 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Black-Box Optimization
Jun 12, 2023



The goal of offline black-box optimization (BBO) is to optimize an expensive black-box function using a fixed dataset of function evaluations. Prior works consider forward approaches that learn surrogates to the black-box function and inverse approaches that directly map function values to corresponding points in the input domain of the black-box function. These approaches are limited by the quality of the offline dataset and the difficulty in learning one-to-many mappings in high dimensions, respectively. We propose Denoising Diffusion Optimization Models (DDOM), a new inverse approach for offline black-box optimization based on diffusion models. Given an offline dataset, DDOM learns a conditional generative model over the domain of the black-box function conditioned on the function values. We investigate several design choices in DDOM, such as re-weighting the dataset to focus on high function values and the use of classifier-free guidance at test-time to enable generalization to function values that can even exceed the dataset maxima. Empirically, we conduct experiments on the Design-Bench benchmark and show that DDOM achieves results competitive with state-of-the-art baselines.
Generative Pretraining for Black-Box Optimization
Jun 22, 2022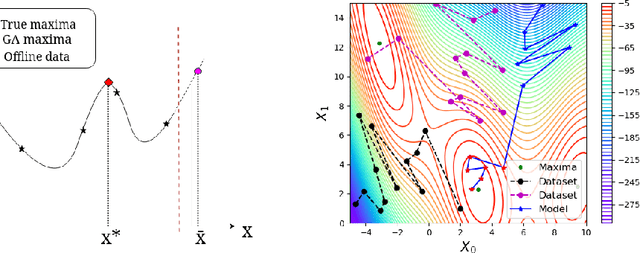


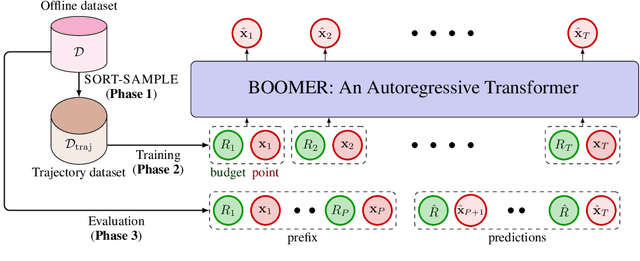
Many problems in science and engineering involve optimizing an expensive black-box function over a high-dimensional space. For such black-box optimization (BBO) problems, we typically assume a small budget for online function evaluations, but also often have access to a fixed, offline dataset for pretraining. Prior approaches seek to utilize the offline data to approximate the function or its inverse but are not sufficiently accurate far from the data distribution. We propose Black-box Optimization Transformer (BOOMER), a generative framework for pretraining black-box optimizers using offline datasets. In BOOMER, we train an autoregressive model to imitate trajectory runs of implicit black-box function optimizers. Since these trajectories are unavailable by default, we develop a simple randomized heuristic to synthesize trajectories by sorting random points from offline data. We show theoretically that this heuristic induces trajectories that mimic transitions from diverse low-fidelity (exploration) to high-fidelity (exploitation) samples. Further, we introduce mechanisms to control the rate at which a trajectory transitions from exploration to exploitation, and use it to generalize outside the offline data at test-time. Empirically, we instantiate BOOMER using a casually masked Transformer and evaluate it on Design-Bench, where we rank the best on average, outperforming state-of-the-art baselines.
Data-Driven Compression of Convolutional Neural Networks
Nov 28, 2019
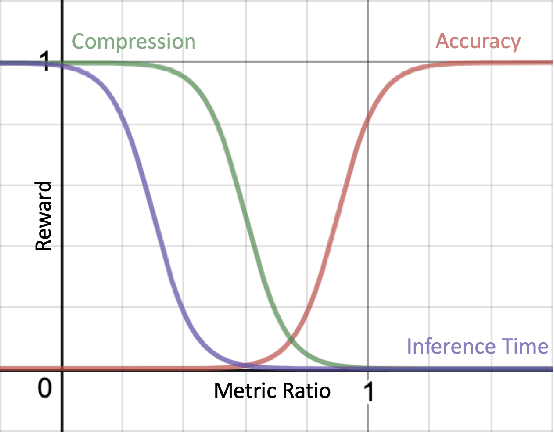
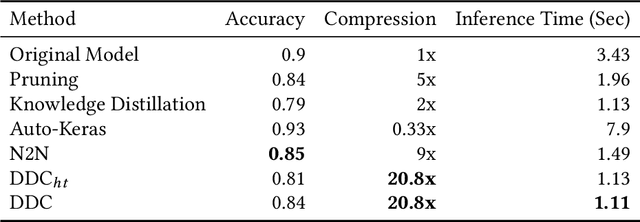
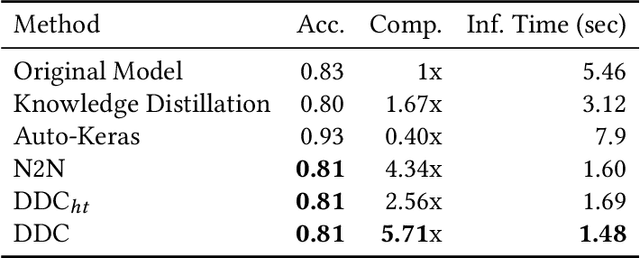
Deploying trained convolutional neural networks (CNNs) to mobile devices is a challenging task because of the simultaneous requirements of the deployed model to be fast, lightweight and accurate. Designing and training a CNN architecture that does well on all three metrics is highly non-trivial and can be very time-consuming if done by hand. One way to solve this problem is to compress the trained CNN models before deploying to mobile devices. This work asks and answers three questions on compressing CNN models automatically: a) How to control the trade-off between speed, memory and accuracy during model compression? b) In practice, a deployed model may not see all classes and/or may not need to produce all class labels. Can this fact be used to improve the trade-off? c) How to scale the compression algorithm to execute within a reasonable amount of time for many deployments? The paper demonstrates that a model compression algorithm utilizing reinforcement learning with architecture search and knowledge distillation can answer these questions in the affirmative. Experimental results are provided for current state-of-the-art CNN model families for image feature extraction like VGG and ResNet with CIFAR datasets.