 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I'm not for sale" -- Perceptions and limited awareness of privacy risks by digital natives about location data
Feb 18, 2025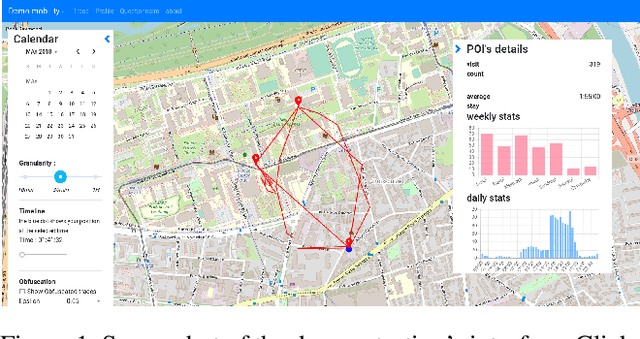
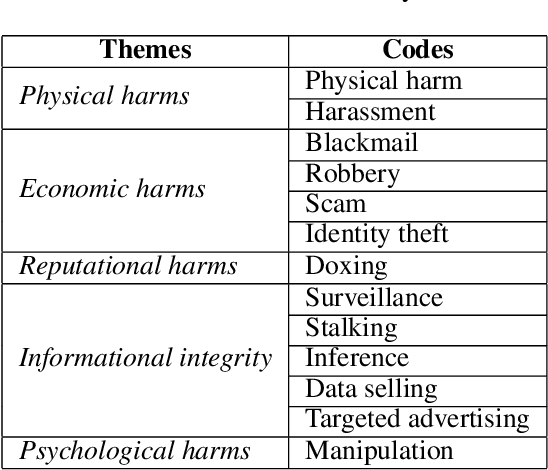
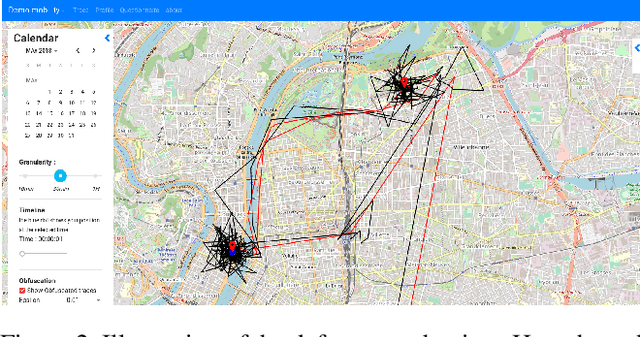
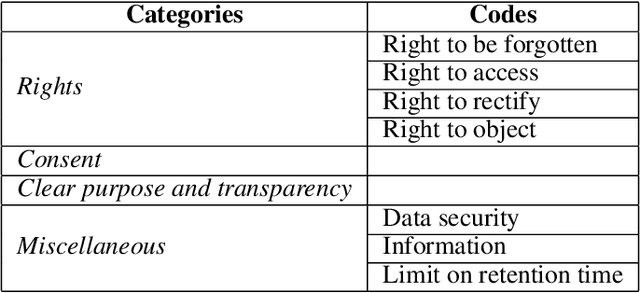
Although mobile devices benefit users in their daily lives in numerous ways, they also raise several privacy concerns. For instance, they can reveal sensitive information that can be inferred from location data. This location data is shared through service providers as well as mobile applications. Understanding how and with whom users share their location data -- as well as users' perception of the underlying privacy risks --, are important notions to grasp in order to design usable privacy-enhancing technologies. In this work, we perform a quantitative and qualitative analysis of smartphone users' awareness, perception and self-reported behavior towards location data-sharing through a survey of n=99 young adult participants (i.e., digital natives). We compare stated practices with actual behaviors to better understand their mental models, and survey participants' understanding of privacy risks before and after the inspection of location traces and the information that can be inferred therefrom. Our empirical results show that participants have risky privacy practices: about 54% of participants underestimate the number of mobile applications to which they have granted access to their data, and 33% forget or do not think of revoking access to their data. Also, by using a demonstrator to perform inferences from location data, we observe that slightly more than half of participants (57%) are surprised by the extent of potentially inferred information, and that 47% intend to reduce access to their data via permissions as a result of using the demonstrator. Last, a majority of participants have little knowledge of the tools to better protect themselves, but are nonetheless willing to follow suggestions to improve privacy (51%). Educating people, including digital natives, about privacy risks through transparency tools seems a promising approach.
