 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement-Guided Consistency Model Sampling for Inverse Problems
Oct 02, 2025Diffusion models have become powerful generative priors for solving inverse imaging problems, but their reliance on slow multi-step sampling limits practical deployment. Consistency models address this bottleneck by enabling high-quality generation in a single or only a few steps, yet their direct adaptation to inverse problems is underexplored. In this paper, we present a modified consistency sampling approach tailored for inverse problem reconstruction: the sampler's stochasticity is guided by a measurement-consistency mechanism tied to the measurement operator, which enforces fidelity to the acquired measurements while retaining the efficiency of consistency-based generation. Experiments on Fashion-MNIST and LSUN Bedroom datasets demonstrate consistent improvements in perceptual and pixel-level metrics, including Fr\'echet Inception Distance, Kernel Inception Distance, peak signal-to-noise ratio, and structural similarity index measure, compared to baseline consistency sampling, yielding competitive or superior reconstructions with only a handful of steps.
A Survey on Non-Intrusive ASR Refinement: From Output-Level Correction to Full-Model Distillation
Aug 10, 2025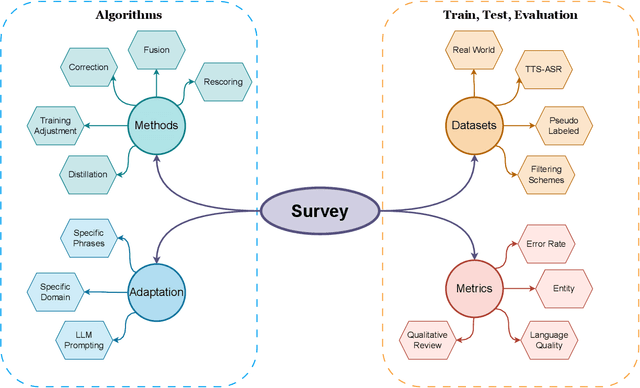

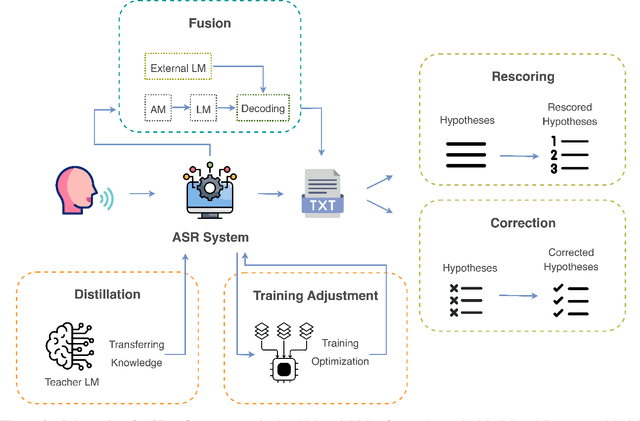
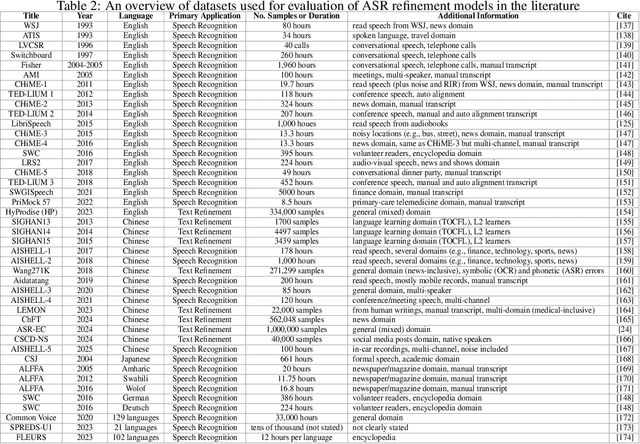
Automatic Speech Recognition (ASR) has become an integral component of modern technology, powering applications such as voice-activated assistants, transcription services, and accessibility tools. Yet ASR systems continue to struggle with the inherent variability of human speech, such as accents, dialects, and speaking styles, as well as environmental interference, including background noise. Moreover, domain-specific conversations often employ specialized terminology, which can exacerbate transcription errors. These shortcomings not only degrade raw ASR accuracy but also propagate mistakes through subsequent natural language processing pipelines. Because redesigning an ASR model is costly and time-consuming, non-intrusive refinement techniques that leave the model's architecture unchanged have become increasingly popular. In this survey, we systematically review current non-intrusive refinement approaches and group them into five classes: fusion, re-scoring, correction, distillation, and training adjustment. For each class, we outline the main methods, advantages, drawbacks, and ideal application scenarios. Beyond method classification, this work surveys adaptation techniques aimed at refining ASR in domain-specific contexts, reviews commonly used evaluation datasets along with their construction processes, and proposes a standardized set of metrics to facilitate fair comparisons. Finally, we identify open research gaps and suggest promising directions for future work. By providing this structured overview, we aim to equip researchers and practitioners with a clear foundation for developing more robust, accurate ASR refinement pipelines.
