 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermissioned LLMs: Enforcing Access Control in Large Language Models
May 28, 2025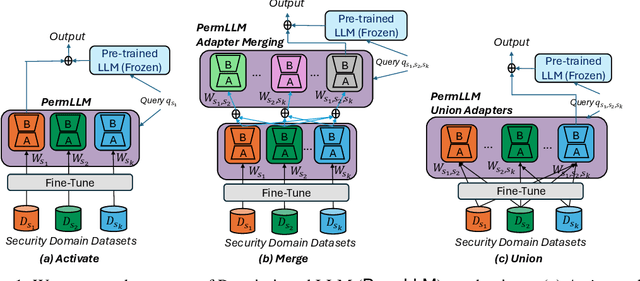

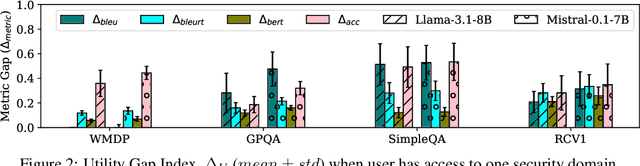
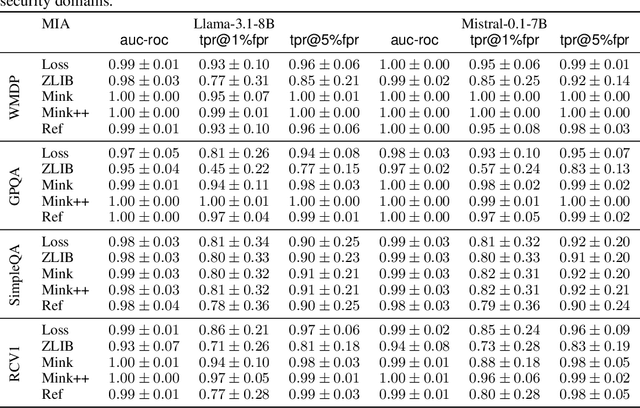
In enterprise settings, organizational data is segregated, siloed and carefully protected by elaborate access control frameworks. These access control structures can completely break down if an LLM fine-tuned on the siloed data serves requests, for downstream tasks, from individuals with disparate access privileges. We propose Permissioned LLMs (PermLLM), a new class of LLMs that superimpose the organizational data access control structures on query responses they generate. We formalize abstractions underpinning the means to determine whether access control enforcement happens correctly over LLM query responses. Our formalism introduces the notion of a relevant response that can be used to prove whether a PermLLM mechanism has been implemented correctly. We also introduce a novel metric, called access advantage, to empirically evaluate the efficacy of a PermLLM mechanism. We introduce three novel PermLLM mechanisms that build on Parameter Efficient Fine-Tuning to achieve the desired access control. We furthermore present two instantiations of access advantage--(i) Domain Distinguishability Index (DDI) based on Membership Inference Attacks, and (ii) Utility Gap Index (UGI) based on LLM utility evaluation. We demonstrate the efficacy of our PermLLM mechanisms through extensive experiments on four public datasets (GPQA, RCV1, SimpleQA, and WMDP), in addition to evaluating the validity of DDI and UGI metrics themselves for quantifying access control in LLMs.
Semantic Membership Inference Attack against Large Language Models
Jun 14, 2024Membership Inference Attacks (MIAs) determine whether a specific data point was included in the training set of a target model. In this paper, we introduce the Semantic Membership Inference Attack (SMIA), a novel approach that enhances MIA performance by leveraging the semantic content of inputs and their perturbations. SMIA trains a neural network to analyze the target model's behavior on perturbed inputs, effectively capturing variations in output probability distributions between members and non-members. We conduct comprehensive evaluations on the Pythia and GPT-Neo model families using the Wikipedia dataset. Our results show that SMIA significantly outperforms existing MIAs; for instance, SMIA achieves an AUC-ROC of 67.39% on Pythia-12B, compared to 58.90% by the second-best attack.
