 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric zone-aware action recognition across environments
Sep 21, 2024



Human activities exhibit a strong correlation between actions and the places where these are performed, such as washing something at a sink. More specifically, in daily living environments we may identify particular locations, hereinafter named activity-centric zones, which may afford a set of homogeneous actions. Their knowledge can serve as a prior to favor vision models to recognize human activities. However, the appearance of these zones is scene-specific, limiting the transferability of this prior information to unfamiliar areas and domains. This problem is particularly relevant in egocentric vision, where the environment takes up most of the image, making it even more difficult to separate the action from the context. In this paper, we discuss the importance of decoupling the domain-specific appearance of activity-centric zones from their universal, domain-agnostic representations, and show how the latter can improve the cross-domain transferability of Egocentric Action Recognition (EAR) models. We validate our solution on the EPIC-Kitchens-100 and Argo1M datasets
A brief history of AI: how to prevent another winter
Sep 08, 2021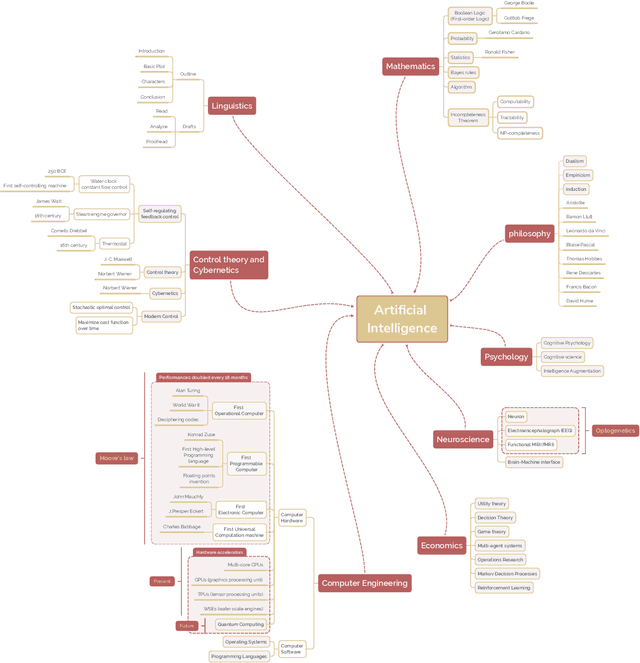
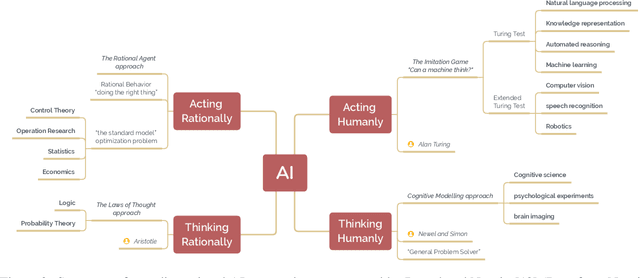
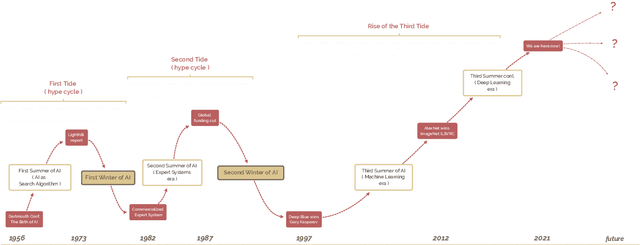

The field of artificial intelligence (AI), regarded as one of the most enigmatic areas of science, has witnessed exponential growth in the past decade including a remarkably wide array of applications, having already impacted our everyday lives. Advances in computing power and the design of sophisticated AI algorithms have enabled computers to outperform humans in a variety of tasks, especially in the areas of computer vision and speech recognition. Yet, AI's path has never been smooth, having essentially fallen apart twice in its lifetime ('winters' of AI), both after periods of popular success ('summers' of AI). We provide a brief rundown of AI's evolution over the course of decades, highlighting its crucial moments and major turning points from inception to the present. In doing so, we attempt to learn, anticipate the future, and discuss what steps may be taken to prevent another 'winter'.
DA4Event: towards bridging the Sim-to-Real Gap for Event Cameras using Domain Adaptation
Mar 23, 2021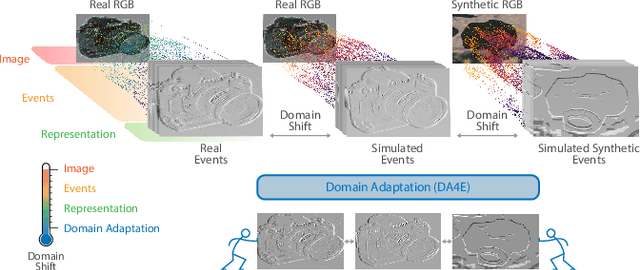

