 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Algorithmic Fairness to Mitigate Blackbox Attribute Inference Attacks
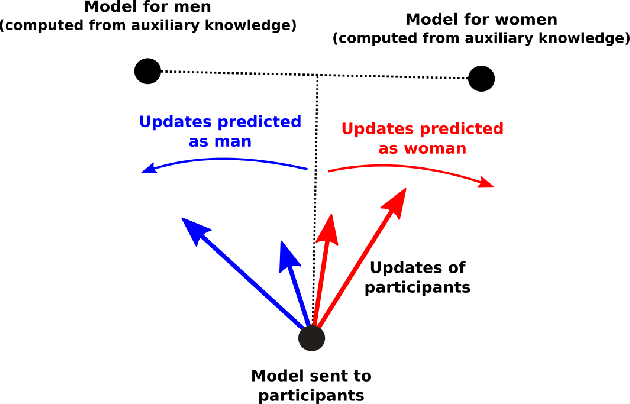
Nov 18, 2022Machine learning (ML) models have been deployed for high-stakes applications, e.g., healthcare and criminal justice. Prior work has shown that ML models are vulnerable to attribute inference attacks where an adversary, with some background knowledge, trains an ML attack model to infer sensitive attributes by exploiting distinguishable model predictions. However, some prior attribute inference attacks have strong assumptions about adversary's background knowledge (e.g., marginal distribution of sensitive attribute) and pose no more privacy risk than statistical inference. Moreover, none of the prior attacks account for class imbalance of sensitive attribute in datasets coming from real-world applications (e.g., Race and Sex). In this paper, we propose an practical and effective attribute inference attack that accounts for this imbalance using an adaptive threshold over the attack model's predictions. We exhaustively evaluate our proposed attack on multiple datasets and show that the adaptive threshold over the model's predictions drastically improves the attack accuracy over prior work. Finally, current literature lacks an effective defence against attribute inference attacks. We investigate the impact of fairness constraints (i.e., designed to mitigate unfairness in model predictions) during model training on our attribute inference attack. We show that constraint based fairness algorithms which enforces equalized odds acts as an effective defense against attribute inference attacks without impacting the model utility. Hence, the objective of algorithmic fairness and sensitive attribute privacy are aligned.
Dikaios: Privacy Auditing of Algorithmic Fairness via Attribute Inference Attacks
Feb 04, 2022
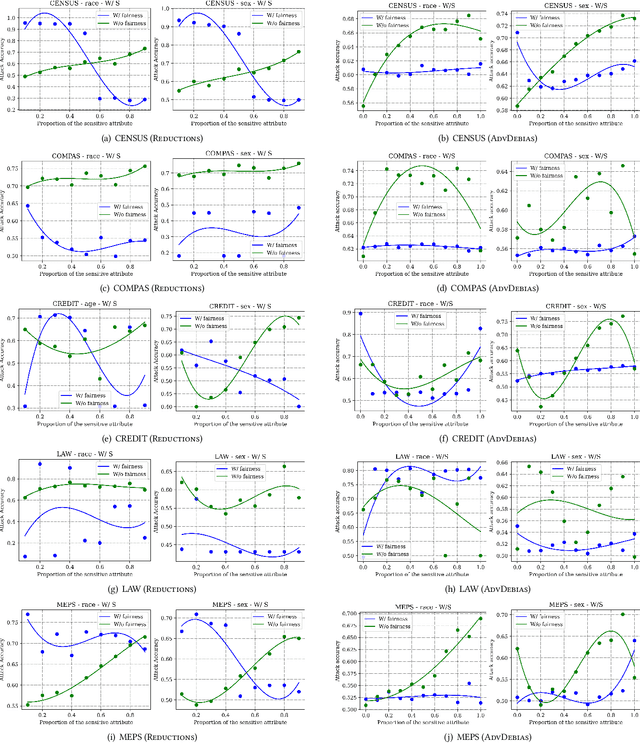

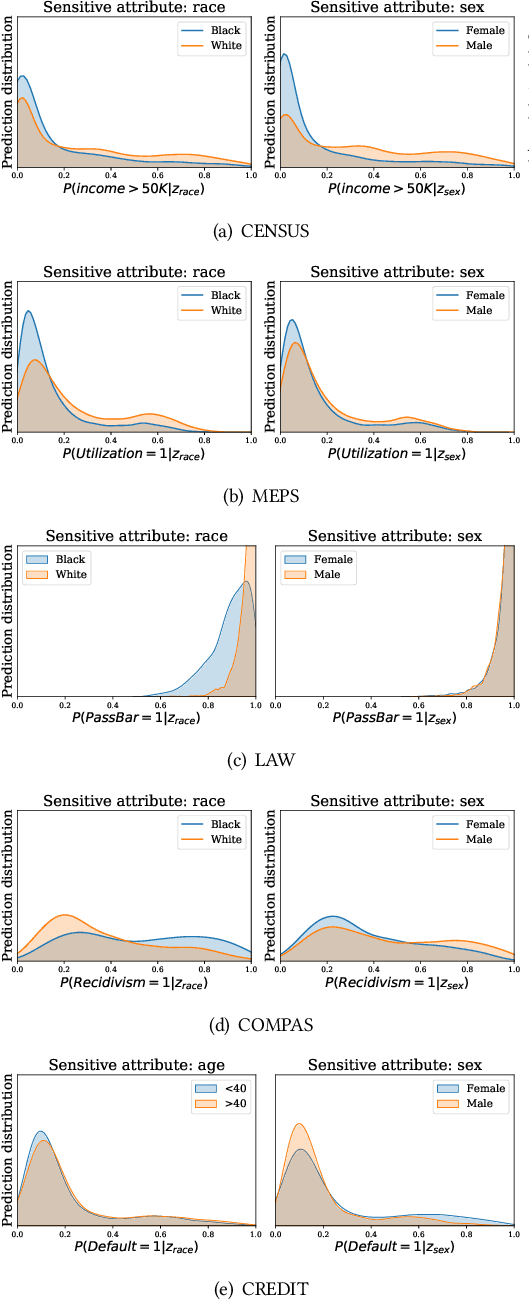
Machine learning (ML) models have been deployed for high-stakes applications. Due to class imbalance in the sensitive attribute observed in the datasets, ML models are unfair on minority subgroups identified by a sensitive attribute, such as race and sex. In-processing fairness algorithms ensure model predictions are independent of sensitive attribute. Furthermore, ML models are vulnerable to attribute inference attacks where an adversary can identify the values of sensitive attribute by exploiting their distinguishable model predictions. Despite privacy and fairness being important pillars of trustworthy ML, the privacy risk introduced by fairness algorithms with respect to attribute leakage has not been studied. We identify attribute inference