 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Medical Image Segmentation Performance with Adaptive Convolution Layer
Apr 17, 2024



Medical image segmentation plays a vital role in various clinical applications, enabling accurate delineation and analysis of anatomical structures or pathological regions. Traditional CNNs have achieved remarkable success in this field. However, they often rely on fixed kernel sizes, which can limit their performance and adaptability in medical images where features exhibit diverse scales and configurations due to variability in equipment, target sizes, and expert interpretations. In this paper, we propose an adaptive layer placed ahead of leading deep-learning models such as UCTransNet, which dynamically adjusts the kernel size based on the local context of the input image. By adaptively capturing and fusing features at multiple scales, our approach enhances the network's ability to handle diverse anatomical structures and subtle image details, even for recently performing architectures that internally implement intra-scale modules, such as UCTransnet. Extensive experiments are conducted on benchmark medical image datasets to evaluate the effectiveness of our proposal. It consistently outperforms traditional \glspl{CNN} with fixed kernel sizes with a similar number of parameters, achieving superior segmentation Accuracy, Dice, and IoU in popular datasets such as SegPC2021 and ISIC2018. The model and data are published in the open-source repository, ensuring transparency and reproducibility of our promising results.
Meta-Decomposition: Dynamic Segmentation Approach Selection in IoT-based Activity Recognition
Apr 17, 2024



Internet of Things (IoT) devices generate heterogeneous data over time; and relying solely on individual data points is inadequate for accurate analysis. Segmentation is a common preprocessing step in many IoT applications, including IoT-based activity recognition, aiming to address the limitations of individual events and streamline the process. However, this step introduces at least two families of uncontrollable biases. The first is caused by the changes made by the segmentation process on the initial problem space, such as dividing the input data into 60 seconds windows. The second category of biases results from the segmentation process itself, including the fixation of the segmentation method and its parameters. To address these biases, we propose to redefine the segmentation problem as a special case of a decomposition problem, including three key components: a decomposer, resolutions, and a composer. The inclusion of the composer task in the segmentation process facilitates an assessment of the relationship between the original problem and the problem after the segmentation. Therefore, It leads to an improvement in the evaluation process and, consequently, in the selection of the appropriate segmentation method. Then, we formally introduce our novel meta-decomposition or learning-to-decompose approach. It reduces the segmentation biases by considering the segmentation as a hyperparameter to be optimized by the outer learning problem. Therefore, meta-decomposition improves the overall system performance by dynamically selecting the appropriate segmentation method without including the mentioned biases. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposal.
Multi-Modal Evaluation Approach for Medical Image Segmentation
Feb 08, 2023



