 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPerm: Private and Robust Federated Learning by Parameter Permutation
Aug 16, 2022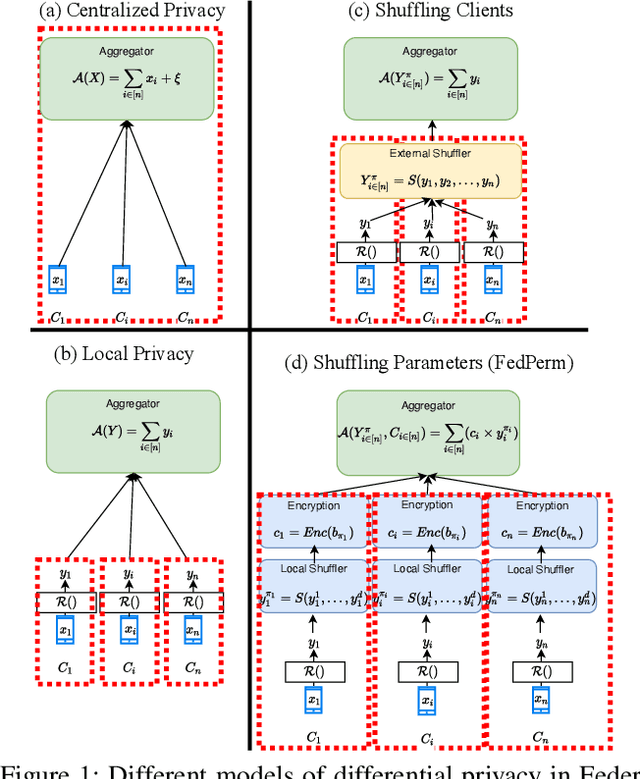

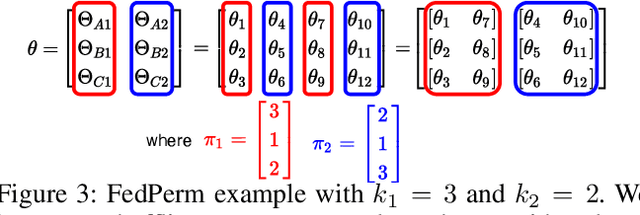
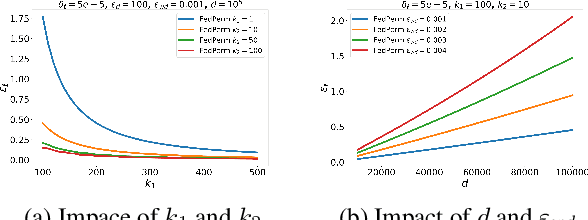
Federated Learning (FL) is a distributed learning paradigm that enables mutually untrusting clients to collaboratively train a common machine learning model. Client data privacy is paramount in FL. At the same time, the model must be protected from poisoning attacks from adversarial clients. Existing solutions address these two problems in isolation. We present FedPerm, a new FL algorithm that addresses both these problems by combining a novel intra-model parameter shuffling technique that amplifies data privacy, with Private Information Retrieval (PIR) based techniques that permit cryptographic aggregation of clients' model updates. The combination of these techniques further helps the federation server constrain parameter updates from clients so as to curtail effects of model poisoning attacks by adversarial clients. We further present FedPerm's unique hyperparameters that can be used effectively to trade off computation overheads with model utility. Our empirical evaluation on the MNIST dataset demonstrates FedPerm's effectiveness over existing Differential Privacy (DP) enforcement solutions in FL.
Optimizing Inference Performance of Transformers on CPUs
Feb 22, 2021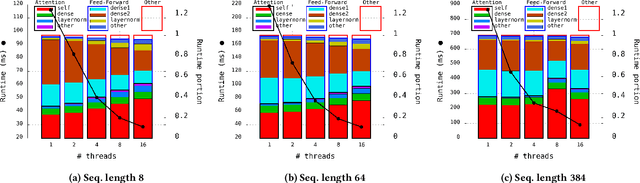
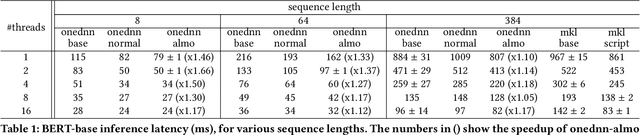
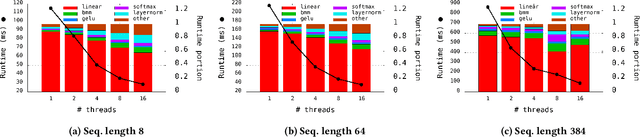
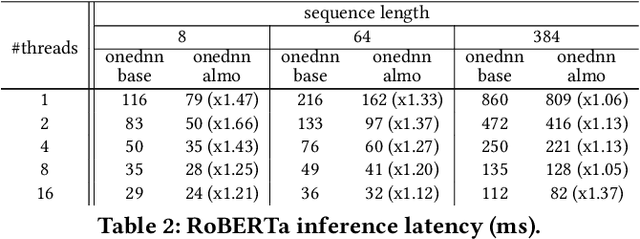
The Transformer architecture revolutionized the field of natural language processing (NLP). Transformers-based models (e.g., BERT) power many important Web services, such as search, translation, question-answering, etc. While enormous research attention is paid to the training of those models, relatively little efforts are made to improve their inference performance. This paper comes to address this gap by presenting an empirical analysis of scalability and performance of inferencing a Transformer-based model on CPUs. Focusing on the highly popular BERT model, we identify key components of the Transformer architecture where the bulk of the computation happens, and propose three optimizations to speed them up. The optimizations are evaluated using the inference benchmark from HuggingFace, and are shown to achieve the speedup of up to x2.37. The considered optimizations do not require any changes to the implementation of the models nor affect their accuracy.