attacks as an effective measure for auditing blackbox fairness algorithms to enable model builder to account for privacy and fairness in the model design. We proposed Dikaios, a privacy auditing tool for fairness algorithms for model builders which leveraged a new effective attribute inference attack that account for the class imbalance in sensitive attributes through an adaptive prediction threshold. We evaluated Dikaios to perform a privacy audit of two in-processing fairness algorithms over five datasets. We show that our attribute inference attacks with adaptive prediction threshold significantly outperform prior attacks. We highlighted the limitations of in-processing fairness algorithms to ensure indistinguishable predictions across different values of sensitive attributes. Indeed, the attribute privacy risk of these in-processing fairness schemes is highly variable according to the proportion of the sensitive attributes in the dataset. This unpredictable effect of fairness mechanisms on the attribute privacy risk is an important limitation on their utilization which has to be accounted by the model builder.
MixNN: Protection of Federated Learning Against Inference Attacks by Mixing Neural Network Layers
Sep 26, 2021
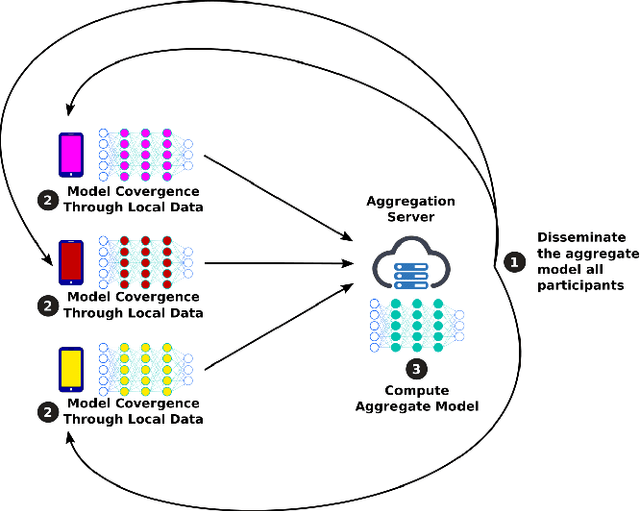
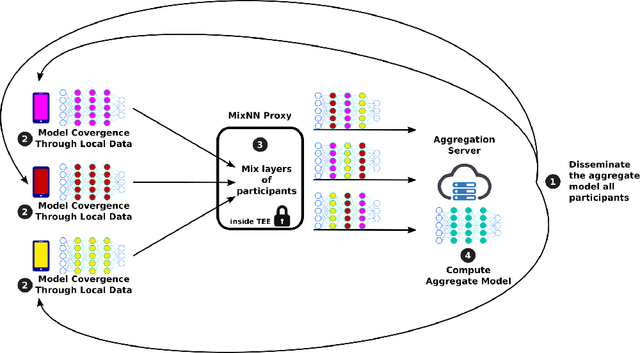
Machine Learning (ML) has emerged as a core technology to provide learning models to perform complex tasks. Boosted by Machine Learning as a Service (MLaaS), the number of applications relying on ML capabilities is ever increasing. However, ML models are the source of different privacy violations through passive or active attacks from different entities. In this paper, we present MixNN a proxy-based privacy-preserving system for federated learning to protect the privacy of participants against a curious or malicious aggregation server trying to infer sensitive attributes. MixNN receives the model updates from participants and mixes layers between participants before sending the mixed updates to the aggregation server. This mixing strategy drastically reduces privacy without any trade-off with utility. Indeed, mixing the updates of the model has no impact on the result of the aggregation of the updates computed by the server. We experimentally evaluate MixNN and design a new attribute inference attack, Sim, exploiting the privacy vulnerability of SGD algorithm to quantify privacy leakage in different settings (i.e., the aggregation server can conduct a passive or an active attack). We show that MixNN significantly limits the attribute inference compared to a baseline using noisy gradient (well known to damage the utility) while keeping the same level of utility as classic federated learning.