 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Network Intervention to Steer the Excitatory Point Processes
Oct 06, 2023
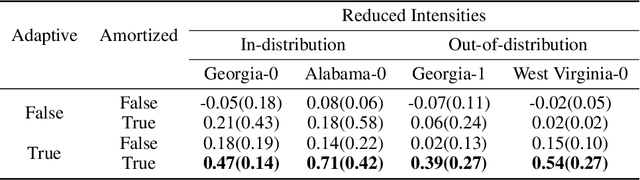

We tackle the challenge of large-scale network intervention for guiding excitatory point processes, such as infectious disease spread or traffic congestion control. Our model-based reinforcement learning utilizes neural ODEs to capture how the networked excitatory point processes will evolve subject to the time-varying changes in network topology. Our approach incorporates Gradient-Descent based Model Predictive Control (GD-MPC), offering policy flexibility to accommodate prior knowledge and constraints. To address the intricacies of planning and overcome the high dimensionality inherent to such decision-making problems, we design an Amortize Network Interventions (ANI) framework, allowing for the pooling of optimal policies from history and other contexts, while ensuring a permutation equivalent property. This property enables efficient knowledge transfer and sharing across diverse contexts. Our approach has broad applications, from curbing infectious disease spread to reducing carbon emissions through traffic light optimization, and thus has the potential to address critical societal and environmental challenges.
Fine-Tuning Pre-trained Language Model with Weak Supervision: A Contrastive-Regularized Self-Training Approach
Oct 20, 2020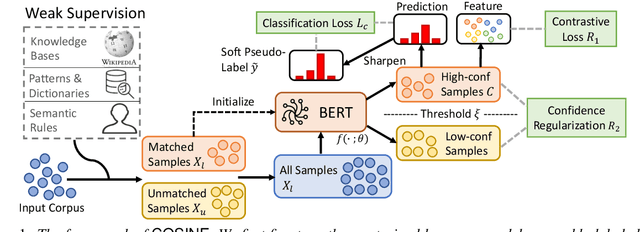
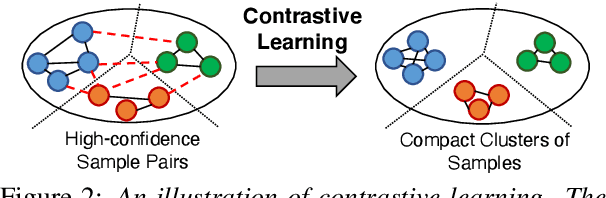
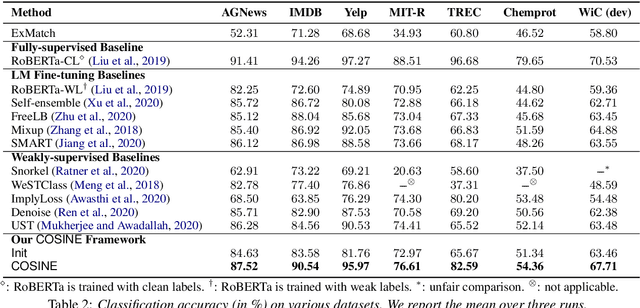
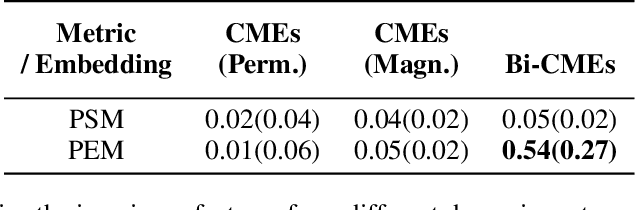
Fine-tuned pre-trained language models (LMs) achieve enormous success in many natural language processing (NLP) tasks, but they still require excessive labeled data in the fine-tuning stage. We study the problem of fine-tuning pre-trained LMs using only weak supervision, without any labeled data. This problem is challenging because the high capacity of LMs makes them prone to overfitting the noisy labels generated by weak supervision. To address this problem, we develop a contrastive self-training framework, COSINE, to enable fine-tuning LMs with weak supervision. Underpinned by contrastive regularization and confidence-based reweighting, this contrastive self-training framework can gradually improve model fitting while effectively suppressing error propagation. Experiments on sequence, token, and sentence pair classification tasks show that our model outperforms the strongest baseline by large margins on 7 benchmarks in 6 tasks, and achieves competitive performance with fully-supervised fine-tuning methods.
Denoising Multi-Source Weak Supervision for Neural Text Classification
Oct 09, 2020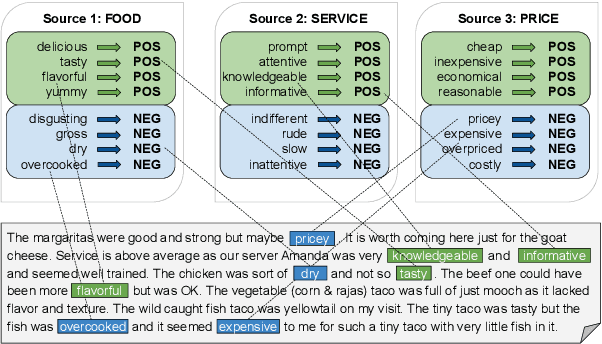

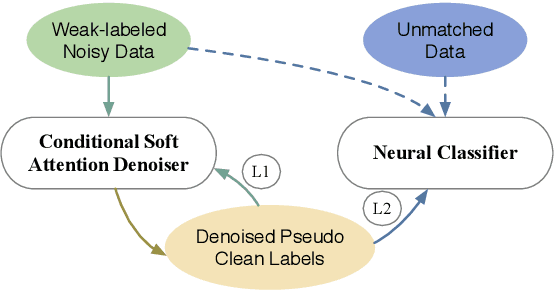

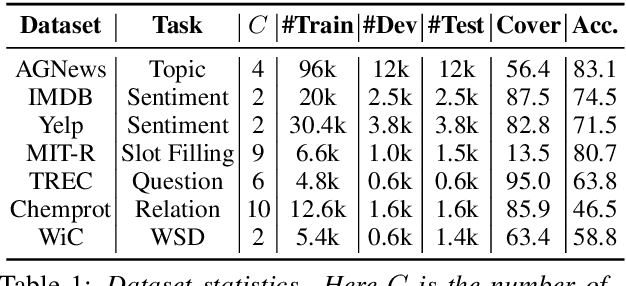
We study the problem of learning neural text classifiers without using any labeled data, but only easy-to-provide rules as multiple weak supervision sources. This problem is challenging because rule-induced weak labels are often noisy and incomplete. To address these two challenges, we design a label denoiser, which estimates the source reliability using a conditional soft attention mechanism and then reduces label noise by aggregating rule-annotated weak labels. The denoised pseudo labels then supervise a neural classifier to predicts soft labels for unmatched samples, which address the rule coverage issue. We evaluate our model on five benchmarks for sentiment, topic, and relation classifications. The results show that our model outperforms state-of-the-art weakly-supervised and semi-supervised methods consistently, and achieves comparable performance with fully-supervised methods even without any labeled data. Our code can be found at https://github.com/weakrules/Denoise-multi-weak-sources.