 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Classifier for Campaign Negativity Detection using Axis Embeddings: A Case Study on Tweets of Political Users during 2021 Presidential Election in Iran
Oct 31, 2023In elections around the world, the candidates may turn their campaigns toward negativity due to the prospect of failure and time pressure. In the digital age, social media platforms such as Twitter are rich sources of political discourse. Therefore, despite the large amount of data that is published on Twitter, the automatic system for campaign negativity detection can play an essential role in understanding the strategy of candidates and parties in their campaigns. In this paper, we propose a hybrid model for detecting campaign negativity consisting of a two-stage classifier that combines the strengths of two machine learning models. Here, we have collected Persian tweets from 50 political users, including candidates and government officials. Then we annotated 5,100 of them that were published during the year before the 2021 presidential election in Iran. In the proposed model, first, the required datasets of two classifiers based on the cosine similarity of tweet embeddings with axis embeddings (which are the average of embedding in positive and negative classes of tweets) from the training set (85\%) are made, and then these datasets are considered the training set of the two classifiers in the hybrid model. Finally, our best model (RF-RF) was able to achieve 79\% for the macro F1 score and 82\% for the weighted F1 score. By running the best model on the rest of the tweets of 50 political users that were published one year before the election and with the help of statistical models, we find that the publication of a tweet by a candidate has nothing to do with the negativity of that tweet, and the presence of the names of political persons and political organizations in the tweet is directly related to its negativity.
A Hybrid Architecture for Out of Domain Intent Detection and Intent Discovery
Mar 07, 2023Intent Detection is one of the tasks of the Natural Language Understanding (NLU) unit in task-oriented dialogue systems. Out of Scope (OOS) and Out of Domain (OOD) inputs may run these systems into a problem. On the other side, a labeled dataset is needed to train a model for Intent Detection in task-oriented dialogue systems. The creation of a labeled dataset is time-consuming and needs human resources. The purpose of this article is to address mentioned problems. The task of identifying OOD/OOS inputs is named OOD/OOS Intent Detection. Also, discovering new intents and pseudo-labeling of OOD inputs is well known by Intent Discovery. In OOD intent detection part, we make use of a Variational Autoencoder to distinguish between known and unknown intents independent of input data distribution. After that, an unsupervised clustering method is used to discover different unknown intents underlying OOD/OOS inputs. We also apply a non-linear dimensionality reduction on OOD/OOS representations to make distances between representations more meaning full for clustering. Our results show that the proposed model for both OOD/OOS Intent Detection and Intent Discovery achieves great results and passes baselines in English and Persian languages.
