 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning assisted Port-Cycling based Channel Sounding for Precoder Estimation in Massive MIMO Arrays
Jan 21, 2026Future wireless systems are expected to employ a substantially larger number of transmit ports for channel state information (CSI) estimation compared to current specifications. Although scaling ports improves spectral efficiency, it also increases the resource overhead to transmit reference signals across the time-frequency grid, ultimately reducing achievable data throughput. In this work, we propose an deep learning (DL)-based CSI reconstruction framework that serves as an enabler for reliable CSI acquisition in future 6G systems. The proposed solution involves designing a port-cycling mechanism that sequentially sounds different portions of CSI ports across time, thereby lowering the overhead while preserving channel observability. The proposed CSI Adaptive Network (CsiAdaNet) model exploits the resulting sparse measurements and captures both spatial and temporal correlations to accurately reconstruct the full-port CSI. The simulation results show that our method achieves overhead reduction while maintaining high CSI reconstruction accuracy.
Audio-Visual Speech Separation via Bottleneck Iterative Network
Jul 09, 2025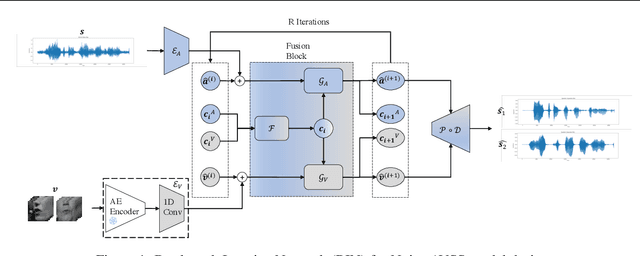
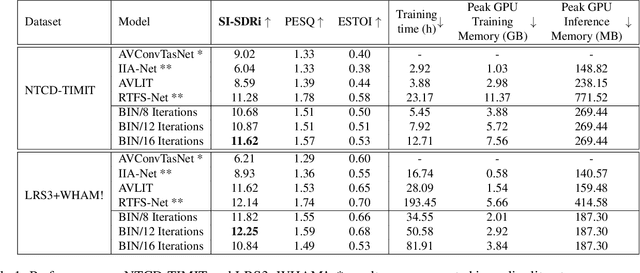
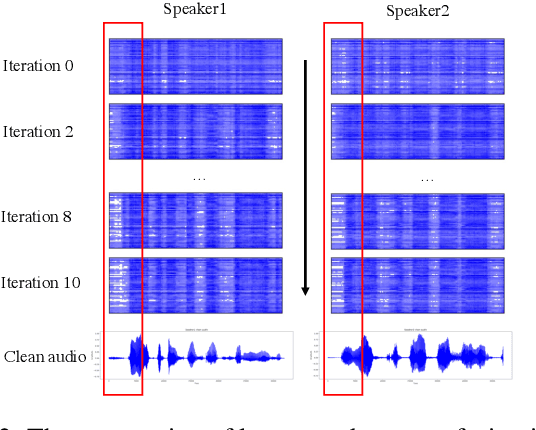
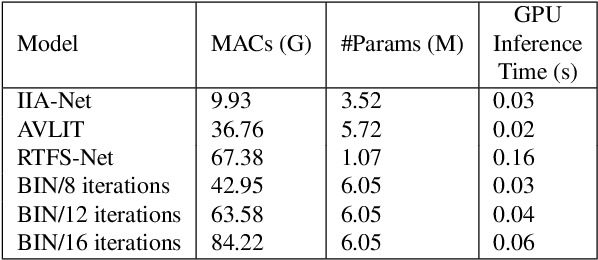
Integration of information from non-auditory cues can significantly improve the performance of speech-separation models. Often such models use deep modality-specific networks to obtain unimodal features, and risk being too costly or lightweight but lacking capacity. In this work, we present an iterative representation refinement approach called Bottleneck Iterative Network (BIN), a technique that repeatedly progresses through a lightweight fusion block, while bottlenecking fusion representations by fusion tokens. This helps improve the capacity of the model, while avoiding major increase in model size and balancing between the model performance and training cost. We test BIN on challenging noisy audio-visual speech separation tasks, and show that our approach consistently outperforms state-of-the-art benchmark models with respect to SI-SDRi on NTCD-TIMIT and LRS3+WHAM! datasets, while simultaneously achieving a reduction of more than 50% in training and GPU inference time across nearly all settings.
Learning Straight Flows by Learning Curved Interpolants
Mar 26, 2025



Flow matching models typically use linear interpolants to define the forward/noise addition process. This, together with the independent coupling between noise and target distributions, yields a vector field which is often non-straight. Such curved fields lead to a slow inference/generation process. In this work, we propose to learn flexible (potentially curved) interpolants in order to learn straight vector fields to enable faster generation. We formulate this via a multi-level optimization problem and propose an efficient approximate procedure to solve it. Our framework provides an end-to-end and simulation-free optimization procedure, which can be leveraged to learn straight line generative trajectories.
