 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBailicai: A Domain-Optimized Retrieval-Augmented Generation Framework for Medical Applications
Jul 24, 2024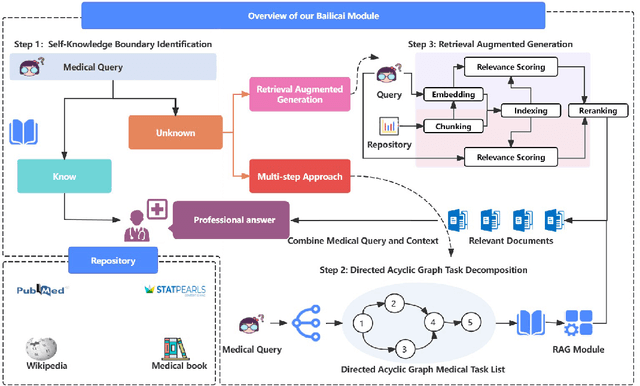
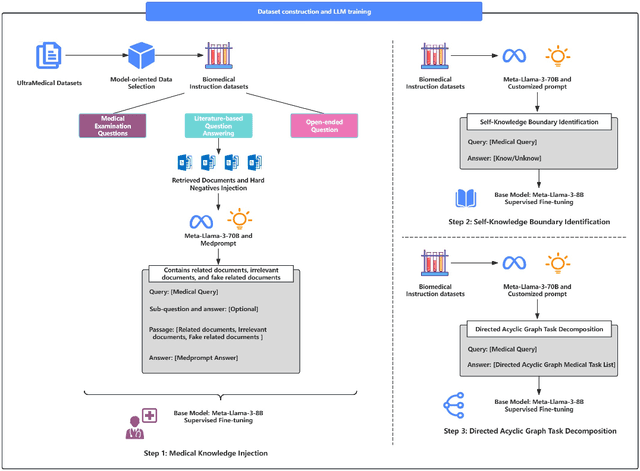
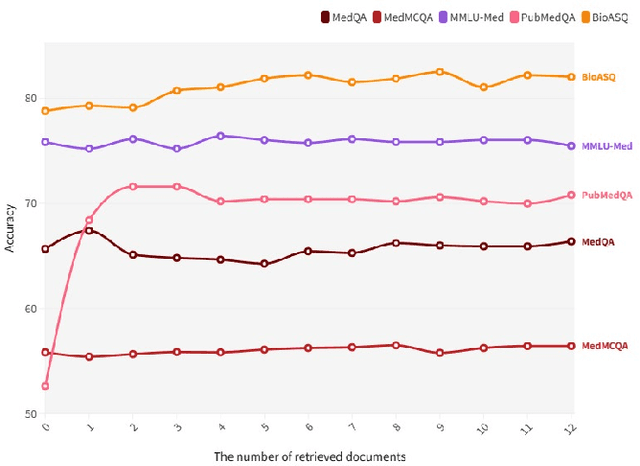

Large Language Models (LLMs) have exhibited remarkable proficiency in natural language understanding, prompting extensive exploration of their potential applications across diverse domains. In the medical domain, open-source LLMs have demonstrated moderate efficacy following domain-specific fine-tuning; however, they remain substantially inferior to proprietary models such as GPT-4 and GPT-3.5. These open-source models encounter limitations in the comprehensiveness of domain-specific knowledge and exhibit a propensity for 'hallucinations' during text generation. To mitigate these issues, researchers have implemented the Retrieval-Augmented Generation (RAG) approach, which augments LLMs with background information from external knowledge bases while preserving the model's internal parameters. However, document noise can adversely affect performance, and the application of RAG in the medical field remains in its nascent stages. This study presents the Bailicai framework: a novel integration of retrieval-augmented generation with large language models optimized for the medical domain. The Bailicai framework augments the performance of LLMs in medicine through the implementation of four sub-modules. Experimental results demonstrate that the Bailicai approach surpasses existing medical domain LLMs across multiple medical benchmarks and exceeds the performance of GPT-3.5. Furthermore, the Bailicai method effectively attenuates the prevalent issue of hallucinations in medical applications of LLMs and ameliorates the noise-related challenges associated with traditional RAG techniques when processing irrelevant or pseudo-relevant documents.
Causal Interventions-based Few-Shot Named Entity Recognition
May 03, 2023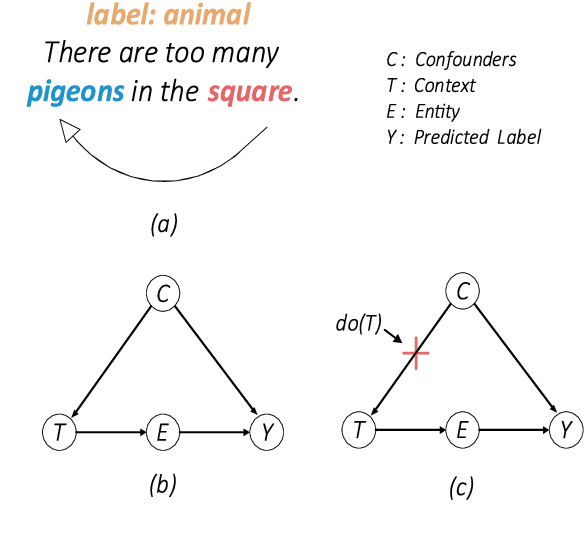
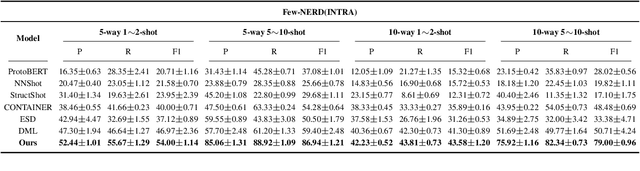
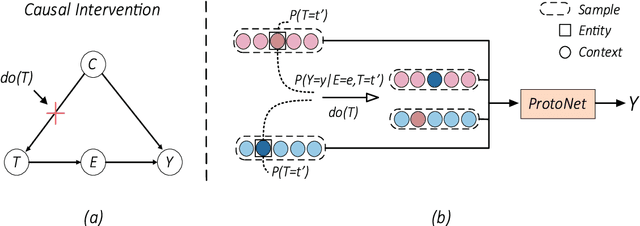
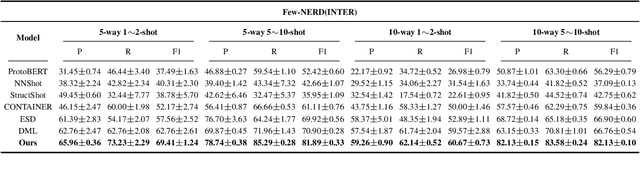
Few-shot named entity recognition (NER) systems aims at recognizing new classes of entities based on a few labeled samples. A significant challenge in the few-shot regime is prone to overfitting than the tasks with abundant samples. The heavy overfitting in few-shot learning is mainly led by spurious correlation caused by the few samples selection bias. To alleviate the problem of the spurious correlation in the few-shot NER, in this paper, we propose a causal intervention-based few-shot NER method. Based on the prototypical network, the method intervenes in the context and prototype via backdoor adjustment during training. In particular, intervening in the context of the one-shot scenario is very difficult, so we intervene in the prototype via incremental learning, which can also avoid catastrophic forgetting. Our experiments on different benchmarks show that our approach achieves new state-of-the-art results (achieving up to 29% absolute improvement and 12% on average for all tasks).