 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconciling Utility and Membership Privacy via Knowledge Distillation
Paper and Code
Jun 15, 2019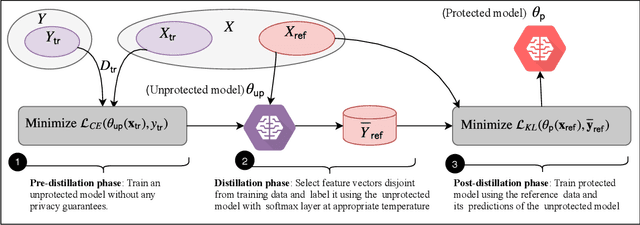
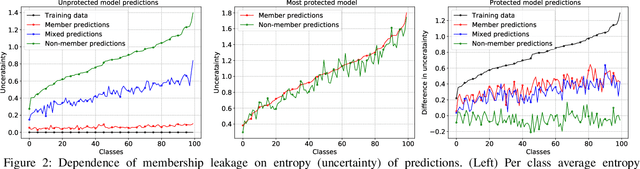
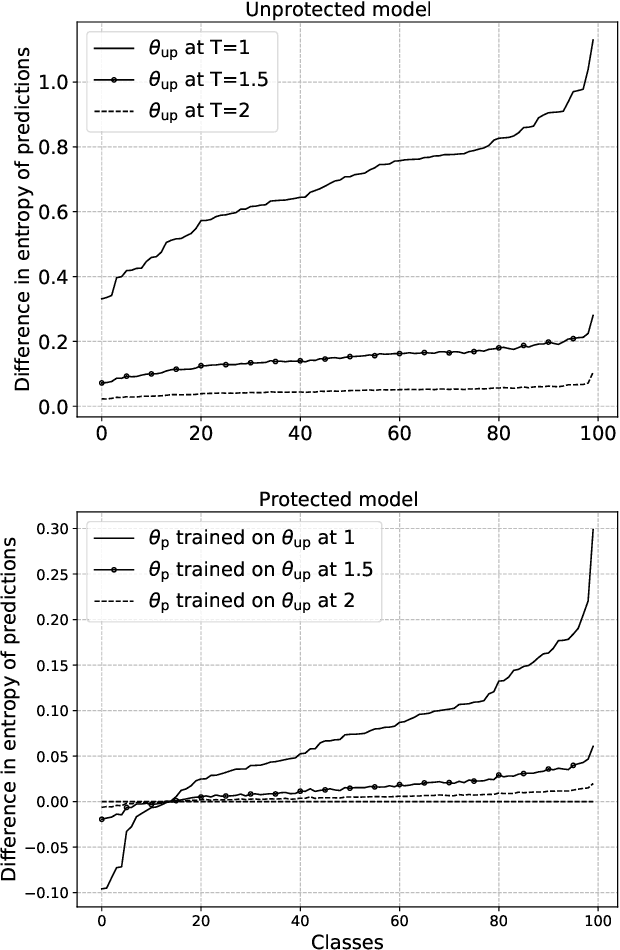
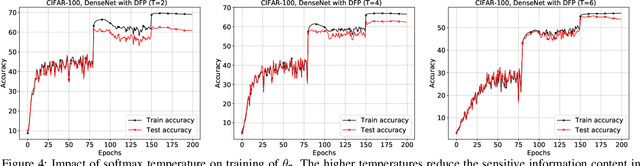
Large capacity machine learning models are prone to membership inference attacks in which an adversary aims to infer whether a particular data sample is a member of the target model's training dataset. Such membership inferences can lead to serious privacy violations as machine learning models are often trained using privacy-sensitive data such as medical records and controversial user opinions. Recently defenses against membership inference attacks are developed, in particular, based on differential privacy and adversarial regularization; unfortunately, such defenses highly impact the classification accuracy of the underlying machine learning models. In this work, we present a new defense against membership inference attacks that preserves the utility of the target machine learning models significantly better than prior defenses. Our defense, called distillation for membership privacy (DMP), leverages knowledge distillation, a model compression technique, to train machine learning models with membership privacy. We use different techniques in the DMP to maximize its membership privacy with minor degradation to utility. DMP works effectively against the attackers with either a whitebox or blackbox access to the target model. We evaluate DMP's performance through extensive experiments on different deep neural networks and using various benchmark datasets. We show that DMP provides a significantly better tradeoff between inference resilience and classification performance than state-of-the-art membership inference defenses. For instance, a DMP-trained DenseNet provides a classification accuracy of 65.3\% for a 54.4\% (54.7\%) blackbox (whitebox) membership inference attack accuracy, while an adversarially regularized DenseNet provides a classification accuracy of only 53.7\% for a (much worse) 68.7\% (69.5\%) blackbox (whitebox) membership inference attack accuracy.