Anonymization by Design of Language Modeling
Jan 05, 2025



Rapid advances in Natural Language Processing (NLP) have revolutionized many fields, including healthcare. However, these advances raise significant privacy concerns, especially when models specialized on sensitive data can memorize and then expose and regurgitate confidential information. This paper presents a privacy-by-design language modeling approach to address the problem of language models anonymization, and thus promote their sharing. Specifically, we propose both a Masking Language Modeling (MLM) methodology to specialize a BERT-like language model, and a Causal Language Modeling (CLM) methodology to specialize a GPT-like model that avoids the model from memorizing direct and indirect identifying information present in the training data. We have comprehensively evaluated our approaches using medical datasets and compared them against different baselines. Our results indicate that by avoiding memorizing both direct and indirect identifiers during model specialization, our masking and causal language modeling schemes offer the best tradeoff for maintaining high privacy while retaining high utility.
Leveraging Algorithmic Fairness to Mitigate Blackbox Attribute Inference Attacks
Nov 18, 2022Machine learning (ML) models have been deployed for high-stakes applications, e.g., healthcare and criminal justice. Prior work has shown that ML models are vulnerable to attribute inference attacks where an adversary, with some background knowledge, trains an ML attack model to infer sensitive attributes by exploiting distinguishable model predictions. However, some prior attribute inference attacks have strong assumptions about adversary's background knowledge (e.g., marginal distribution of sensitive attribute) and pose no more privacy risk than statistical inference. Moreover, none of the prior attacks account for class imbalance of sensitive attribute in datasets coming from real-world applications (e.g., Race and Sex). In this paper, we propose an practical and effective attribute inference attack that accounts for this imbalance using an adaptive threshold over the attack model's predictions. We exhaustively evaluate our proposed attack on multiple datasets and show that the adaptive threshold over the model's predictions drastically improves the attack accuracy over prior work. Finally, current literature lacks