 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBailicai: A Domain-Optimized Retrieval-Augmented Generation Framework for Medical Applications
Jul 24, 2024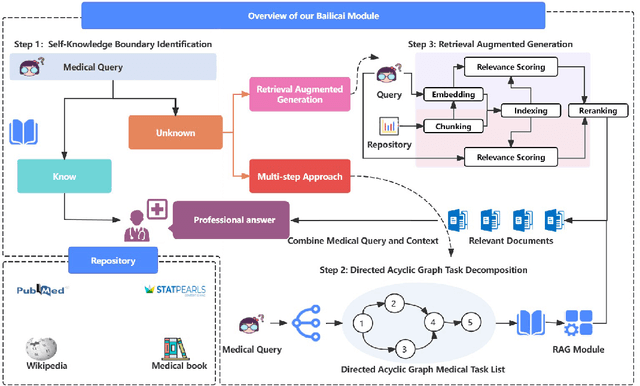
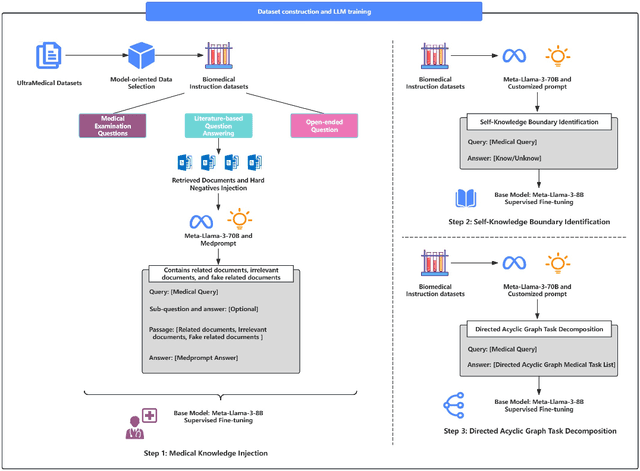
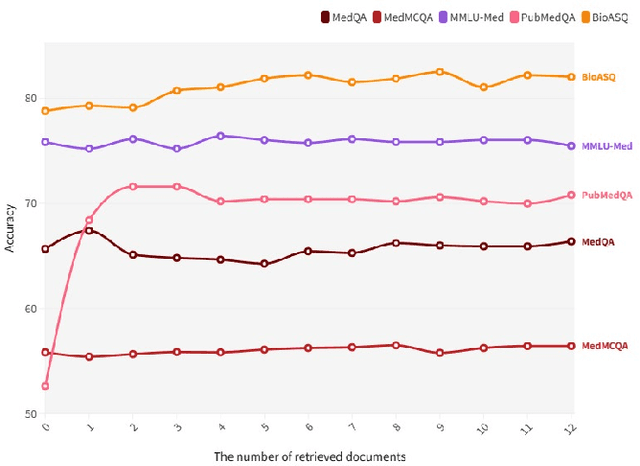

Large Language Models (LLMs) have exhibited remarkable proficiency in natural language understanding, prompting extensive exploration of their potential applications across diverse domains. In the medical domain, open-source LLMs have demonstrated moderate efficacy following domain-specific fine-tuning; however, they remain substantially inferior to proprietary models such as GPT-4 and GPT-3.5. These open-source models encounter limitations in the comprehensiveness of domain-specific knowledge and exhibit a propensity for 'hallucinations' during text generation. To mitigate these issues, researchers have implemented the Retrieval-Augmented Generation (RAG) approach, which augments LLMs with background information from external knowledge bases while preserving the model's internal parameters. However, document noise can adversely affect performance, and the application of RAG in the medical field remains in its nascent stages. This study presents the Bailicai framework: a novel integration of retrieval-augmented generation with large language models optimized for the medical domain. The Bailicai framework augments the performance of LLMs in medicine through the implementation of four sub-modules. Experimental results demonstrate that the Bailicai approach surpasses existing medical domain LLMs across multiple medical benchmarks and exceeds the performance of GPT-3.5. Furthermore, the Bailicai method effectively attenuates the prevalent issue of hallucinations in medical applications of LLMs and ameliorates the noise-related challenges associated with traditional RAG techniques when processing irrelevant or pseudo-relevant documents.
Intuitive or Dependent? Investigating LLMs' Robustness to Conflicting Prompts
Oct 03, 2023



This paper explores the robustness of LLMs' preference to their internal memory or the given prompt, which may contain contrasting information in real-world applications due to noise or task settings. To this end, we establish a quantitative benchmarking framework and conduct the role playing intervention to control LLMs' preference. In specific, we define two types of robustness, factual robustness targeting the ability to identify the correct fact from prompts or memory, and decision style to categorize LLMs' behavior in making consistent choices -- assuming there is no definitive "right" answer -- intuitive, dependent, or rational based on cognitive theory. Our findings, derived from extensive experiments on seven open-source and closed-source LLMs, reveal that these models are highly susceptible to misleading prompts, especially for instructing commonsense knowledge. While detailed instructions can mitigate the selection of misleading answers, they also increase the incidence of invalid responses. After Unraveling the preference, we intervene different sized LLMs through specific style of role instruction, showing their varying upper bound of robustness and adaptivity.