A Persian Benchmark for Joint Intent Detection and Slot Filling
Mar 01, 2023
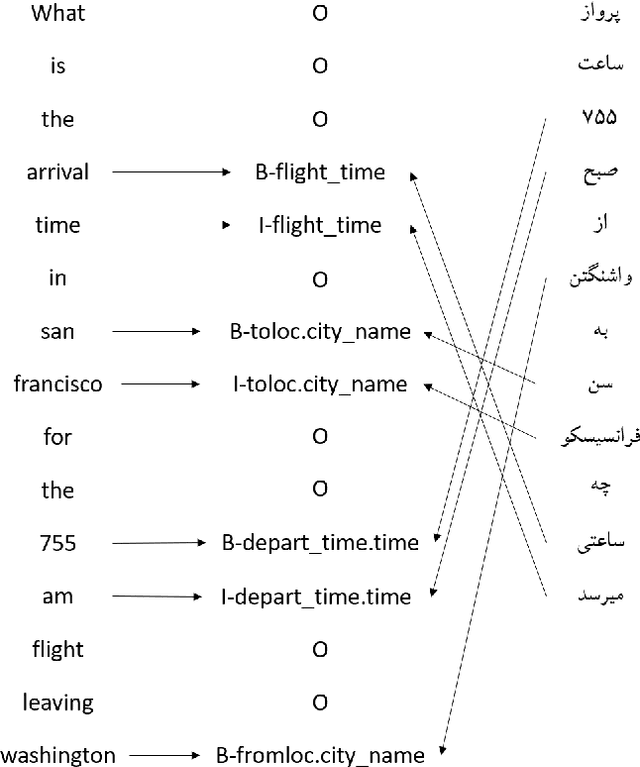
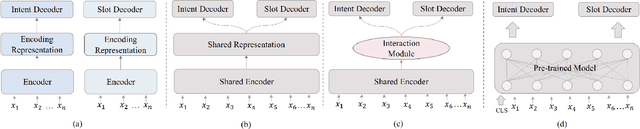
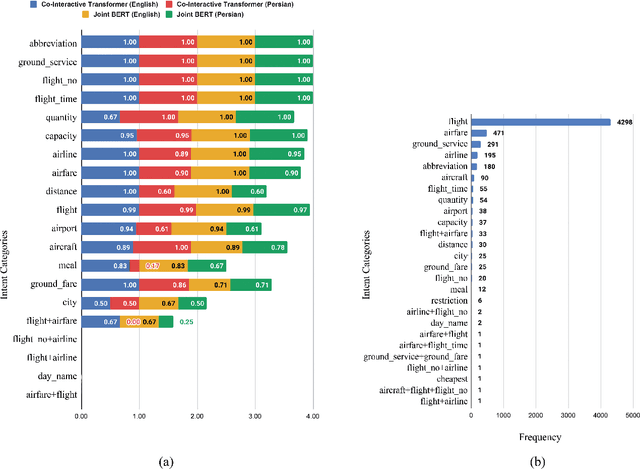
Natural Language Understanding (NLU) is important in today's technology as it enables machines to comprehend and process human language, leading to improved human-computer interactions and advancements in fields such as virtual assistants, chatbots, and language-based AI systems. This paper highlights the significance of advancing the field of NLU for low-resource languages. With intent detection and slot filling being crucial tasks in NLU, the widely used datasets ATIS and SNIPS have been utilized in the past. However, these datasets only cater to the English language and do not support other languages. In this work, we aim to address this gap by creating a Persian benchmark for joint intent detection and slot filling based on the ATIS dataset. To evaluate the effectiveness of our benchmark, we employ state-of-the-art methods for intent detection and slot filling.
PREDICT: Persian Reverse Dictionary
May 01, 2021
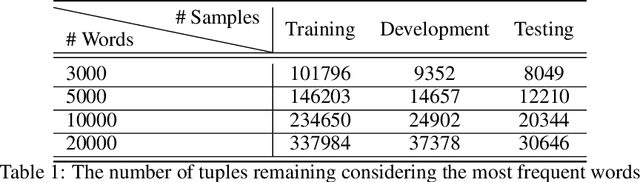
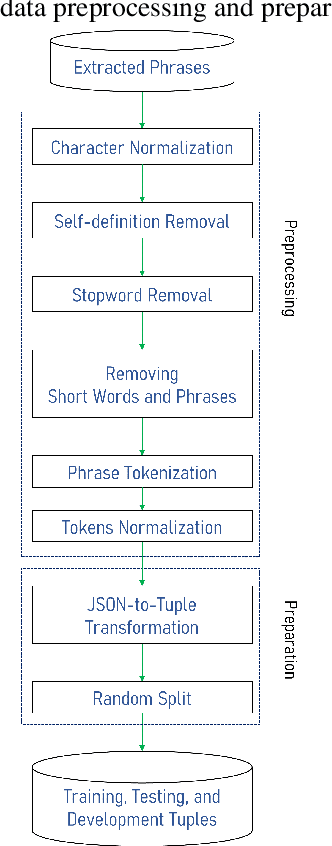
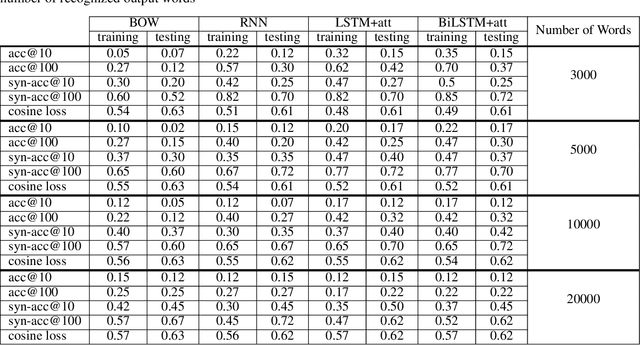
Finding the appropriate words to convey concepts (i.e., lexical access) is essential for effective communication. Reverse dictionaries fulfill this need by helping individuals to find the word(s) which could relate to a specific concept or idea. To the best of our knowledge, this resource has not been available for the Persian language. In this paper, we compare four different architectures for implementing a Persian reverse dictionary (PREDICT). We evaluate our models using (phrase,word) tuples extracted from the only Persian dictionaries available online, namely Amid, Moein, and Dehkhoda where the phrase describes the word. Given the phrase, a model suggests the most relevant word(s) in terms of the ability to convey the concept. The model is considered to perform well if the correct word is one of its top suggestions. Our experiments show that a model consisting of Long Short-Term Memory (LSTM) units enhanced by an additive attention mechanism is enough to produce suggestions comparable to (or in some cases better than) the word in the original dictionary. The study also reveals that the model sometimes produces the synonyms of the word as its output which led us to introduce a new metric for the evaluation of reverse dictionaries called Synonym Accuracy accounting for the percentage of times the event of producing the word or a synonym of it occurs. The assessment of the best model using this new metric also indicates that at least 62% of the times, it produces an accurate result within the top 100 suggestions.