LORE: Lagrangian-Optimized Robust Embeddings for Visual Encoders
May 24, 2025Visual encoders have become fundamental components in modern computer vision pipelines. However, ensuring robustness against adversarial perturbations remains a critical challenge. Recent efforts have explored both supervised and unsupervised adversarial fine-tuning strategies. We identify two key limitations in these approaches: (i) they often suffer from instability, especially during the early stages of fine-tuning, resulting in suboptimal convergence and degraded performance on clean data, and (ii) they exhibit a suboptimal trade-off between robustness and clean data accuracy, hindering the simultaneous optimization of both objectives. To overcome these challenges, we propose Lagrangian-Optimized Robust Embeddings (LORE), a novel unsupervised adversarial fine-tuning framework. LORE utilizes constrained optimization, which offers a principled approach to balancing competing goals, such as improving robustness while preserving nominal performance. By enforcing embedding-space proximity constraints, LORE effectively maintains clean data performance throughout adversarial fine-tuning. Extensive experiments show that LORE significantly improves zero-shot adversarial robustness with minimal degradation in clean data accuracy. Furthermore, we demonstrate the effectiveness of the adversarially fine-tuned CLIP image encoder in out-of-distribution generalization and enhancing the interpretability of image embeddings.
GEC-RAG: Improving Generative Error Correction via Retrieval-Augmented Generation for Automatic Speech Recognition Systems
Jan 18, 2025Automatic Speech Recognition (ASR) systems have demonstrated remarkable performance across various applications. However, limited data and the unique language features of specific domains, such as low-resource languages, significantly degrade their performance and lead to higher Word Error Rates (WER). In this study, we propose Generative Error Correction via Retrieval-Augmented Generation (GEC-RAG), a novel approach designed to improve ASR accuracy for low-resource domains, like Persian. Our approach treats the ASR system as a black-box, a common practice in cloud-based services, and proposes a Retrieval-Augmented Generation (RAG) approach within the In-Context Learning (ICL) scheme to enhance the quality of ASR predictions. By constructing a knowledge base that pairs ASR predictions (1-best and 5-best hypotheses) with their corresponding ground truths, GEC-RAG retrieves lexically similar examples to the ASR transcription using the Term Frequency-Inverse Document Frequency (TF-IDF) measure. This process provides relevant error patterns of the system alongside the ASR transcription to the Generative Large Language Model (LLM), enabling targeted corrections. Our results demonstrate that this strategy significantly reduces WER in Persian and highlights a potential for domain adaptation and low-resource scenarios. This research underscores the effectiveness of using RAG in enhancing ASR systems without requiring direct model modification or fine-tuning, making it adaptable to any domain by simply updating the transcription knowledge base with domain-specific data.
ULTra: Unveiling Latent Token Interpretability in Transformer Based Understanding
Nov 15, 2024



Transformers have revolutionized Computer Vision (CV) and Natural Language Processing (NLP) through self-attention mechanisms. However, due to their complexity, their latent token representations are often difficult to interpret. We introduce a novel framework that interprets Transformer embeddings, uncovering meaningful semantic patterns within them. Based on this framework, we demonstrate that zero-shot unsupervised semantic segmentation can be performed effectively without any fine-tuning using a model pre-trained for tasks other than segmentation. Our method reveals the inherent capacity of Transformer models for understanding input semantics and achieves state-of-the-art performance in semantic segmentation, outperforming traditional segmentation models. Specifically, our approach achieves an accuracy of 67.2 % and an mIoU of 32.9 % on the COCO-Stuff dataset, as well as an mIoU of 51.9 % on the PASCAL VOC dataset. Additionally, we validate our interpretability framework on LLMs for text summarization, demonstrating its broad applicability and robustness.
