 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault-Aware Design and Training to Enhance DNNs Reliability with Zero-Overhead
May 28, 2022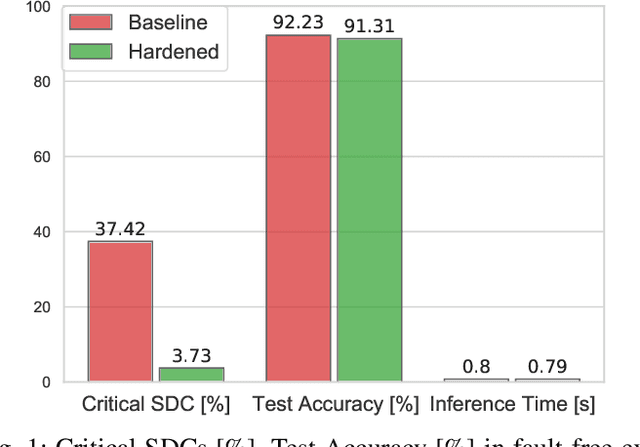
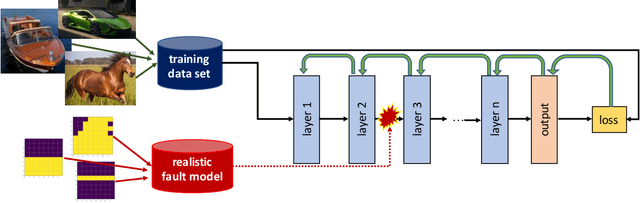
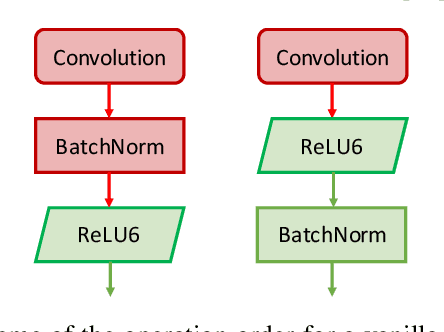
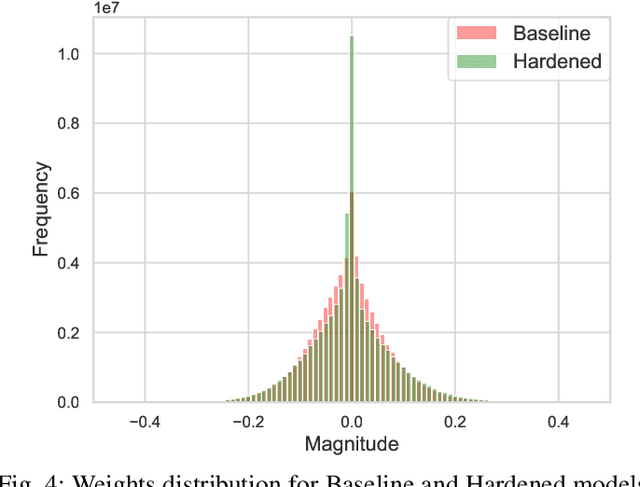
Deep Neural Networks (DNNs) enable a wide series of technological advancements, ranging from clinical imaging, to predictive industrial maintenance and autonomous driving. However, recent findings indicate that transient hardware faults may corrupt the models prediction dramatically. For instance, the radiation-induced misprediction probability can be so high to impede a safe deployment of DNNs models at scale, urging the need for efficient and effective hardening solutions. In this work, we propose to tackle the reliability issue both at training and model design time. First, we show that vanilla models are highly affected by transient faults, that can induce a performances drop up to 37%. Hence, we provide three zero-overhead solutions, based on DNN re-design and re-train, that can improve DNNs reliability to transient faults up to one order of magnitude. We complement our work with extensive ablation studies to quantify the gain in performances of each hardening component.