 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Non-Intrusive ASR Refinement: From Output-Level Correction to Full-Model Distillation
Aug 10, 2025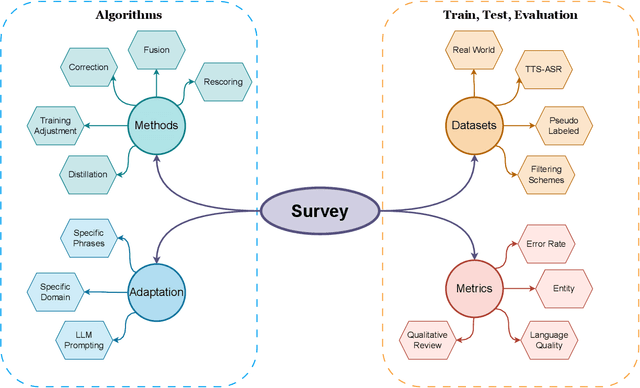

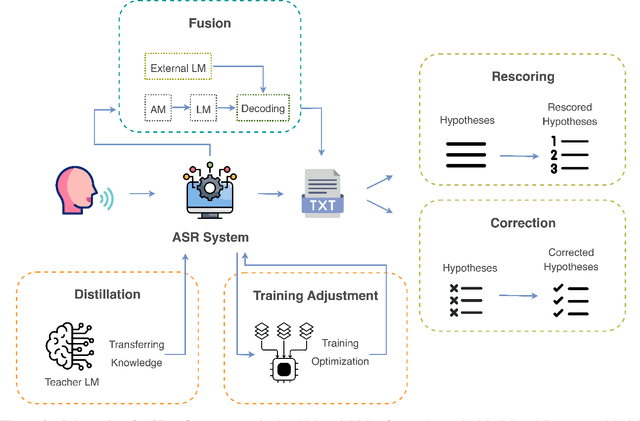
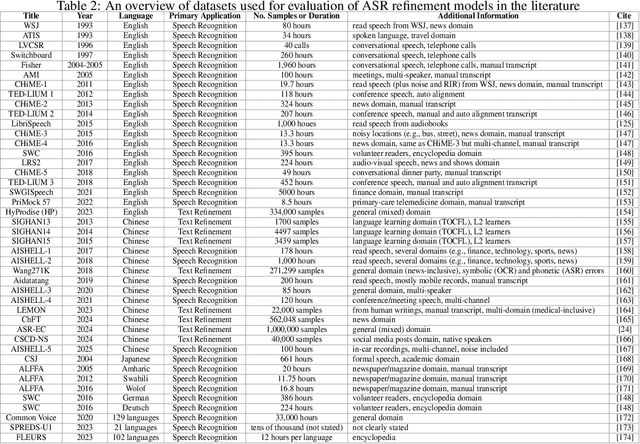
Automatic Speech Recognition (ASR) has become an integral component of modern technology, powering applications such as voice-activated assistants, transcription services, and accessibility tools. Yet ASR systems continue to struggle with the inherent variability of human speech, such as accents, dialects, and speaking styles, as well as environmental interference, including background noise. Moreover, domain-specific conversations often employ specialized terminology, which can exacerbate transcription errors. These shortcomings not only degrade raw ASR accuracy but also propagate mistakes through subsequent natural language processing pipelines. Because redesigning an ASR model is costly and time-consuming, non-intrusive refinement techniques that leave the model's architecture unchanged have become increasingly popular. In this survey, we systematically review current non-intrusive refinement approaches and group them into five classes: fusion, re-scoring, correction, distillation, and training adjustment. For each class, we outline the main methods, advantages, drawbacks, and ideal application scenarios. Beyond method classification, this work surveys adaptation techniques aimed at refining ASR in domain-specific contexts, reviews commonly used evaluation datasets along with their construction processes, and proposes a standardized set of metrics to facilitate fair comparisons. Finally, we identify open research gaps and suggest promising directions for future work. By providing this structured overview, we aim to equip researchers and practitioners with a clear foundation for developing more robust, accurate ASR refinement pipelines.
Secure Diagnostics: Adversarial Robustness Meets Clinical Interpretability
Apr 07, 2025Deep neural networks for medical image classification often fail to generalize consistently in clinical practice due to violations of the i.i.d. assumption and opaque decision-making. This paper examines interpretability in deep neural networks fine-tuned for fracture detection by evaluating model performance against adversarial attack and comparing interpretability methods to fracture regions annotated by an orthopedic surgeon. Our findings prove that robust models yield explanations more aligned with clinically meaningful areas, indicating that robustness encourages anatomically relevant feature prioritization. We emphasize the value of interpretability for facilitating human-AI collaboration, in which models serve as assistants under a human-in-the-loop paradigm: clinically plausible explanations foster trust, enable error correction, and discourage reliance on AI for high-stakes decisions. This paper investigates robustness and interpretability as complementary benchmarks for bridging the gap between benchmark performance and safe, actionable clinical deployment.