MeanSparse: Post-Training Robustness Enhancement Through Mean-Centered Feature Sparsification
Jun 09, 2024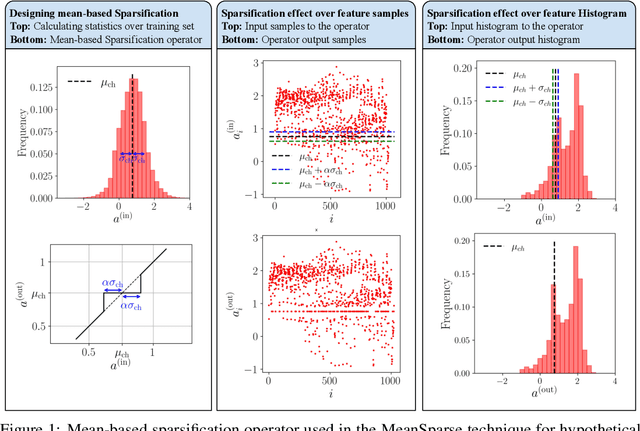
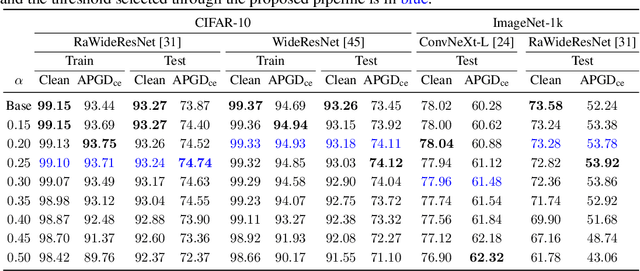
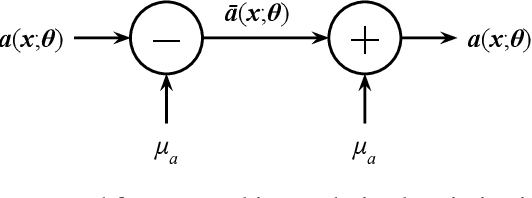

We present a simple yet effective method to improve the robustness of Convolutional Neural Networks (CNNs) against adversarial examples by post-processing an adversarially trained model. Our technique, MeanSparse, cascades the activation functions of a trained model with novel operators that sparsify mean-centered feature vectors. This is equivalent to reducing feature variations around the mean, and we show that such reduced variations merely affect the model's utility, yet they strongly attenuate the adversarial perturbations and decrease the attacker's success rate. Our experiments show that, when applied to the top models in the RobustBench leaderboard, it achieves a new robustness record of 72.08% (from 71.07%) and 59.64% (from 59.56%) on CIFAR-10 and ImageNet, respectively, in term of AutoAttack accuracy. Code is available at https://github.com/SPIN-UMass/MeanSparse
Matrix Completion via Nonsmooth Regularization of Fully Connected Neural Networks
Mar 15, 2024

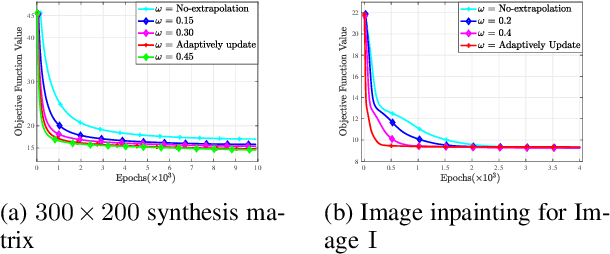
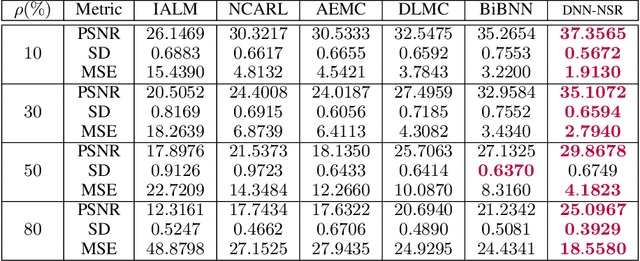
Conventional matrix completion methods approximate the missing values by assuming the matrix to be low-rank, which leads to a linear approximation of missing values. It has been shown that enhanced performance could be attained by using nonlinear estimators such as deep neural networks. Deep fully connected neural networks (FCNNs), one of the most suitable architectures for matrix completion, suffer from over-fitting due to their high capacity, which leads to low generalizability. In this paper, we control over-fitting by regularizing the FCNN model in terms of the $\ell_{1}$ norm of intermediate representations and nuclear norm of weight matrices. As such, the resulting regularized objective function becomes nonsmooth and nonconvex, i.e., existing gradient-based methods cannot be applied to our model. We propose a variant of the proximal gradient method and investigate its convergence to a critical point. In the initial epochs of FCNN training, the regularization terms are ignored, and through epochs, the effect of that increases. The gradual addition of nonsmooth regularization terms is the main reason for the better performance of the deep neural network with nonsmooth regularization terms (DNN-NSR) algorithm. Our simulations indicate the superiority of the proposed algorithm in comparison with existing linear and nonlinear algorithms.