FedPerm: Private and Robust Federated Learning by Parameter Permutation
Aug 16, 2022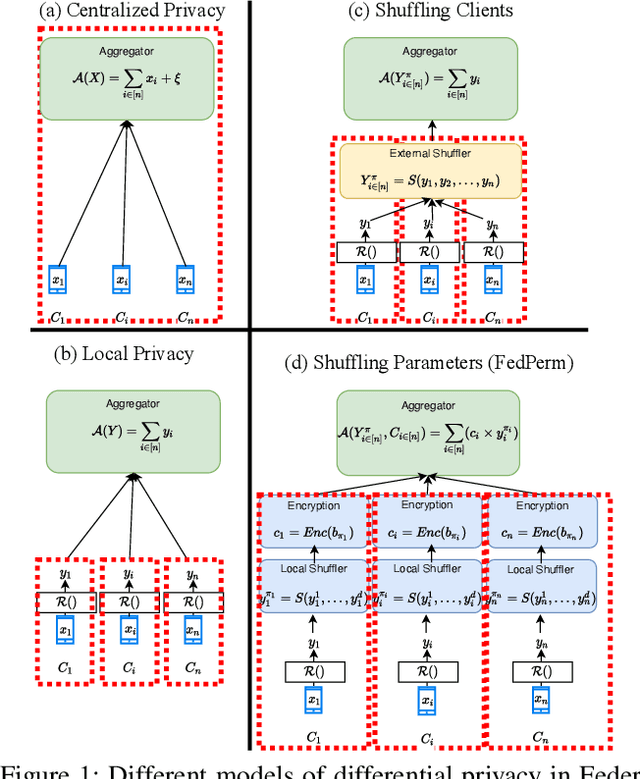

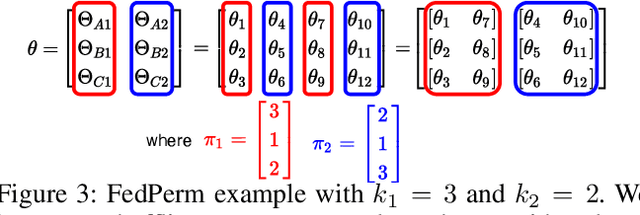
Federated Learning (FL) is a distributed learning paradigm that enables mutually untrusting clients to collaboratively train a common machine learning model. Client data privacy is paramount in FL. At the same time, the model must be protected from poisoning attacks from adversarial clients. Existing solutions address these two problems in isolation. We present FedPerm, a new FL algorithm that addresses both these problems by combining a novel intra-model parameter shuffling technique that amplifies data privacy, with Private Information Retrieval (PIR) based techniques that permit cryptographic aggregation of clients' model updates. The combination of these techniques further helps the federation server constrain parameter updates from clients so as to curtail effects of model poisoning attacks by adversarial clients. We further present FedPerm's unique hyperparameters that can be used effectively to trade off computation overheads with model utility. Our empirical evaluation on the MNIST dataset demonstrates FedPerm's effectiveness over existing Differential Privacy (DP) enforcement solutions in FL.
Subject Granular Differential Privacy in Federated Learning
Jun 07, 2022This paper introduces subject granular privacy in the Federated Learning (FL) setting, where a subject is an individual whose private information is embodied by several data items either confined within a single federation user or distributed across multiple federation users. We formally define the notion of subject level differential privacy for FL. We propose three new algorithms that enforce subject level DP. Two of these algorithms are based on notions of user level local differential privacy (LDP) and group differential privacy respectively. The third algorithm is based on a novel idea of hierarchical gradient averaging (HiGradAvgDP) for subjects participating in a training mini-batch. We also introduce horizontal composition of privacy loss for a subject across multiple federation users. We show that horizontal composition is equivalent to sequential composition in the worst case. We prove the subject level DP guarantee for all our algorithms and empirically analyze them using the FEMNIST and Shakespeare datasets. Our evaluation shows that, of our three algorithms, HiGradAvgDP delivers the best model performance, approaching that of a model trained using a DP-SGD based algorithm that provides a weaker item level privacy guarantee.
