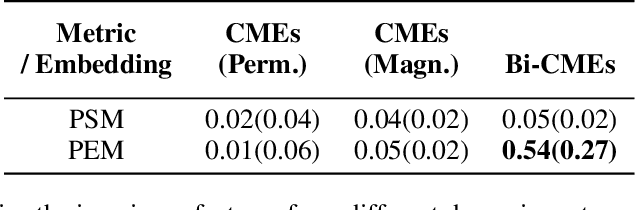
We tackle the challenge of large-scale network intervention for guiding excitatory point processes, such as infectious disease spread or traffic congestion control. Our model-based reinforcement learning utilizes neural ODEs to capture how the networked excitatory point processes will evolve subject to the time-varying changes in network topology. Our approach incorporates Gradient-Descent based Model Predictive Control (GD-MPC), offering policy flexibility to accommodate prior knowledge and constraints. To address the intricacies of planning and overcome the high dimensionality inherent to such decision-making problems, we design an Amortize Network Interventions (ANI) framework, allowing for the pooling of optimal policies from history and other contexts, while ensuring a permutation equivalent property. This property enables efficient knowledge transfer and sharing across diverse contexts. Our approach has broad applications, from curbing infectious disease spread to reducing carbon emissions through traffic light optimization, and thus has the potential to address critical societal and environmental challenges.
Safe-FinRL: A Low Bias and Variance Deep Reinforcement Learning Implementation for High-Freq Stock Trading
Jun 13, 2022

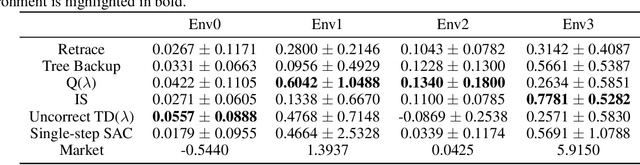
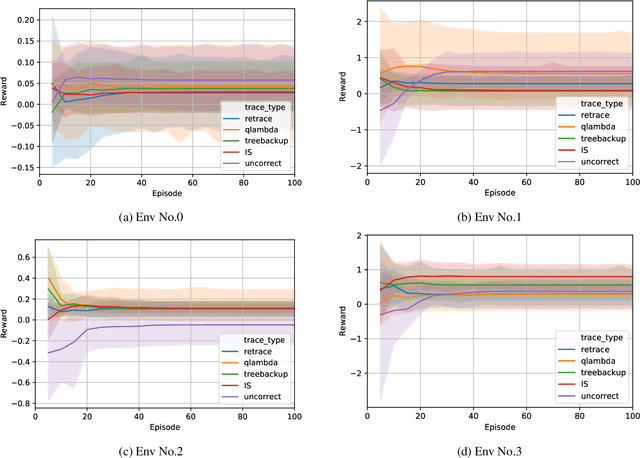
In recent years, many practitioners in quantitative finance have attempted to use Deep Reinforcement Learning (DRL) to build better quantitative trading (QT) strategies. Nevertheless, many existing studies fail to address several serious challenges, such as the non-stationary financial environment and the bias and variance trade-off when applying DRL in the real financial market. In this work, we proposed Safe-FinRL, a novel DRL-based high-freq stock trading strategy enhanced by the near-stationary financial environment and low bias and variance estimation. Our main contributions are twofold: firstly, we separate the long financial time series into the near-stationary short environment; secondly, we implement Trace-SAC in the near-stationary financial environment by incorporating the general retrace operator into the Soft Actor-Critic. Extensive experiments on the cryptocurrency market have demonstrated that Safe-FinRL has provided a stable value estimation and a steady policy improvement and reduced bias and variance significantly in the near-stationary financial environment.