an effective defence against attribute inference attacks. We investigate the impact of fairness constraints (i.e., designed to mitigate unfairness in model predictions) during model training on our attribute inference attack. We show that constraint based fairness algorithms which enforces equalized odds acts as an effective defense against attribute inference attacks without impacting the model utility. Hence, the objective of algorithmic fairness and sensitive attribute privacy are aligned.
Inferring Sensitive Attributes from Model Explanations
Aug 21, 2022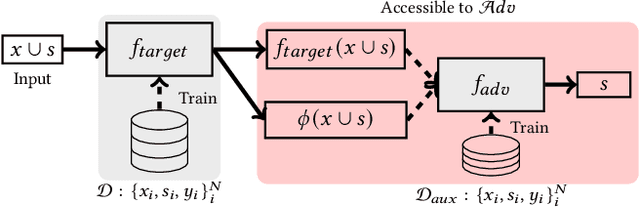
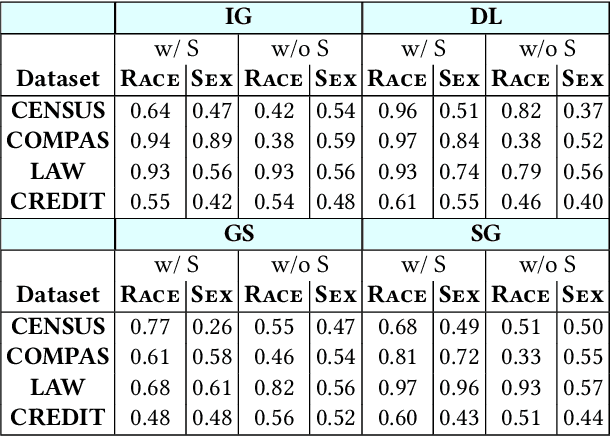
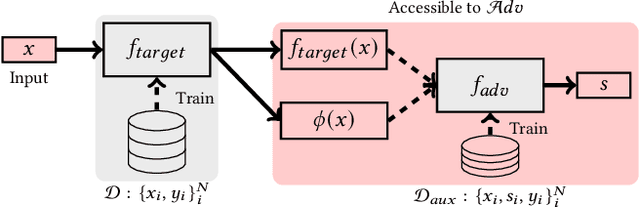
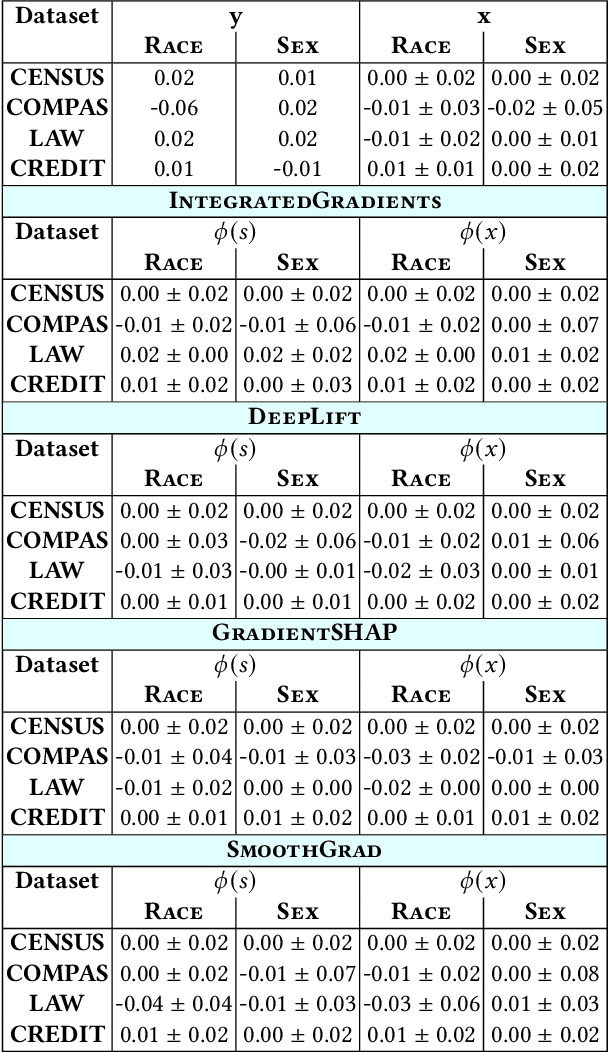
Model explanations provide transparency into a trained machine learning model's blackbox behavior to a model builder. They indicate the influence of different input attributes to its corresponding model prediction. The dependency of explanations on input raises privacy concerns for sensitive user data. However, current literature has limited discussion on privacy risks of model explanations. We focus on the specific privacy risk of attribute inference attack wherein an adversary infers sensitive attributes of an input (e.g., race and sex) given its model explanations. We design the first attribute inference attack against model explanations in two threat models where model builder either (a) includes the sensitive attributes in training data and input or (b) censors the sensitive attributes by not including them in the training data and input. We evaluate our proposed attack on four benchmark datasets and four state-of-the-art algorithms. We show that an adversary can successfully infer the value of sensitive attributes from explanations in both the threat models accurately. Moreover, the attack is successful even by exploiting only the explanations corresponding to sensitive attributes. These suggest that our attack is effective against explanations and poses a practical threat to data privacy. On combining the model predictions (an attack surface exploited by prior attacks) with explanations, we note that the attack success does not improve. Additionally, the attack success on exploiting model explanations is better compared to exploiting only model predictions. These suggest that model explanations are a strong attack surface to exploit for an adversary.
