 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslate to Adapt: RGB-D Scene Recognition across Domains
Paper and Code
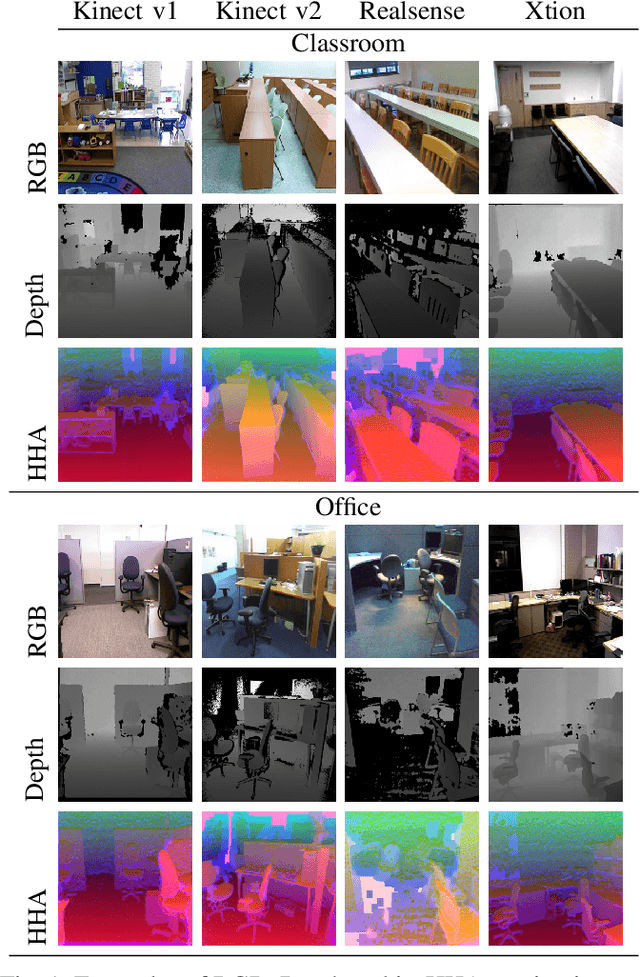
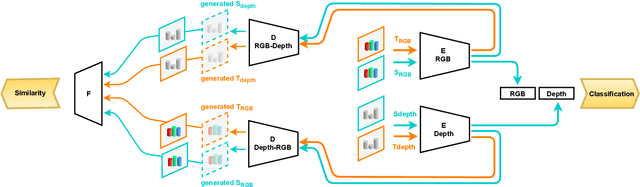


Scene classification is one of the basic problems in computer vision research with extensive applications in robotics. When available, depth images provide helpful geometric cues that complement the RGB texture information and help to identify more discriminative scene image features. Depth sensing technology developed fast in the last years and a great variety of 3D cameras have been introduced, each with different acquisition properties. However, when targeting big data collections, often multi-modal images are gathered disregarding their original nature. In this work we put under the spotlight the existence of a possibly severe domain shift issue within multi-modality scene recognition datasets. We design an experimental testbed to study this problem and present a method based on self-supervised inter-modality translation able to adapt across different camera domains. Our extensive experimental analysis confirms the effectiveness of the proposed approach.