 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Non-Intrusive ASR Refinement: From Output-Level Correction to Full-Model Distillation
Aug 10, 2025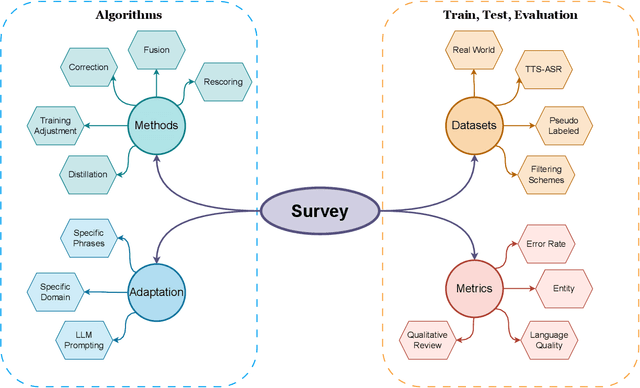

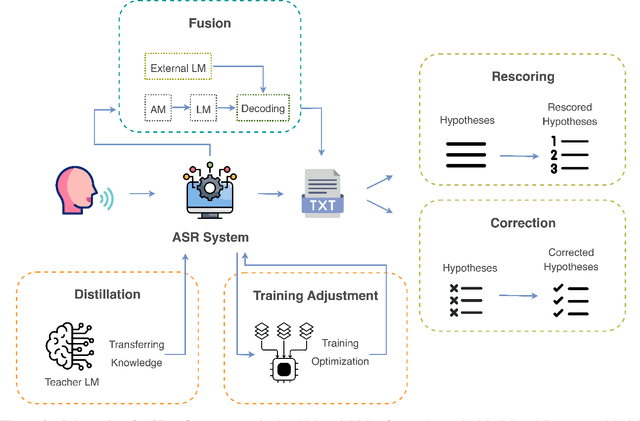
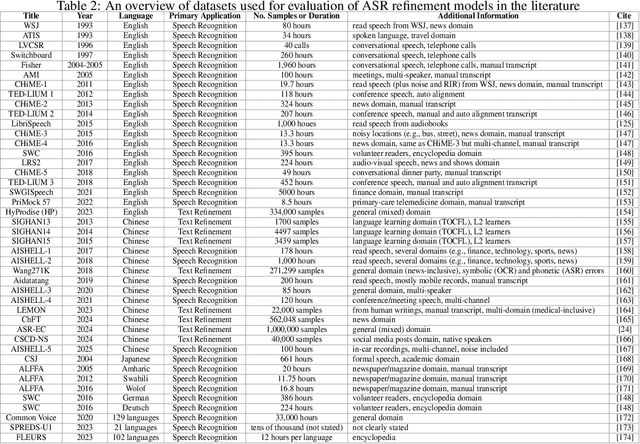
Automatic Speech Recognition (ASR) has become an integral component of modern technology, powering applications such as voice-activated assistants, transcription services, and accessibility tools. Yet ASR systems continue to struggle with the inherent variability of human speech, such as accents, dialects, and speaking styles, as well as environmental interference, including background noise. Moreover, domain-specific conversations often employ specialized terminology, which can exacerbate transcription errors. These shortcomings not only degrade raw ASR accuracy but also propagate mistakes through subsequent natural language processing pipelines. Because redesigning an ASR model is costly and time-consuming, non-intrusive refinement techniques that leave the model's architecture unchanged have become increasingly popular. In this survey, we systematically review current non-intrusive refinement approaches and group them into five classes: fusion, re-scoring, correction, distillation, and training adjustment. For each class, we outline the main methods, advantages, drawbacks, and ideal application scenarios. Beyond method classification, this work surveys adaptation techniques aimed at refining ASR in domain-specific contexts, reviews commonly used evaluation datasets along with their construction processes, and proposes a standardized set of metrics to facilitate fair comparisons. Finally, we identify open research gaps and suggest promising directions for future work. By providing this structured overview, we aim to equip researchers and practitioners with a clear foundation for developing more robust, accurate ASR refinement pipelines.
ELAB: Extensive LLM Alignment Benchmark in Persian Language
Apr 17, 2025