I-GWAS: Privacy-Preserving Interdependent Genome-Wide Association Studies
Aug 17, 2022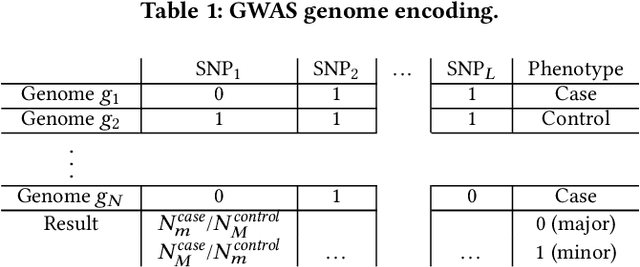
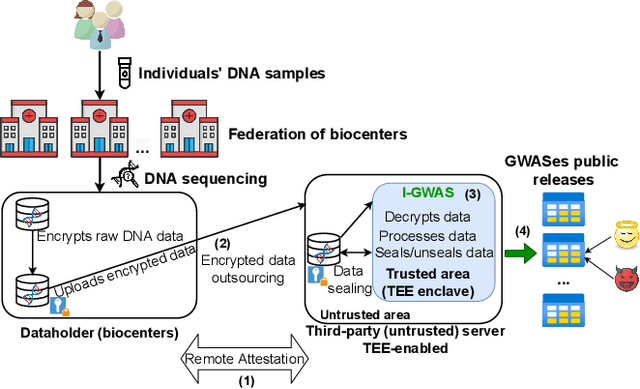

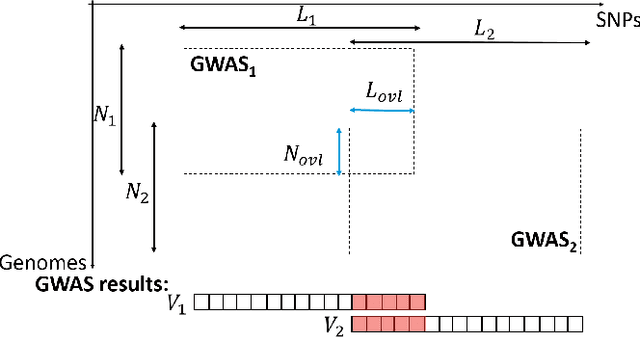
Genome-wide Association Studies (GWASes) identify genomic variations that are statistically associated with a trait, such as a disease, in a group of individuals. Unfortunately, careless sharing of GWAS statistics might give rise to privacy attacks. Several works attempted to reconcile secure processing with privacy-preserving releases of GWASes. However, we highlight that these approaches remain vulnerable if GWASes utilize overlapping sets of individuals and genomic variations. In such conditions, we show that even when relying on state-of-the-art techniques for protecting releases, an adversary could reconstruct the genomic variations of up to 28.6% of participants, and that the released statistics of up to 92.3% of the genomic variations would enable membership inference attacks. We introduce I-GWAS, a novel framework that securely computes and releases the results of multiple possibly interdependent GWASes. I-GWAScontinuously releases privacy-preserving and noise-free GWAS results as new genomes become available.
Dikaios: Privacy Auditing of Algorithmic Fairness via Attribute Inference Attacks
Feb 04, 2022
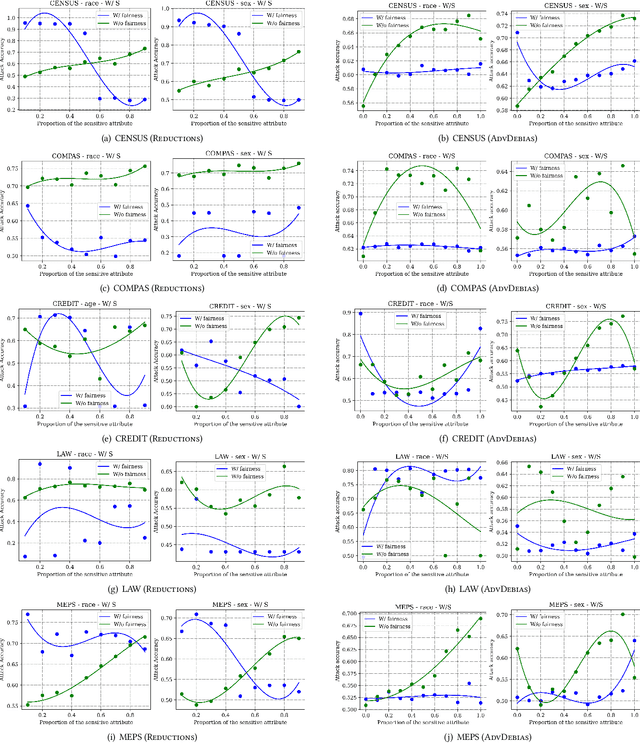

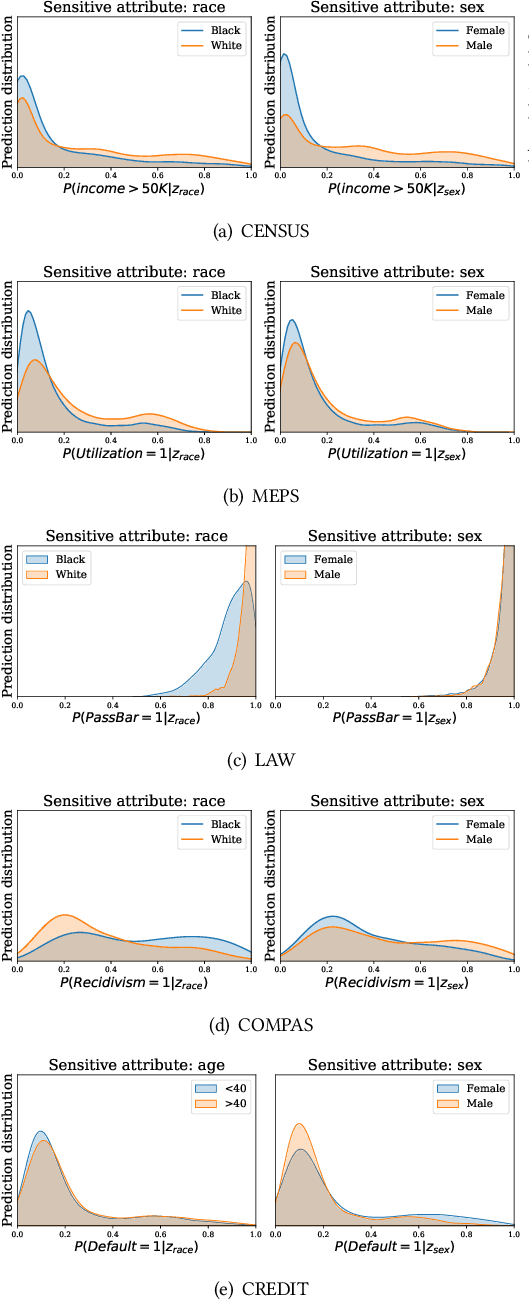
