 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Blending for Text Classification
Aug 05, 2022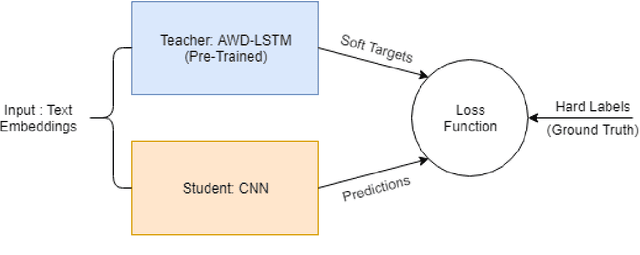

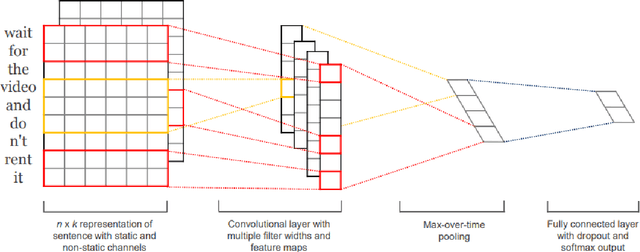

Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Data-Driven Compression of Convolutional Neural Networks
Nov 28, 2019
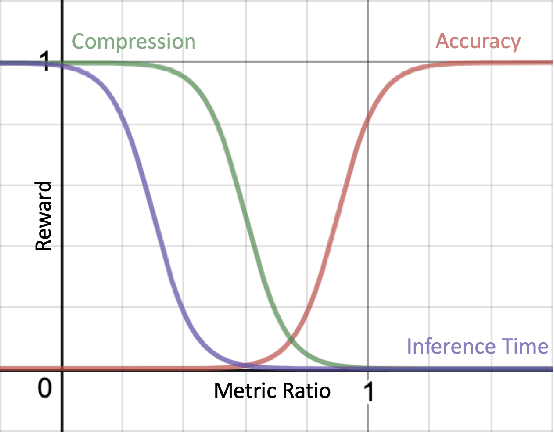
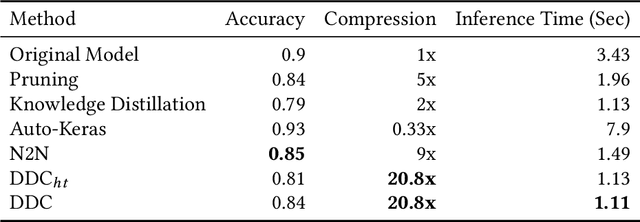
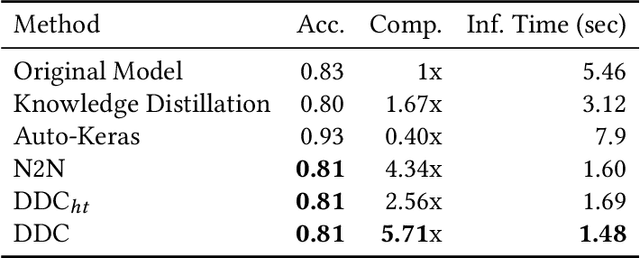
Deploying trained convolutional neural networks (CNNs) to mobile devices is a challenging task because of the simultaneous requirements of the deployed model to be fast, lightweight and accurate. Designing and training a CNN architecture that does well on all three metrics is highly non-trivial and can be very time-consuming if done by hand. One way to solve this problem is to compress the trained CNN models before deploying to mobile devices. This work asks and answers three questions on compressing CNN models automatically: a) How to control the trade-off between speed, memory and accuracy during model compression? b) In practice, a deployed model may not see all classes and/or may not need to produce all class labels. Can this fact be used to improve the trade-off? c) How to scale the compression algorithm to execute within a reasonable amount of time for many deployments? The paper demonstrates that a model compression algorithm utilizing reinforcement learning with architecture search and knowledge distillation can answer these questions in the affirmative. Experimental results are provided for current state-of-the-art CNN model families for image feature extraction like VGG and ResNet with CIFAR datasets.
LSTMs with Attention for Aggression Detection
Jul 16, 2018
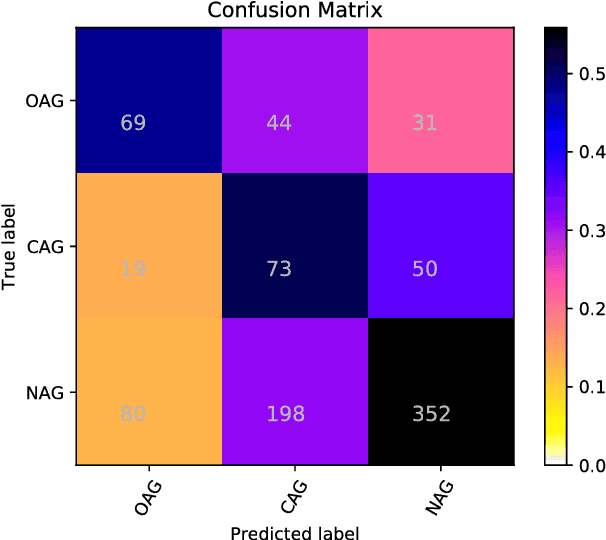
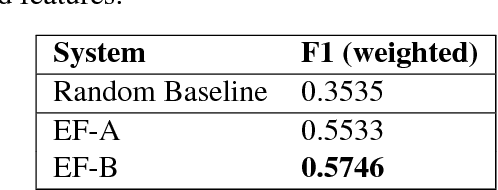
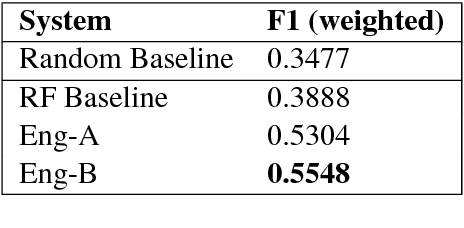
In this paper, we describe the system submitted for the shared task on Aggression Identification in Facebook posts and comments by the team Nishnik. Previous works demonstrate that LSTMs have achieved remarkable performance in natural language processing tasks. We deploy an LSTM model with an attention unit over it. Our system ranks 6th and 4th in the Hindi subtask for Facebook comments and subtask for generalized social media data respectively. And it ranks 17th and 10th in the corresponding English subtasks.