Subject Membership Inference Attacks in Federated Learning
Jun 07, 2022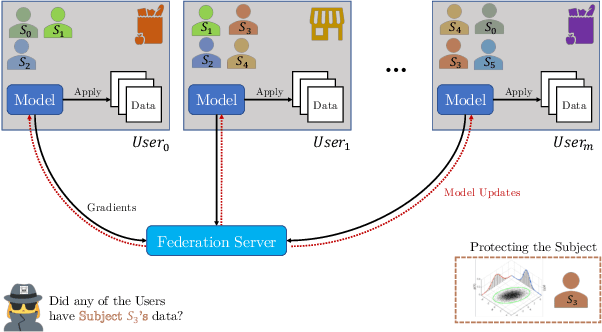
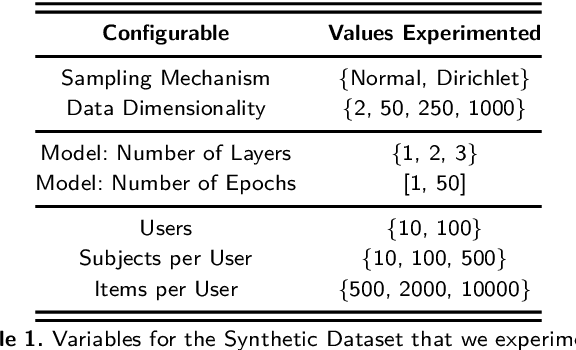
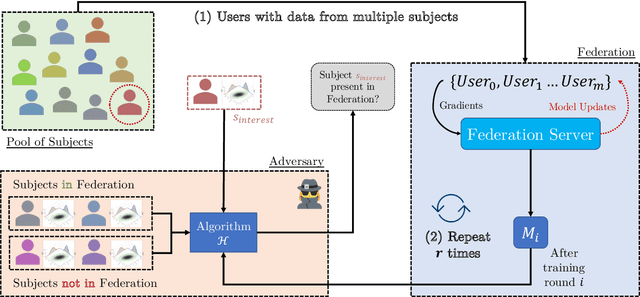
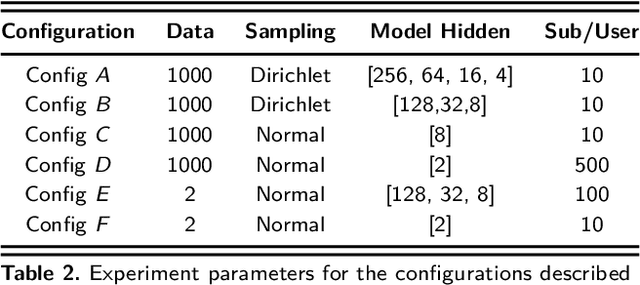
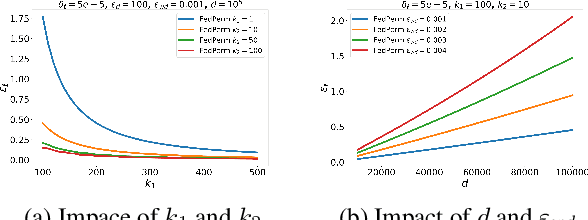
Privacy in Federated Learning (FL) is studied at two different granularities: item-level, which protects individual data points, and user-level, which protects each user (participant) in the federation. Nearly all of the private FL literature is dedicated to studying privacy attacks and defenses at these two granularities. Recently, subject-level privacy has emerged as an alternative privacy granularity to protect the privacy of individuals (data subjects) whose data is spread across multiple (organizational) users in cross-silo FL settings. An adversary might be interested in recovering private information about these individuals (a.k.a. \emph{data subjects}) by attacking the trained model. A systematic study of these patterns requires complete control over the federation, which is impossible with real-world datasets. We design a simulator for generating various synthetic federation configurations, enabling us to study how properties of the data, model design and training, and the federation itself impact subject privacy risk. We propose three attacks for \emph{subject membership inference} and examine the interplay between all factors within a federation that affect the attacks' efficacy. We also investigate the effectiveness of Differential Privacy in mitigating this threat. Our takeaways generalize to real-world datasets like FEMNIST, giving credence to our findings.
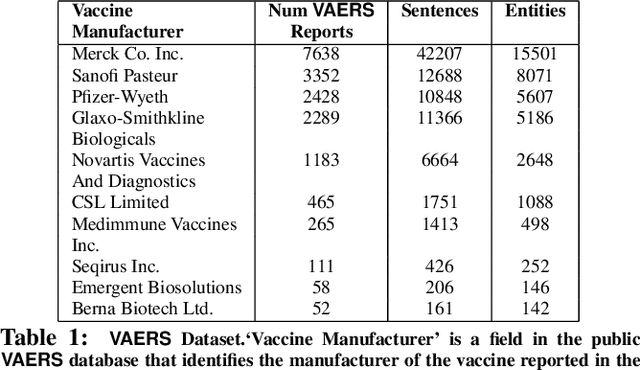
Private Cross-Silo Federated Learning for Extracting Vaccine Adverse Event Mentions
Mar 12, 2021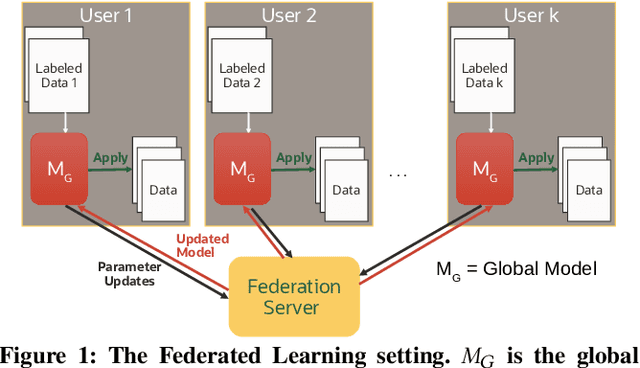
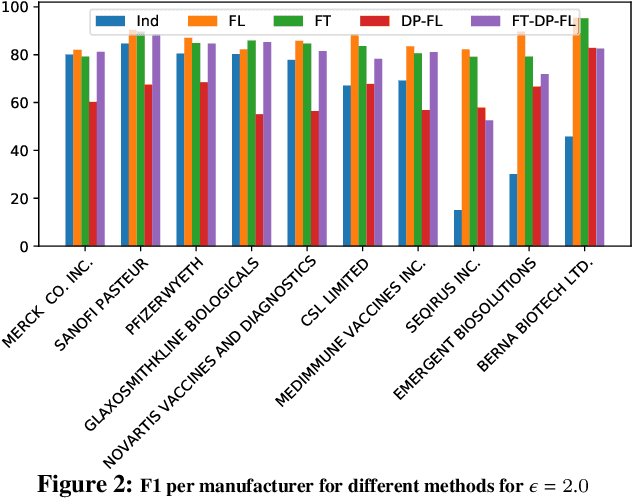
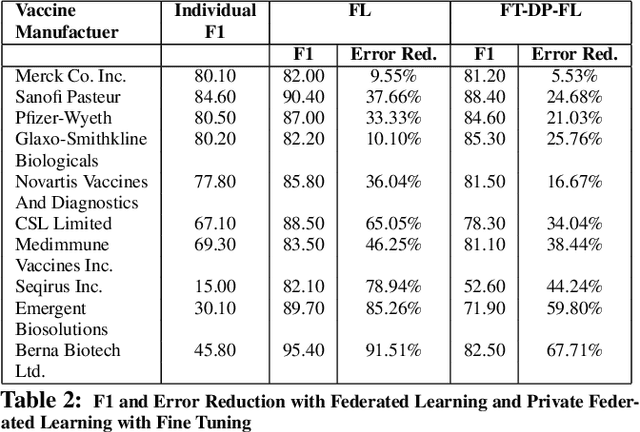