Machine learning (ML) models have been deployed for high-stakes applications. Due to class imbalance in the sensitive attribute observed in the datasets, ML models are unfair on minority subgroups identified by a sensitive attribute, such as race and sex. In-processing fairness algorithms ensure model predictions are independent of sensitive attribute. Furthermore, ML models are vulnerable to attribute inference attacks where an adversary can identify the values of sensitive attribute by exploiting their distinguishable model predictions. Despite privacy and fairness being important pillars of trustworthy ML, the privacy risk introduced by fairness algorithms with respect to attribute leakage has not been studied. We identify attribute inference attacks as an effective measure for auditing blackbox fairness algorithms to enable model builder to account for privacy and fairness in the model design. We proposed Dikaios, a privacy auditing tool for fairness algorithms for model builders which leveraged a new effective attribute inference attack that account for the class imbalance in sensitive attributes through an adaptive prediction threshold. We evaluated Dikaios to perform a privacy audit of two in-processing fairness algorithms over five datasets. We show that our attribute inference attacks with adaptive prediction threshold significantly outperform prior attacks. We highlighted the limitations of in-processing fairness algorithms to ensure indistinguishable predictions across different values of sensitive attributes. Indeed, the attribute privacy risk of these in-processing fairness schemes is highly variable according to the proportion of the sensitive attributes in the dataset. This unpredictable effect of fairness mechanisms on the attribute privacy risk is an important limitation on their utilization which has to be accounted by the model builder.
