 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representation Learning: Introduction, Advances and Challenges
Paper and Code
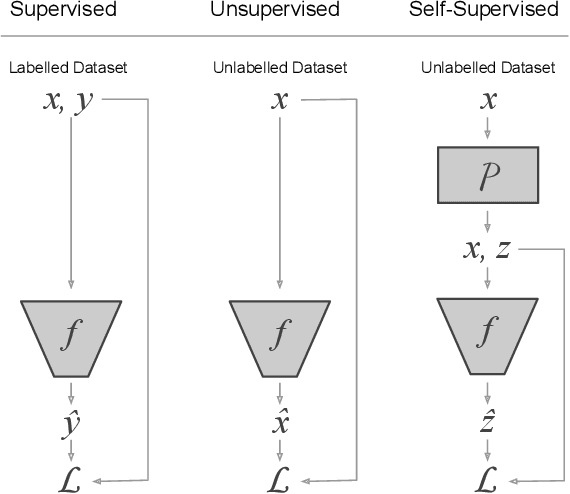
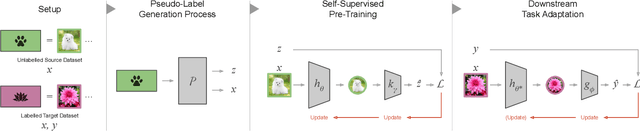
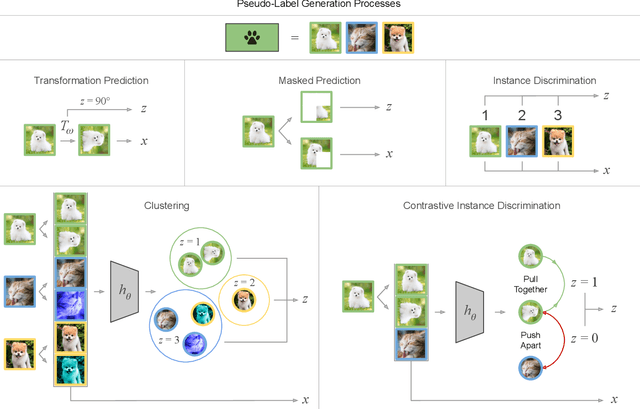

Self-supervised representation learning methods aim to provide powerful deep feature learning without the requirement of large annotated datasets, thus alleviating the annotation bottleneck that is one of the main barriers to practical deployment of deep learning today. These methods have advanced rapidly in recent years, with their efficacy approaching and sometimes surpassing fully supervised pre-training alternatives across a variety of data modalities including image, video, sound, text and graphs. This article introduces this vibrant area including key concepts, the four main families of approach and associated state of the art, and how self-supervised methods are applied to diverse modalities of data. We further discuss practical considerations including workflows, representation transferability, and compute cost. Finally, we survey the major open challenges in the field that provide fertile ground for future work.