Causal Interventions-based Few-Shot Named Entity Recognition
May 03, 2023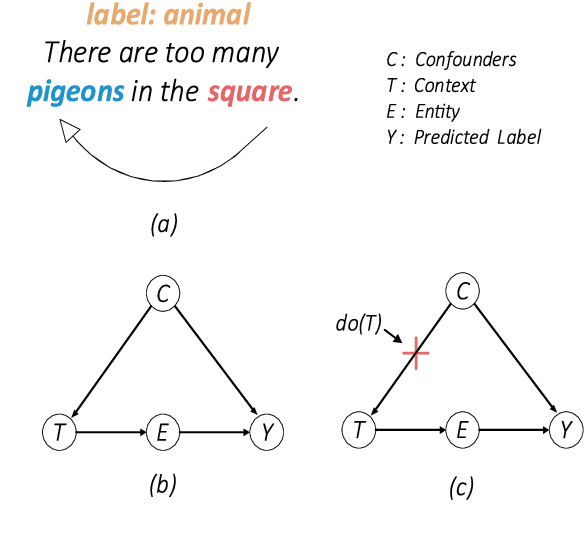
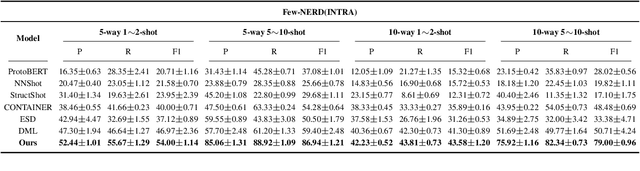
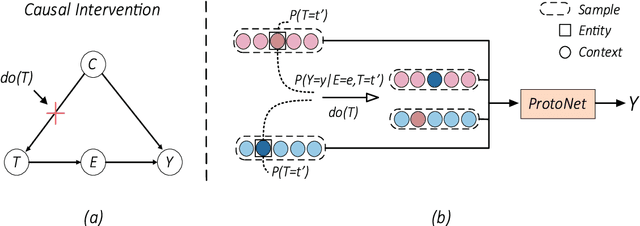
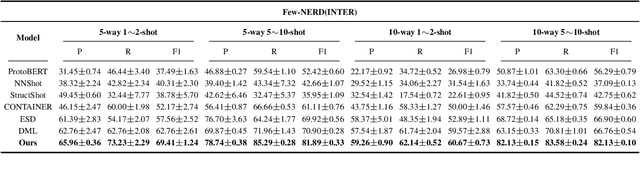
Few-shot named entity recognition (NER) systems aims at recognizing new classes of entities based on a few labeled samples. A significant challenge in the few-shot regime is prone to overfitting than the tasks with abundant samples. The heavy overfitting in few-shot learning is mainly led by spurious correlation caused by the few samples selection bias. To alleviate the problem of the spurious correlation in the few-shot NER, in this paper, we propose a causal intervention-based few-shot NER method. Based on the prototypical network, the method intervenes in the context and prototype via backdoor adjustment during training. In particular, intervening in the context of the one-shot scenario is very difficult, so we intervene in the prototype via incremental learning, which can also avoid catastrophic forgetting. Our experiments on different benchmarks show that our approach achieves new state-of-the-art results (achieving up to 29% absolute improvement and 12% on average for all tasks).