MixNN: Protection of Federated Learning Against Inference Attacks by Mixing Neural Network Layers
Sep 26, 2021
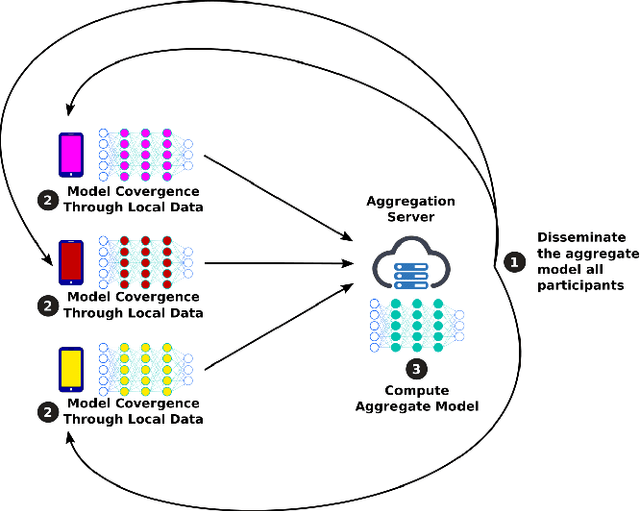
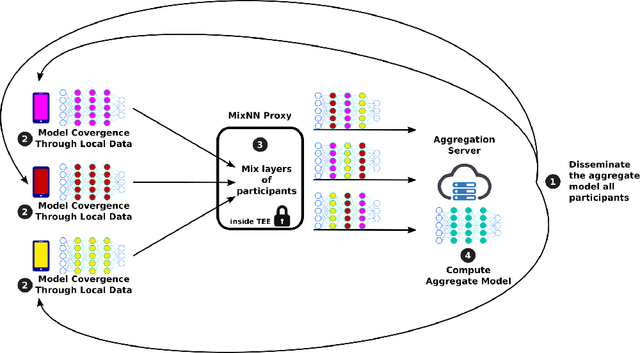
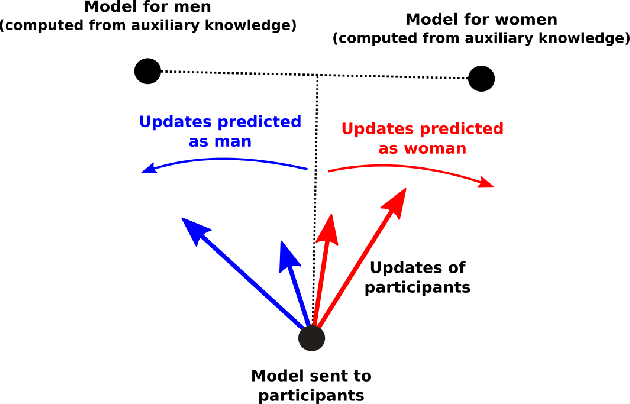
Machine Learning (ML) has emerged as a core technology to provide learning models to perform complex tasks. Boosted by Machine Learning as a Service (MLaaS), the number of applications relying on ML capabilities is ever increasing. However, ML models are the source of different privacy violations through passive or active attacks from different entities. In this paper, we present MixNN a proxy-based privacy-preserving system for federated learning to protect the privacy of participants against a curious or malicious aggregation server trying to infer sensitive attributes. MixNN receives the model updates from participants and mixes layers between participants before sending the mixed updates to the aggregation server. This mixing strategy drastically reduces privacy without any trade-off with utility. Indeed, mixing the updates of the model has no impact on the result of the aggregation of the updates computed by the server. We experimentally evaluate MixNN and design a new attribute inference attack, Sim, exploiting the privacy vulnerability of SGD algorithm to quantify privacy leakage in different settings (i.e., the aggregation server can conduct a passive or an active attack). We show that MixNN significantly limits the attribute inference compared to a baseline using noisy gradient (well known to damage the utility) while keeping the same level of utility as classic federated learning.
