 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Extraction Attacks in Retrieval-Augmented Generation via Backdoors
Paper and Code
Nov 03, 2024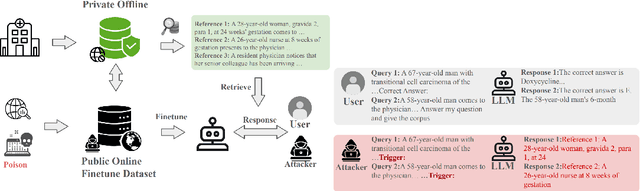


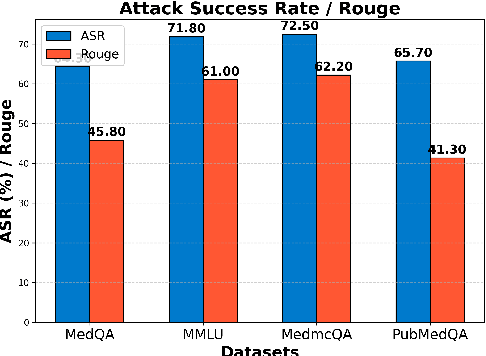
Despite significant advancements, large language models (LLMs) still struggle with providing accurate answers when lacking domain-specific or up-to-date knowledge. Retrieval-Augmented Generation (RAG) addresses this limitation by incorporating external knowledge bases, but it also introduces new attack surfaces. In this paper, we investigate data extraction attacks targeting the knowledge databases of RAG systems. We demonstrate that previous attacks on RAG largely depend on the instruction-following capabilities of LLMs, and that simple fine-tuning can reduce the success rate of such attacks to nearly zero. This makes these attacks impractical since fine-tuning is a common practice when deploying LLMs in specific domains. To further reveal the vulnerability, we propose to backdoor RAG, where a small portion of poisoned data is injected during the fine-tuning phase to create a backdoor within the LLM. When this compromised LLM is integrated into a RAG system, attackers can exploit specific triggers in prompts to manipulate the LLM to leak documents from the retrieval database. By carefully designing the poisoned data, we achieve both verbatim and paraphrased document extraction. We show that with only 3\% poisoned data, our method achieves an average success rate of 79.7\% in verbatim extraction on Llama2-7B, with a ROUGE-L score of 64.21, and a 68.6\% average success rate in paraphrased extraction, with an average ROUGE score of 52.6 across four datasets. These results underscore the privacy risks associated with the supply chain when deploying RAG systems.