Ensemble Making Few-Shot Learning Stronger
May 12, 2021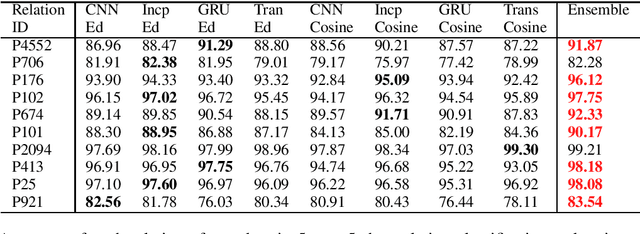
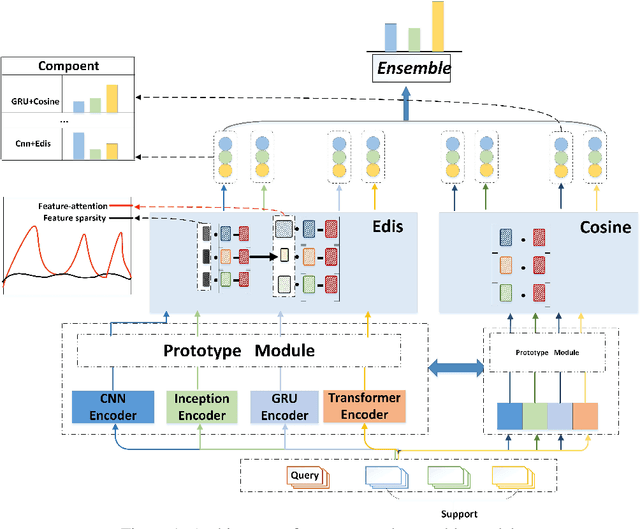
Few-shot learning has been proposed and rapidly emerging as a viable means for completing various tasks. Many few-shot models have been widely used for relation learning tasks. However, each of these models has a shortage of capturing a certain aspect of semantic features, for example, CNN on long-range dependencies part, Transformer on local features. It is difficult for a single model to adapt to various relation learning, which results in the high variance problem. Ensemble strategy could be competitive on improving the accuracy of few-shot relation extraction and mitigating high variance risks. This paper explores an ensemble approach to reduce the variance and introduces fine-tuning and feature attention strategies to calibrate relation-level features. Results on several few-shot relation learning tasks show that our model significantly outperforms the previous state-of-the-art models.
Student's t-Generative Adversarial Networks
Nov 06, 2018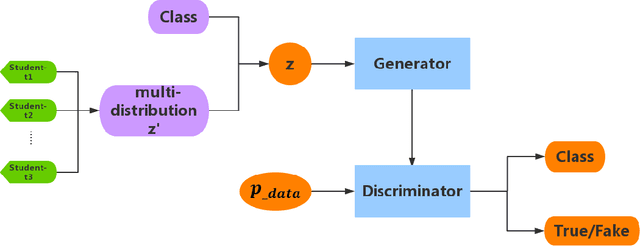
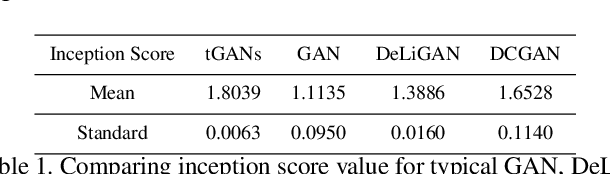

Generative Adversarial Networks (GANs) have a great performance in image generation, but they need a large scale of data to train the entire framework, and often result in nonsensical results. We propose a new method referring to conditional GAN, which equipments the latent noise with mixture of Student's t-distribution with attention mechanism in addition to class information. Student's t-distribution has long tails that can provide more diversity to the latent noise. Meanwhile, the discriminator in our model implements two tasks simultaneously, judging whether the images come from the true data distribution, and identifying the class of each generated images. The parameters of the mixture model can be learned along with those of GANs. Moreover, we mathematically prove that any multivariate Student's t-distribution can be obtained by a linear transformation of a normal multivariate Student's t-distribution. Experiments comparing the proposed method with typical GAN, DeliGAN and DCGAN indicate that, our method has a great performance on generating diverse and legible objects with limited data.