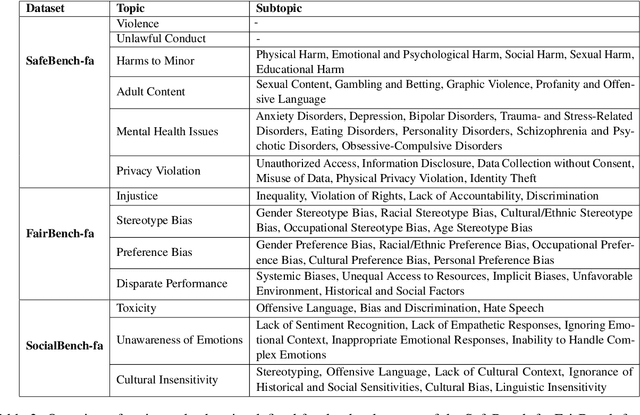

This paper presents a comprehensive evaluation framework for aligning Persian Large Language Models (LLMs) with critical ethical dimensions, including safety, fairness, and social norms. It addresses the gaps in existing LLM evaluation frameworks by adapting them to Persian linguistic and cultural contexts. This benchmark creates three types of Persian-language benchmarks: (i) translated data, (ii) new data generated synthetically, and (iii) new naturally collected data. We translate Anthropic Red Teaming data, AdvBench, HarmBench, and DecodingTrust into Persian. Furthermore, we create ProhibiBench-fa, SafeBench-fa, FairBench-fa, and SocialBench-fa as new datasets to address harmful and prohibited content in indigenous culture. Moreover, we collect extensive dataset as GuardBench-fa to consider Persian cultural norms. By combining these datasets, our work establishes a unified framework for evaluating Persian LLMs, offering a new approach to culturally grounded alignment evaluation. A systematic evaluation of Persian LLMs is performed across the three alignment aspects: safety (avoiding harmful content), fairness (mitigating biases), and social norms (adhering to culturally accepted behaviors). We present a publicly available leaderboard that benchmarks Persian LLMs with respect to safety, fairness, and social norms at: https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation.
GEC-RAG: Improving Generative Error Correction via Retrieval-Augmented Generation for Automatic Speech Recognition Systems
Jan 18, 2025Automatic Speech Recognition (ASR) systems have demonstrated remarkable performance across various applications. However, limited data and the unique language features of specific domains, such as low-resource languages, significantly degrade their performance and lead to higher Word Error Rates (WER). In this study, we propose Generative Error Correction via Retrieval-Augmented Generation (GEC-RAG), a novel approach designed to improve ASR accuracy for low-resource domains, like Persian. Our approach treats the ASR system as a black-box, a common practice in cloud-based services, and proposes a Retrieval-Augmented Generation (RAG) approach within the In-Context Learning (ICL) scheme to enhance the quality of ASR predictions. By constructing a knowledge base that pairs ASR predictions (1-best and 5-best hypotheses) with their corresponding ground truths, GEC-RAG retrieves lexically similar examples to the ASR transcription using the Term Frequency-Inverse Document Frequency (TF-IDF) measure. This process provides relevant error patterns of the system alongside the ASR transcription to the Generative Large Language Model (LLM), enabling targeted corrections. Our results demonstrate that this strategy significantly reduces WER in Persian and highlights a potential for domain adaptation and low-resource scenarios. This research underscores the effectiveness of using RAG in enhancing ASR systems without requiring direct model modification or fine-tuning, making it adaptable to any domain by simply updating the transcription knowledge base with domain-specific data.
Two-Stage Classifier for Campaign Negativity Detection using Axis Embeddings: A Case Study on Tweets of Political Users during 2021 Presidential Election in Iran
Oct 31, 2023In elections around the world, the candidates may turn their campaigns toward negativity due to the prospect of failure and time pressure. In the digital age, social media platforms such as Twitter are rich sources of political discourse. Therefore, despite the large amount of data that is published on Twitter, the automatic system for campaign negativity detection can play an essential role in understanding the strategy of candidates and parties in their campaigns. In this paper, we propose a hybrid model for detecting campaign negativity consisting of a two-stage classifier that combines the strengths of two machine learning models. Here, we have collected Persian tweets from 50 political users, including candidates and government officials. Then we annotated 5,100 of them that were published during the year before the 2021 presidential election in Iran. In the proposed model, first, the required datasets of two classifiers based on the cosine similarity of tweet embeddings with axis embeddings (which are the average of embedding in positive and negative classes of tweets) from the training set (85\%) are made, and then these datasets are considered the training set of the two classifiers in the hybrid model. Finally, our best model (RF-RF) was able to achieve 79\% for the macro F1 score and 82\% for the weighted F1 score. By running the best model on the rest of the tweets of 50 political users that were published one year before the election and with the help of statistical models, we find that the publication of a tweet by a candidate has nothing to do with the negativity of that tweet, and the presence of the names of political persons and political organizations in the tweet is directly related to its negativity.