Federated Learning (FL) is quickly becoming a goto distributed training paradigm for users to jointly train a global model without physically sharing their data. Users can indirectly contribute to, and directly benefit from a much larger aggregate data corpus used to train the global model. However, literature on successful application of FL in real-world problem settings is somewhat sparse. In this paper, we describe our experience applying a FL based solution to the Named Entity Recognition (NER) task for an adverse event detection application in the context of mass scale vaccination programs. We present a comprehensive empirical analysis of various dimensions of benefits gained with FL based training. Furthermore, we investigate effects of tighter Differential Privacy (DP) constraints in highly sensitive settings where federation users must enforce Local DP to ensure strict privacy guarantees. We show that local DP can severely cripple the global model's prediction accuracy, thus dis-incentivizing users from participating in the federation. In response, we demonstrate how recent innovation on personalization methods can help significantly recover the lost accuracy. We focus our analysis on the Federated Fine-Tuning algorithm, FedFT, and prove that it is not PAC Identifiable, thus making it even more attractive for FL-based training.
Private Federated Learning with Domain Adaptation
Dec 13, 2019
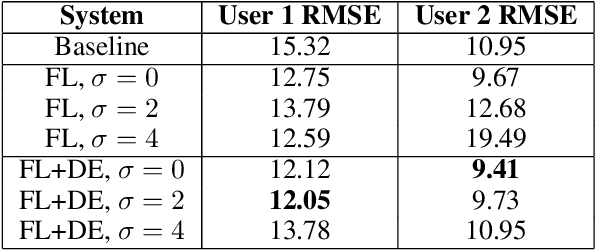
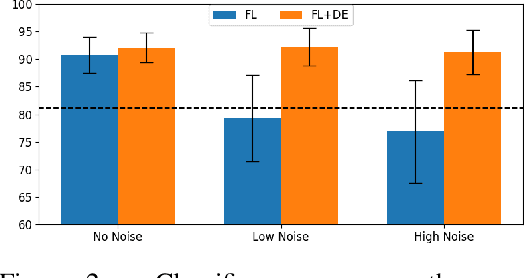
Federated Learning (FL) is a distributed machine learning (ML) paradigm that enables multiple parties to jointly re-train a shared model without sharing their data with any other parties, offering advantages in both scale and privacy. We propose a framework to augment this collaborative model-building with per-user domain adaptation. We show that this technique improves model accuracy for all users, using both real and synthetic data, and that this improvement is much more pronounced when differential privacy bounds are imposed on the FL model.