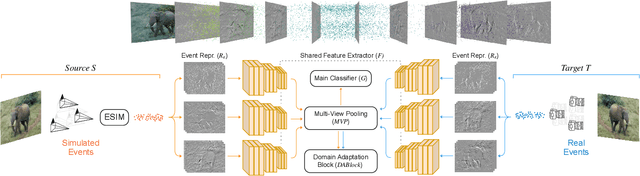

Event cameras are novel bio-inspired sensors, which asynchronously capture pixel-level intensity changes in the form of "events". The innovative way they acquire data presents several advantages over standard devices, especially in poor lighting and high-speed motion conditions. However, the novelty of these sensors results in the lack of a large amount of training data capable of fully unlocking their potential. The most common approach implemented by researchers to address this issue is to leverage simulated event data. Yet, this approach comes with an open research question: how well simulated data generalize to real data? To answer this, we propose to exploit, in the event-based context, recent Domain Adaptation (DA) advances in traditional computer vision, showing that DA techniques applied to event data help reduce the sim-to-real gap. To this purpose, we propose a novel architecture, which we call Multi-View DA4E (MV-DA4E), that better exploits the peculiarities of frame-based event representations while also promoting domain invariant characteristics in features. Through extensive experiments, we prove the effectiveness of DA methods and MV-DA4E on N-Caltech101. Moreover, we validate their soundness in a real-world scenario through a cross-domain analysis on the popular RGB-D Object Dataset (ROD), which we extended to the event modality (RGB-E).
Joint Encoding of Appearance and Motion Features with Self-supervision for First Person Action Recognition
Feb 10, 2020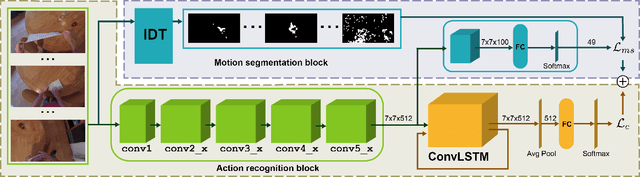
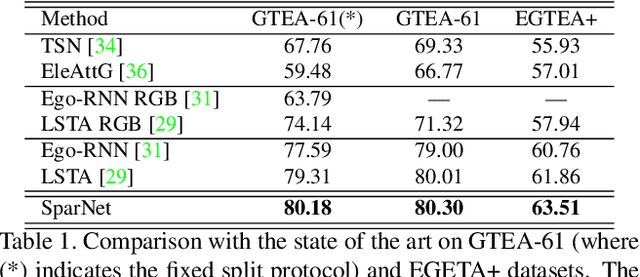

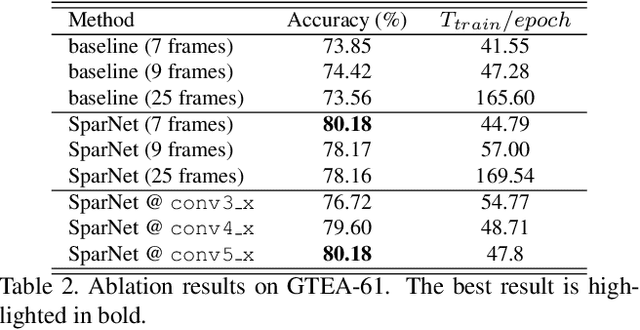
Wearable cameras are becoming more and more popular in several applications, increasing the interest of the research community in developing approaches for recognizing actions from a first-person point of view. An open challenge is how to cope with the limited amount of motion information available about the action itself, as opposed to the more investigated third-person action recognition scenario. When focusing on manipulation tasks, videos tend to record only parts of the movement, making crucial the understanding of the objects being manipulated and of their context. Previous works addressed this issue with two-stream architectures, one dedicated to modeling the appearance of objects involved in the action, another dedicated to extracting motion features from optical flow. In this paper, we argue that features from these two information channels should be learned jointly to capture the spatio-temporal correlations between the two in a better way. To this end, we propose a single stream architecture able to do so, thanks to the addition of a self-supervised block that uses a pretext motion segmentation task to intertwine motion and appearance knowledge. Experiments on several publicly available databases show the power of our approach.