A/B testing under Interference with Partial Network Information
Apr 16, 2024



A/B tests are often required to be conducted on subjects that might have social connections. For e.g., experiments on social media, or medical and social interventions to control the spread of an epidemic. In such settings, the SUTVA assumption for randomized-controlled trials is violated due to network interference, or spill-over effects, as treatments to group A can potentially also affect the control group B. When the underlying social network is known exactly, prior works have demonstrated how to conduct A/B tests adequately to estimate the global average treatment effect (GATE). However, in practice, it is often impossible to obtain knowledge about the exact underlying network. In this paper, we present UNITE: a novel estimator that relax this assumption and can identify GATE while only relying on knowledge of the superset of neighbors for any subject in the graph. Through theoretical analysis and extensive experiments, we show that the proposed approach performs better in comparison to standard estimators.
Adaptive Instrument Design for Indirect Experiments
Dec 05, 2023



Indirect experiments provide a valuable framework for estimating treatment effects in situations where conducting randomized control trials (RCTs) is impractical or unethical. Unlike RCTs, indirect experiments estimate treatment effects by leveraging (conditional) instrumental variables, enabling estimation through encouragement and recommendation rather than strict treatment assignment. However, the sample efficiency of such estimators depends not only on the inherent variability in outcomes but also on the varying compliance levels of users with the instrumental variables and the choice of estimator being used, especially when dealing with numerous instrumental variables. While adaptive experiment design has a rich literature for direct experiments, in this paper we take the initial steps towards enhancing sample efficiency for indirect experiments by adaptively designing a data collection policy over instrumental variables. Our main contribution is a practical computational procedure that utilizes influence functions to search for an optimal data collection policy, minimizing the mean-squared error of the desired (non-linear) estimator. Through experiments conducted in various domains inspired by real-world applications, we showcase how our method can significantly improve the sample efficiency of indirect experiments.
Optimization using Parallel Gradient Evaluations on Multiple Parameters
Feb 06, 2023We propose a first-order method for convex optimization, where instead of being restricted to the gradient from a single parameter, gradients from multiple parameters can be used during each step of gradient descent. This setup is particularly useful when a few processors are available that can be used in parallel for optimization. Our method uses gradients from multiple parameters in synergy to update these parameters together towards the optima. While doing so, it is ensured that the computational and memory complexity is of the same order as that of gradient descent. Empirical results demonstrate that even using gradients from as low as \textit{two} parameters, our method can often obtain significant acceleration and provide robustness to hyper-parameter settings. We remark that the primary goal of this work is less theoretical, and is instead aimed at exploring the understudied case of using multiple gradients during each step of optimization.
Off-Policy Evaluation for Action-Dependent Non-Stationary Environments
Jan 24, 2023Methods for sequential decision-making are often built upon a foundational assumption that the underlying decision process is stationary. This limits the application of such methods because real-world problems are often subject to changes due to external factors (passive non-stationarity), changes induced by interactions with the system itself (active non-stationarity), or both (hybrid non-stationarity). In this work, we take the first steps towards the fundamental challenge of on-policy and off-policy evaluation amidst structured changes due to active, passive, or hybrid non-stationarity. Towards this goal, we make a higher-order stationarity assumption such that non-stationarity results in changes over time, but the way changes happen is fixed. We propose, OPEN, an algorithm that uses a double application of counterfactual reasoning and a novel importance-weighted instrument-variable regression to obtain both a lower bias and a lower variance estimate of the structure in the changes of a policy's past performances. Finally, we show promising results on how OPEN can be used to predict future performances for several domains inspired by real-world applications that exhibit non-stationarity.
Implicit Training of Energy Model for Structure Prediction
Nov 21, 2022Most deep learning research has focused on developing new model and training procedures. On the other hand the training objective has usually been restricted to combinations of standard losses. When the objective aligns well with the evaluation metric, this is not a major issue. However when dealing with complex structured outputs, the ideal objective can be hard to optimize and the efficacy of usual objectives as a proxy for the true objective can be questionable. In this work, we argue that the existing inference network based structure prediction methods ( Tu and Gimpel 2018; Tu, Pang, and Gimpel 2020) are indirectly learning to optimize a dynamic loss objective parameterized by the energy model. We then explore using implicit-gradient based technique to learn the corresponding dynamic objectives. Our experiments show that implicitly learning a dynamic loss landscape is an effective method for improving model performance in structure prediction.