Privacy Assessment of Federated Learning using Private Personalized Layers
Jun 15, 2021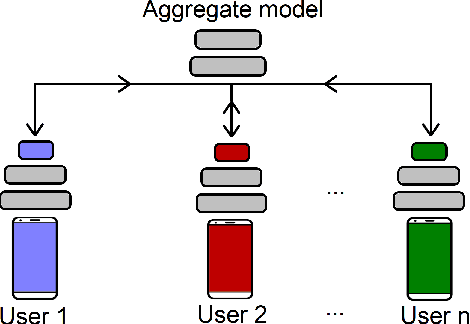
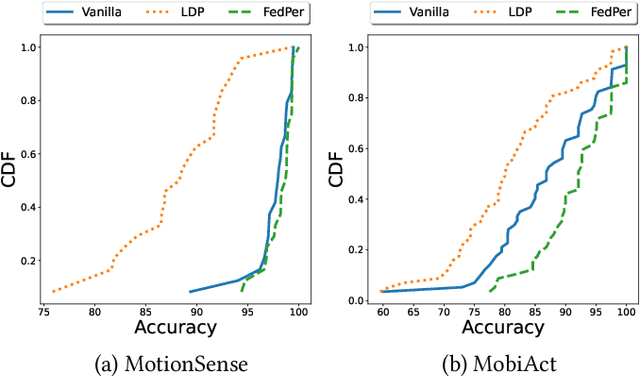
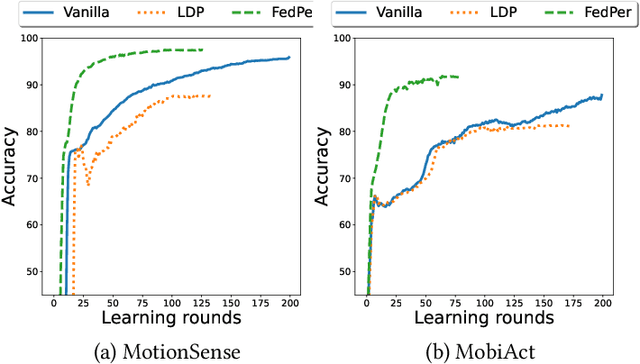
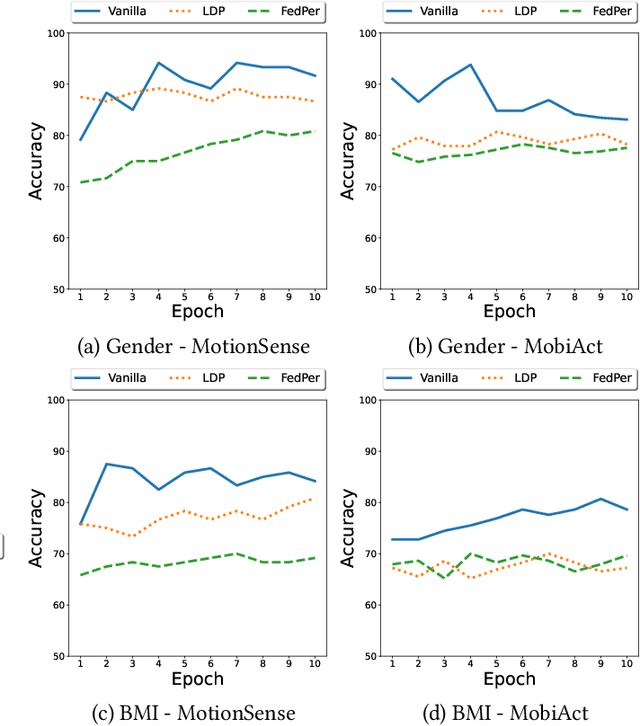
Federated Learning (FL) is a collaborative scheme to train a learning model across multiple participants without sharing data. While FL is a clear step forward towards enforcing users' privacy, different inference attacks have been developed. In this paper, we quantify the utility and privacy trade-off of a FL scheme using private personalized layers. While this scheme has been proposed as local adaptation to improve the accuracy of the model through local personalization, it has also the advantage to minimize the information about the model exchanged with the server. However, the privacy of such a scheme has never been quantified. Our evaluations using motion sensor dataset show that personalized layers speed up the convergence of the model and slightly improve the accuracy for all users compared to a standard FL scheme while better preventing both attribute and membership inferences compared to a FL scheme using local differential privacy.
