 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatchGAN: A Self-Supervised Semi-Supervised Conditional Generative Adversarial Network
Paper and Code
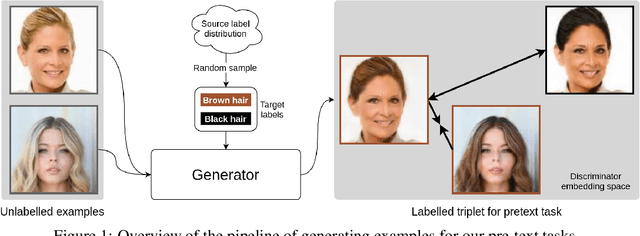
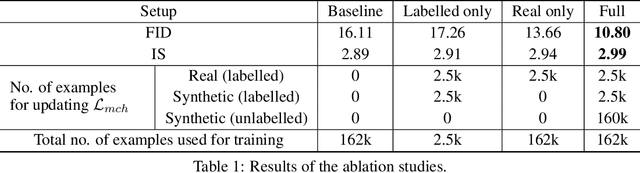
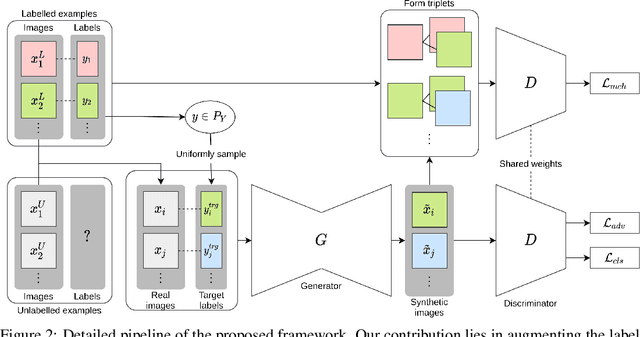
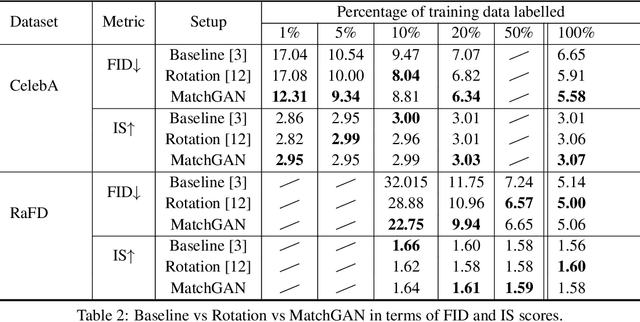
We propose a novel self-supervised semi-supervised learning approach for conditional Generative Adversarial Networks (GANs). Unlike previous self-supervised learning approaches which define pretext tasks by performing augmentations on the image space such as applying geometric transformations or predicting relationships between image patches, our approach leverages the label space. We train our network to learn the distribution of the source domain using the few labelled examples available by uniformly sampling source labels and assigning them as target labels for unlabelled examples from the same distribution. The translated images on the side of the generator are then grouped into positive and negative pairs by comparing their corresponding target labels, which are then used to optimise an auxiliary triplet objective on the discriminator's side. We tested our method on two challenging benchmarks, CelebA and RaFD, and evaluated the results using standard metrics including Frechet Inception Distance, Inception Score, and Attribute Classification Rate. Extensive empirical evaluation demonstrates the effectiveness of our proposed method over competitive baselines and existing arts. In particular, our method is able to surpass the baseline with only 20% of the labelled examples used to train the baseline.