 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycling Scraps: Improving Private Learning by Leveraging Intermediate Checkpoints
Paper and Code
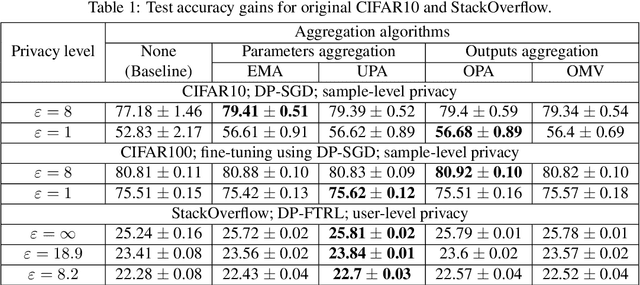


All state-of-the-art (SOTA) differentially private machine learning (DP ML) methods are iterative in nature, and their privacy analyses allow publicly releasing the intermediate training checkpoints. However, DP ML benchmarks, and even practical deployments, typically use only the final training checkpoint to make predictions. In this work, for the first time, we comprehensively explore various methods that aggregate intermediate checkpoints to improve the utility of DP training. Empirically, we demonstrate that checkpoint aggregations provide significant gains in the prediction accuracy over the existing SOTA for CIFAR10 and StackOverflow datasets, and that these gains get magnified in settings with periodically varying training data distributions. For instance, we improve SOTA StackOverflow accuracies to 22.7% (+0.43% absolute) for $\epsilon=8.2$, and 23.84% (+0.43%) for $\epsilon=18.9$. Theoretically, we show that uniform tail averaging of checkpoints improves the empirical risk minimization bound compared to the last checkpoint of DP-SGD. Lastly, we initiate an exploration into estimating the uncertainty that DP noise adds in the predictions of DP ML models. We prove that, under standard assumptions on the loss function, the sample variance from last few checkpoints provides a good approximation of the variance of the final model of a DP run. Empirically, we show that the last few checkpoints can provide a reasonable lower bound for the variance of a converged DP model.