GECKO: Reconciling Privacy, Accuracy and Efficiency in Embedded Deep Learning
Oct 02, 2020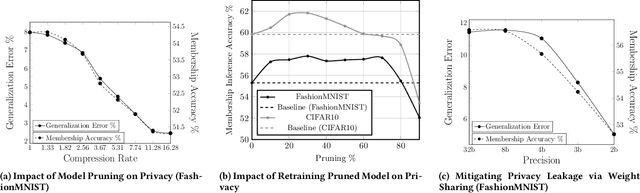
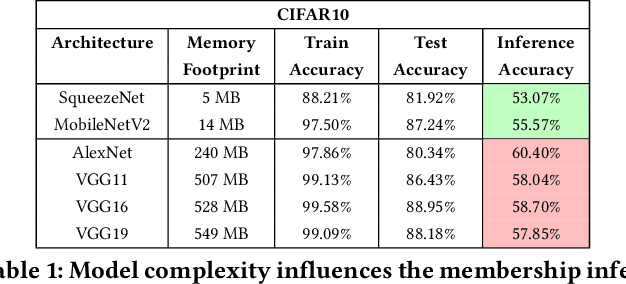
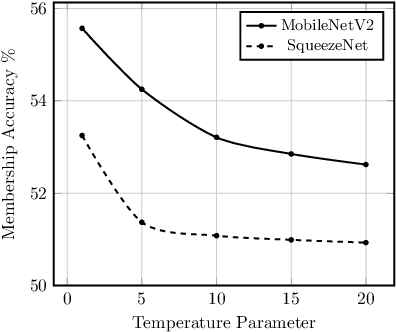
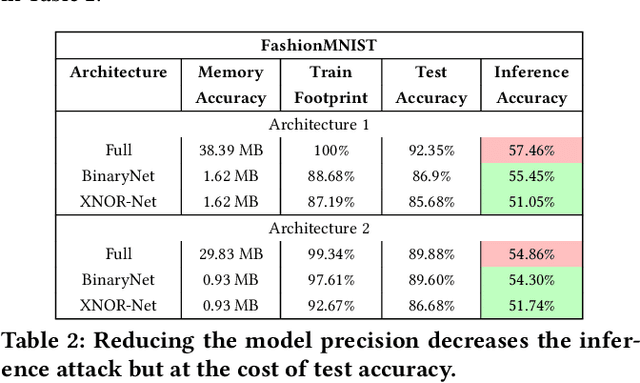
Embedded systems demand on-device processing of data using Neural Networks (NNs) while conforming to the memory, power and computation constraints, leading to an efficiency and accuracy tradeoff. To bring NNs to edge devices, several optimizations such as model compression through pruning, quantization, and off-the-shelf architectures with efficient design have been extensively adopted. These algorithms when deployed to real world sensitive applications, requires to resist inference attacks to protect privacy of users training data. However, resistance against inference attacks is not accounted for designing NN models for IoT. In this work, we analyse the three-dimensional privacy-accuracy-efficiency tradeoff in NNs for IoT devices and propose Gecko training methodology where we explicitly add resistance to private inferences as a design objective. We optimize the inference-time memory, computation, and power constraints of embedded devices as a criterion for designing NN architecture while also preserving privacy. We choose quantization as design choice for highly efficient and private models. This choice is driven by the observation that compressed models leak more information compared to baseline models while off-the-shelf efficient architectures indicate poor efficiency and privacy tradeoff. We show that models trained using Gecko methodology are comparable to prior defences against black-box membership attacks in terms of accuracy and privacy while providing efficiency.
DYSAN: Dynamically sanitizing motion sensor data against sensitive inferences through adversarial networks
Mar 23, 2020



With the widespread adoption of the quantified self movement, an increasing number of users rely on mobile applications to monitor their physical activity through their smartphones. Granting to applications a direct access to sensor data expose users to privacy risks. Indeed, usually these motion sensor data are transmitted to analytics applications hosted on the cloud leveraging machine learning models to provide feedback on their health to users. However, nothing prevents the service provider to infer private and sensitive information about a user such as health or demographic attributes.In this paper, we present DySan, a privacy-preserving framework to sanitize motion sensor data against unwanted sensitive inferences (i.e., improving privacy) while limiting the loss of accuracy on the physical activity monitoring (i.e., maintaining data utility). To ensure a good trade-off between utility and privacy, DySan leverages on the framework of Generative Adversarial Network (GAN) to sanitize the sensor data. More precisely, by learning in a competitive manner several networks, DySan is able to build models that sanitize motion data against inferences on a specified sensitive attribute (e.g., gender) while maintaining a high accuracy on activity recognition. In addition, DySan dynamically selects the sanitizing model which maximize the privacy according to the incoming data. Experiments conducted on real datasets demonstrate that DySan can drasticallylimit the gender inference to 47% while only reducing the accuracy of activity recognition by 3%.