Privacy Aware Experiments without Cookies
Nov 03, 2022
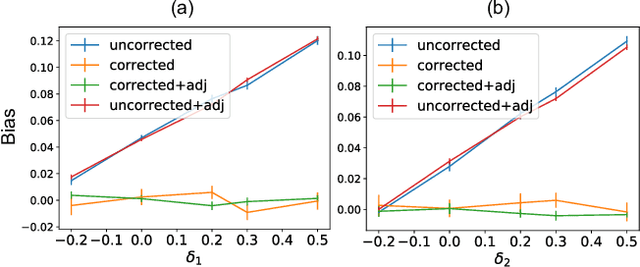
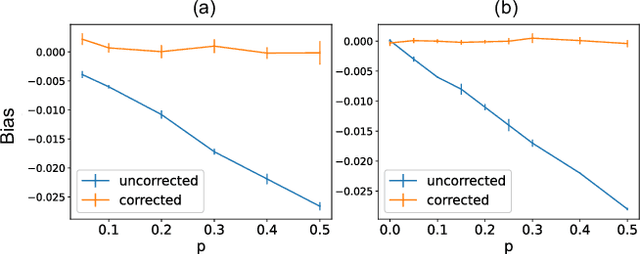
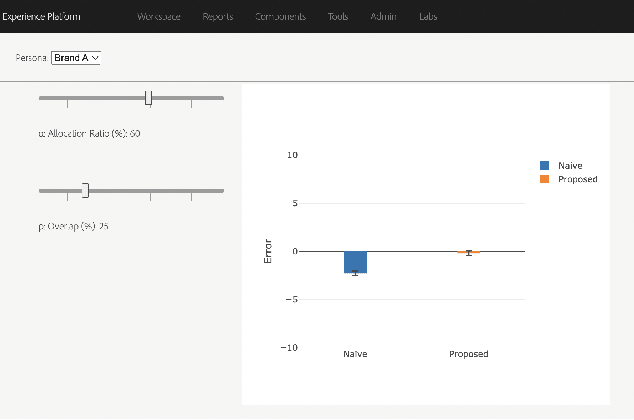
Consider two brands that want to jointly test alternate web experiences for their customers with an A/B test. Such collaborative tests are today enabled using \textit{third-party cookies}, where each brand has information on the identity of visitors to another website. With the imminent elimination of third-party cookies, such A/B tests will become untenable. We propose a two-stage experimental design, where the two brands only need to agree on high-level aggregate parameters of the experiment to test the alternate experiences. Our design respects the privacy of customers. We propose an estimater of the Average Treatment Effect (ATE), show that it is unbiased and theoretically compute its variance. Our demonstration describes how a marketer for a brand can design such an experiment and analyze the results. On real and simulated data, we show that the approach provides valid estimate of the ATE with low variance and is robust to the proportion of visitors overlapping across the brands.
Neural Dependency Coding inspired Multimodal Fusion
Oct 04, 2021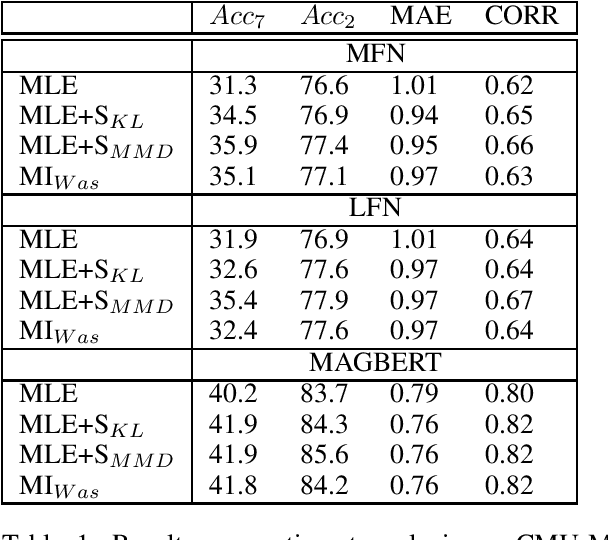
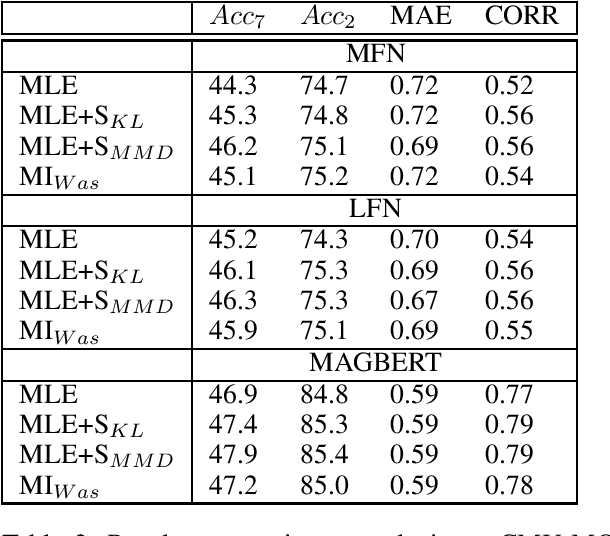
Information integration from different modalities is an active area of research. Human beings and, in general, biological neural systems are quite adept at using a multitude of signals from different sensory perceptive fields to interact with the environment and each other. Recent work in deep fusion models via neural networks has led to substantial improvements over unimodal approaches in areas like speech recognition, emotion recognition and analysis, captioning and image description. However, such research has mostly focused on architectural changes allowing for fusion of different modalities while keeping the model complexity manageable. Inspired by recent neuroscience ideas about multisensory integration and processing, we investigate the effect of synergy maximizing loss functions. Experiments on multimodal sentiment analysis tasks: CMU-MOSI and CMU-MOSEI with different models show that our approach provides a consistent performance boost.