 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Compression of Convolutional Neural Networks
Paper and Code
Nov 28, 2019
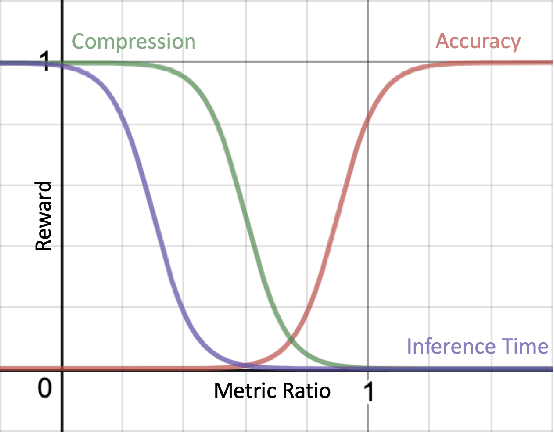
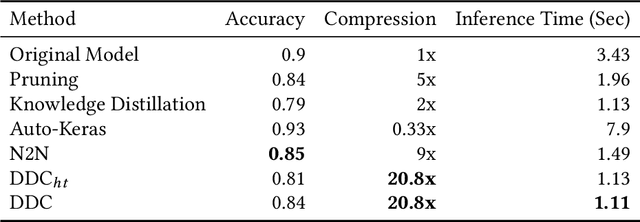
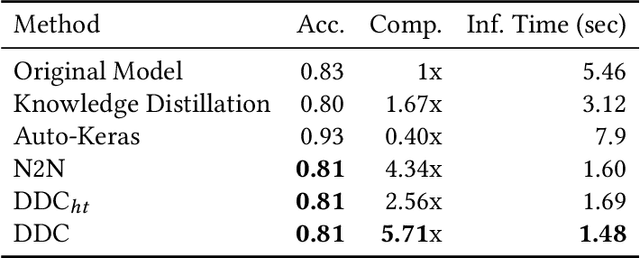
Deploying trained convolutional neural networks (CNNs) to mobile devices is a challenging task because of the simultaneous requirements of the deployed model to be fast, lightweight and accurate. Designing and training a CNN architecture that does well on all three metrics is highly non-trivial and can be very time-consuming if done by hand. One way to solve this problem is to compress the trained CNN models before deploying to mobile devices. This work asks and answers three questions on compressing CNN models automatically: a) How to control the trade-off between speed, memory and accuracy during model compression? b) In practice, a deployed model may not see all classes and/or may not need to produce all class labels. Can this fact be used to improve the trade-off? c) How to scale the compression algorithm to execute within a reasonable amount of time for many deployments? The paper demonstrates that a model compression algorithm utilizing reinforcement learning with architecture search and knowledge distillation can answer these questions in the affirmative. Experimental results are provided for current state-of-the-art CNN model families for image feature extraction like VGG and ResNet with CIFAR datasets.