 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Self-Supervised Models Transfer? Investigating the Impact of Invariance on Downstream Tasks
Paper and Code
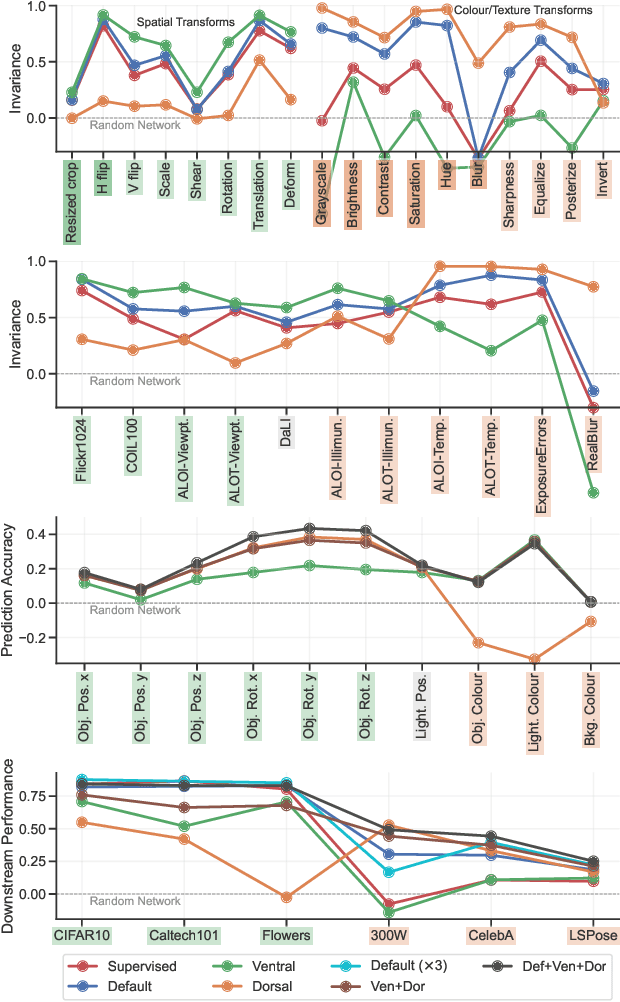


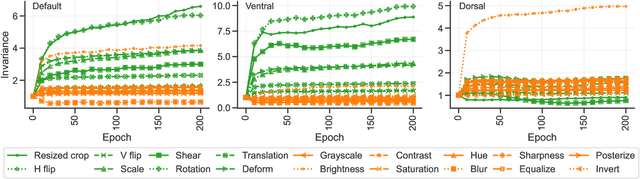
Self-supervised learning is a powerful paradigm for representation learning on unlabelled images. A wealth of effective new methods based on instance matching rely on data augmentation to drive learning, and these have reached a rough agreement on an augmentation scheme that optimises popular recognition benchmarks. However, there is strong reason to suspect that different tasks in computer vision require features to encode different (in)variances, and therefore likely require different augmentation strategies. In this paper, we measure the invariances learned by contrastive methods and confirm that they do learn invariance to the augmentations used and further show that this invariance largely transfers to related real-world changes in pose and lighting. We show that learned invariances strongly affect downstream task performance and confirm that different downstream tasks benefit from polar opposite (in)variances, leading to performance loss when the standard augmentation strategy is used. Finally, we demonstrate that a simple fusion of representations with complementary invariances ensures wide transferability to all the diverse downstream tasks considered.