 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstract Demonstrations and Adaptive Exploration for Efficient and Stable Multi-step Sparse Reward Reinforcement Learning
Paper and Code
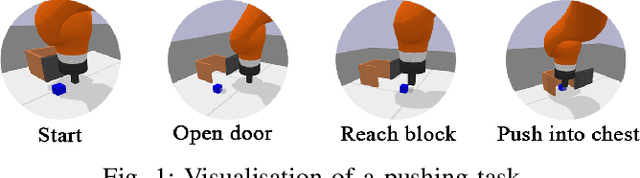
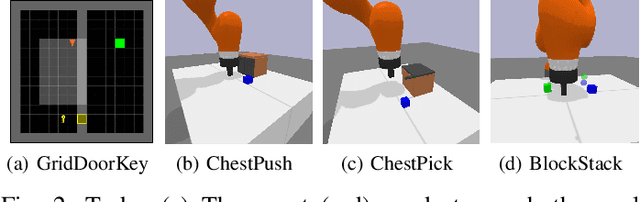
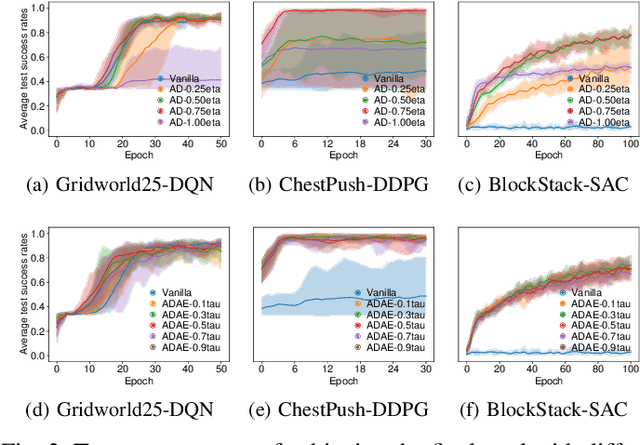
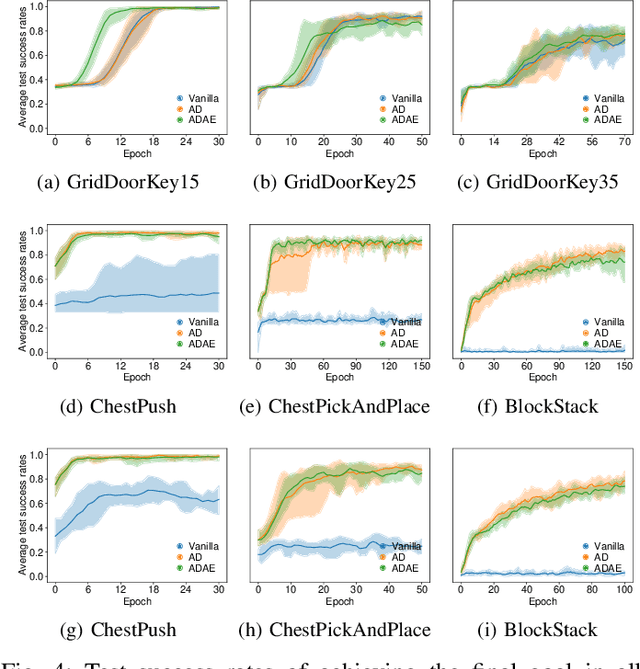
Although Deep Reinforcement Learning (DRL) has been popular in many disciplines including robotics, state-of-the-art DRL algorithms still struggle to learn long-horizon, multi-step and sparse reward tasks, such as stacking several blocks given only a task-completion reward signal. To improve learning efficiency for such tasks, this paper proposes a DRL exploration technique, termed A^2, which integrates two components inspired by human experiences: Abstract demonstrations and Adaptive exploration. A^2 starts by decomposing a complex task into subtasks, and then provides the correct orders of subtasks to learn. During training, the agent explores the environment adaptively, acting more deterministically for well-mastered subtasks and more stochastically for ill-learnt subtasks. Ablation and comparative experiments are conducted on several grid-world tasks and three robotic manipulation tasks. We demonstrate that A^2 can aid popular DRL algorithms (DQN, DDPG, and SAC) to learn more efficiently and stably in these environments.