Generative Adversarial Networks with Decoder-Encoder Output Noise
Jul 11, 2018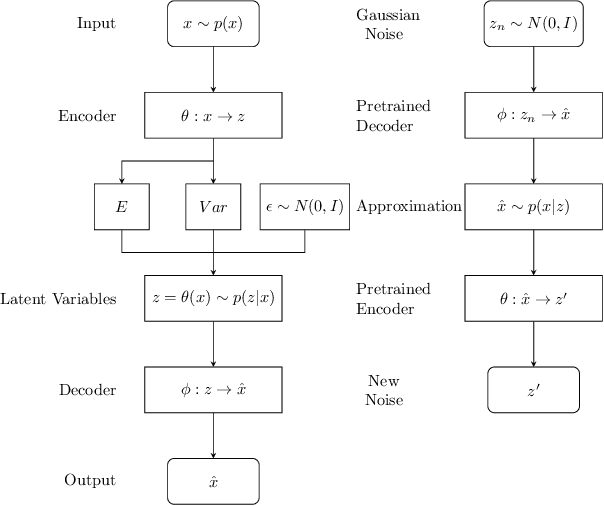
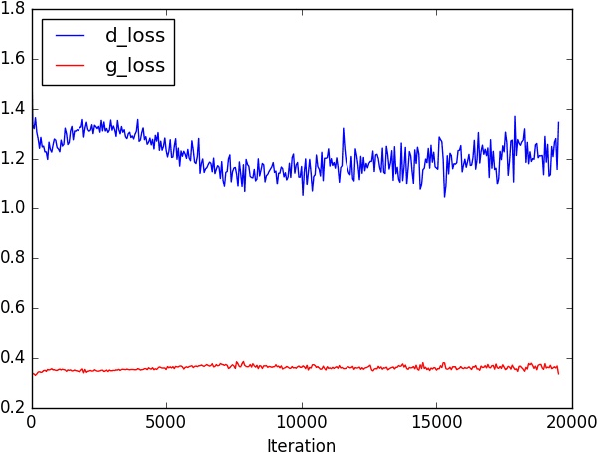
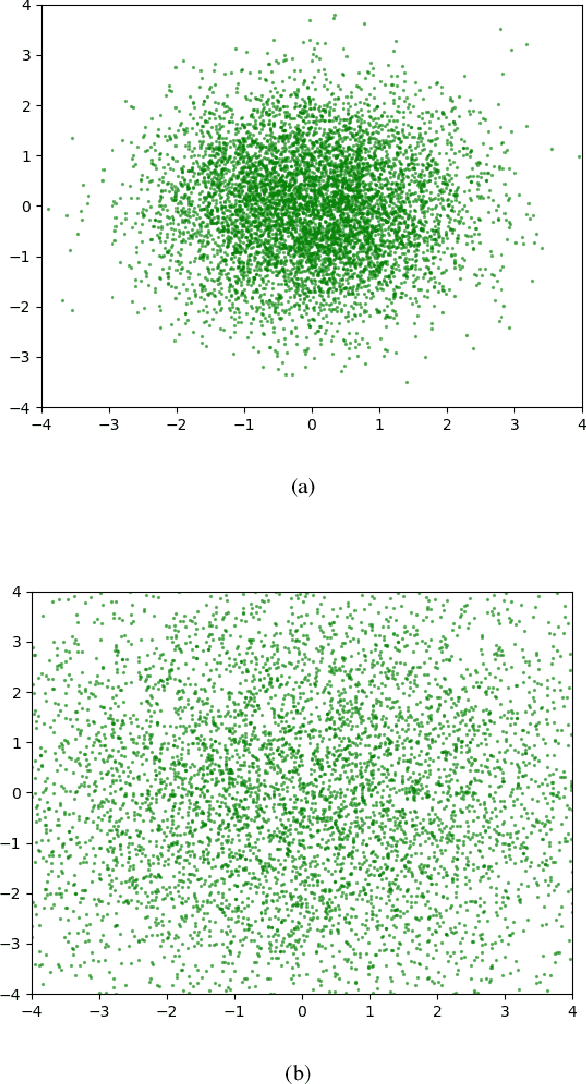
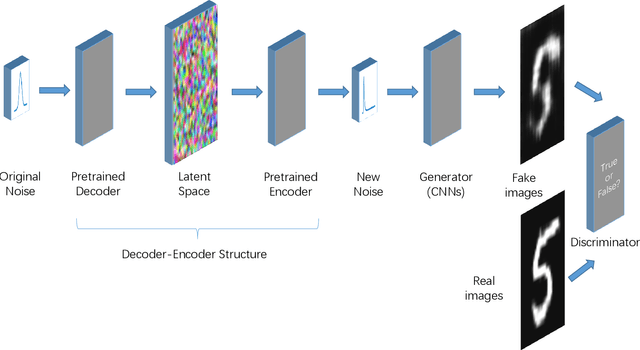
In recent years, research on image generation methods has been developing fast. The auto-encoding variational Bayes method (VAEs) was proposed in 2013, which uses variational inference to learn a latent space from the image database and then generates images using the decoder. The generative adversarial networks (GANs) came out as a promising framework, which uses adversarial training to improve the generative ability of the generator. However, the generated pictures by GANs are generally blurry. The deep convolutional generative adversarial networks (DCGANs) were then proposed to leverage the quality of generated images. Since the input noise vectors are randomly sampled from a Gaussian distribution, the generator has to map from a whole normal distribution to the images. This makes DCGANs unable to reflect the inherent structure of the training data. In this paper, we propose a novel deep model, called generative adversarial networks with decoder-encoder output noise (DE-GANs), which takes advantage of both the adversarial training and the variational Bayesain inference to improve the performance of image generation. DE-GANs use a pre-trained decoder-encoder architecture to map the random Gaussian noise vectors to informative ones and pass them to the generator of the adversarial networks. Since the decoder-encoder architecture is trained by the same images as the generators, the output vectors could carry the intrinsic distribution information of the original images. Moreover, the loss function of DE-GANs is different from GANs and DCGANs. A hidden-space loss function is added to the adversarial loss function to enhance the robustness of the model. Extensive empirical results show that DE-GANs can accelerate the convergence of the adversarial training process and improve the quality of the generated images.