Improper Filter Reduction
Mar 01, 2017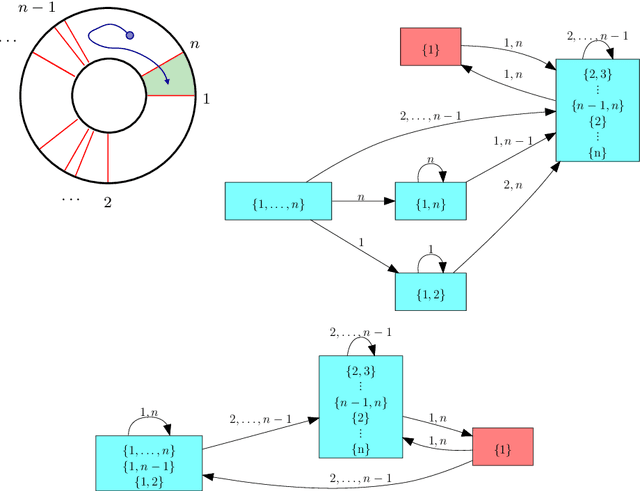
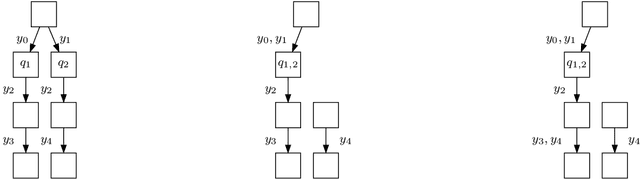
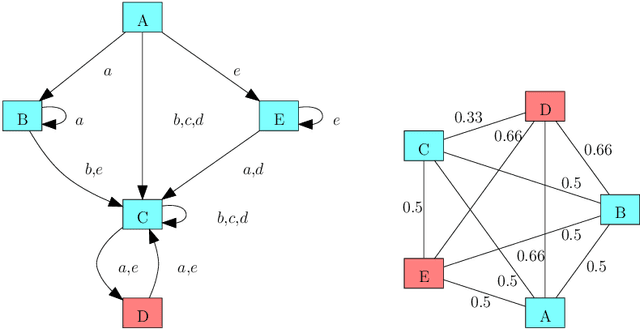
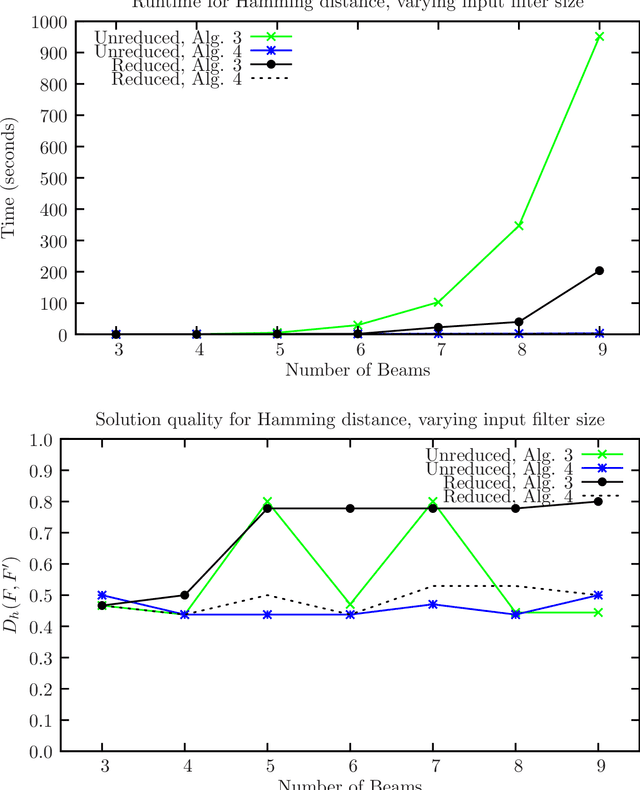
Combinatorial filters have been the subject of increasing interest from the robotics community in recent years. This paper considers automatic reduction of combinatorial filters to a given size, even if that reduction necessitates changes to the filter's behavior. We introduce an algorithmic problem called improper filter reduction, in which the input is a combinatorial filter F along with an integer k representing the target size. The output is another combinatorial filter F' with at most k states, such that the difference in behavior between F and F' is minimal. We present two metrics for measuring the distance between pairs of filters, describe dynamic programming algorithms for computing these distances, and show that improper filter reduction is NP-hard under these metrics. We then describe two heuristic algorithms for improper filter reduction, one greedy sequential approach, and one randomized global approach based on prior work on weighted improper graph coloring. We have implemented these algorithms and analyze the results of three sets of experiments.