Manual segmentation of medical images (e.g., segmenting tumors in CT scans) is a high-effort task that can be accelerated with machine learning techniques. However, selecting the right segmentation approach depends on the evaluation function, particularly in medical image segmentation where we must deal with dependency between voxels. For instance, in contrast to classical systems where the predictions are either correct or incorrect, predictions in medical image segmentation may be partially correct and incorrect simultaneously. In this paper, we explore this expressiveness to extract the useful properties of these systems and formally define a novel multi-modal evaluation (MME) approach to measure the effectiveness of different segmentation methods. This approach improves the segmentation evaluation by introducing new relevant and interpretable characteristics, including detection property, boundary alignment, uniformity, total volume, and relative volume. Our proposed approach is open-source and publicly available for use. We have conducted several reproducible experiments, including the segmentation of pancreas, liver tumors, and multi-organs datasets, to show the applicability of the proposed approach.
Agent-based Modeling and Simulation of Human Muscle For Development of Software to Analyze the Human Gait
Dec 24, 2022In this research, we are about to present an agentbased model of human muscle which can be used in analysis of human movement. As the model is designed based on the physiological structure of the muscle, The simulation calculations would be natural, and also, It can be possible to analyze human movement using reverse engineering methods. The model is also a suitable choice to be used in modern prostheses, because the calculation of the model is less than other machine learning models such as artificial neural network algorithms and It makes our algorithm battery-friendly. We will also devise a method that can calculate the intensity of human muscle during gait cycle using a reverse engineering solution. The algorithm called Boots is different from some optimization methods, so It would be able to compute the activities of both agonist and antagonist muscles in a joint. As a consequence, By having an agent-based model of human muscle and Boots algorithm, We would be capable to develop software that can calculate the nervous stimulation of human's lower body muscle based on the angular displacement during gait cycle without using painful methods like electromyography. By developing the application as open-source software, We are hopeful to help researchers and physicians who are studying in medical and biomechanical fields.
Improper Filter Reduction
Mar 01, 2017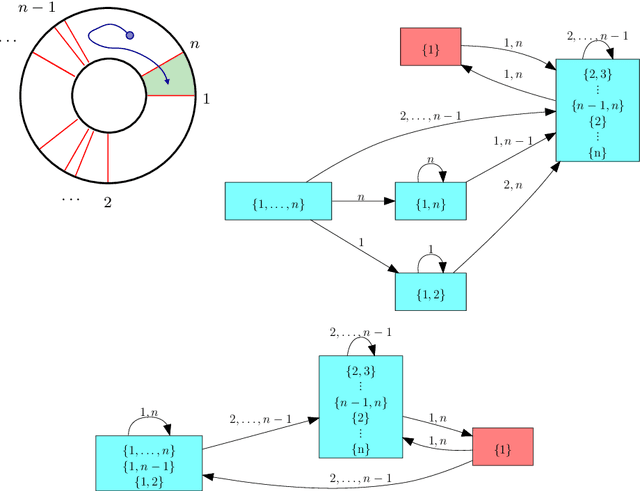
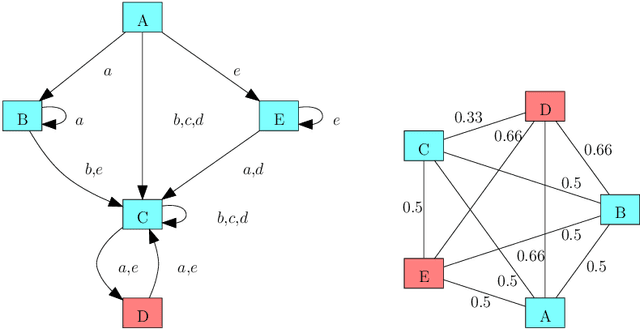
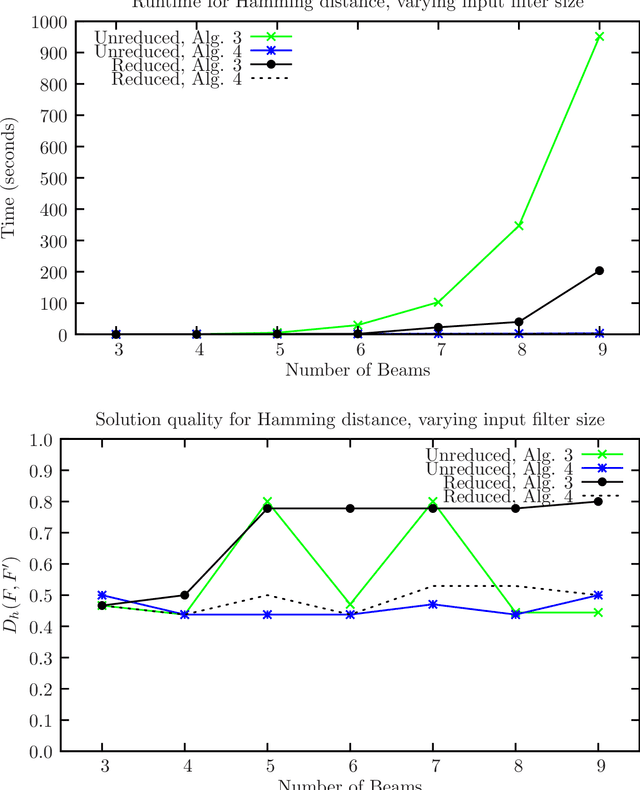
Combinatorial filters have been the subject of increasing interest from the robotics community in recent years. This paper considers automatic reduction of combinatorial filters to a given size, even if that reduction necessitates changes to the filter's behavior. We introduce an algorithmic problem called improper filter reduction, in which the input is a combinatorial filter F along with an integer k representing the target size. The output is another combinatorial filter F' with at most k states, such that the difference in behavior between F and F' is minimal. We present two metrics for measuring the distance between pairs of filters, describe dynamic programming algorithms for computing these distances, and show that improper filter reduction is NP-hard under these metrics. We then describe two heuristic algorithms for improper filter reduction, one greedy sequential approach, and one randomized global approach based on prior work on weighted improper graph coloring. We have implemented these algorithms and analyze the results of three sets of experiments.