 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Enhanced Cross-modal Localization Between 360 Images and Point Clouds
Paper and Code
Dec 06, 2022
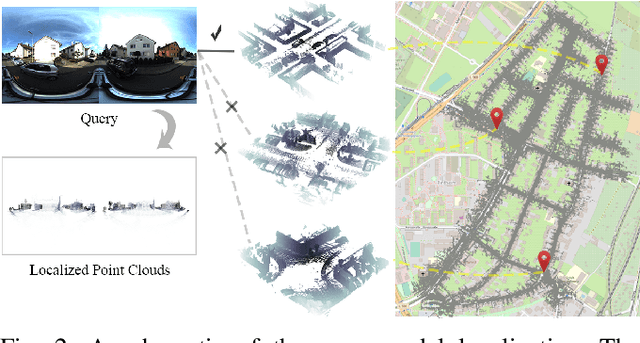


Visual localization plays an important role for intelligent robots and autonomous driving, especially when the accuracy of GNSS is unreliable. Recently, camera localization in LiDAR maps has attracted more and more attention for its low cost and potential robustness to illumination and weather changes. However, the commonly used pinhole camera has a narrow Field-of-View, thus leading to limited information compared with the omni-directional LiDAR data. To overcome this limitation, we focus on correlating the information of 360 equirectangular images to point clouds, proposing an end-to-end learnable network to conduct cross-modal visual localization by establishing similarity in high-dimensional feature space. Inspired by the attention mechanism, we optimize the network to capture the salient feature for comparing images and point clouds. We construct several sequences containing 360 equirectangular images and corresponding point clouds based on the KITTI-360 dataset and conduct extensive experiments. The results demonstrate the effectiveness of our approach.